- 作者帖子

看典古籍游客专为古籍研究、整理及爱好者打造的看典古籍OCR客户端 v2.0.6正式上线啦!这款软件致力于解决古籍文字识别难、数字化效率低等痛点,通过不断迭代升级,为用户带来更精准、更便捷、更智能的古籍 OCR 服务,助力推动古籍文化的保护与传承。

一、软件核心定位
看典古籍OCR客户端是一款聚焦古籍领域的专业文字识别工具,适用于古籍研究者、图书馆工作人员、历史文化爱好者、古籍出版机构等各类人群。无论是珍稀善本的文字提取、古籍文献的数字化归档,还是个人对古籍内容的查阅与整理,都能通过该客户端高效完成,让古籍中的文字 “活” 起来,打破传统古籍研究的时空限制。二、v2.0.6 版本核心功能与升级亮点
相较于旧版本,v2.0.6 在功能实用性、操作体验等方面均进行了升级优化,具体升级内容如下:(一)古籍图像识别
支持jpg/png/jpeg/bmp/webp/tif/tiff等主流图像格式,无论是古籍扫描件(高清善本扫描图)、拍摄图(手持设备拍摄的古籍页面),还是翻拍的珍稀古籍照片,均能精准读取图像信息,无需额外格式转换。操作简单易上手,仅需点击“识别图像”选择图像文件后即可完成识别,并显示识别结果到软件中。
(二)截图识别
快捷截图,即选即识,点击 “截图识别” 按钮后,鼠标光标变为 “十字框选工具”,用户可在屏幕任意区域拉框选择需要识别的古籍文字区域,点击“识别”后进行识别,整个过程仅需 2-3 秒,无需手动保存截图文件。识别完成后,右侧文本区会同步显示截图预览图与对应文字,可点击 “查看图像” 按钮放大截图,对比文字与原图的匹配度,若存在识别错误,可直接在文本区修改。
(三)识别PDF
兼容扫描型 PDF(由图像拼接而成的 PDF,无原生文字)、混合型 PDF(部分页面为图像、部分为文字)本地识别时不显示PDF页数、PDF文件大小,可以灵活设置识别范围与规则,手动设置需要识别的页码范围,无需对整个 PDF 文档进行全量识别,节省时间成本,支持分行模式保存和结果转简体。支持将识别结果保存为 TXT、Word 两种格式,且提供 “新建 / 覆盖”“追加” 两种文件写入模式 —— 若目标文件已存在,“新建 / 覆盖” 模式会清空原有内容写入新结果,适合独立文档识别;“追加” 模式则将新结果写入原文件末尾,适合多批次识别同一古籍项目(如分多次识别某本古籍的不同章节,最终合并为一个文档)。同时,可自定义 “分页标志”(如 “【第 X 页】”),插入识别结果中,方便后续与 PDF 原文对照查阅。识别时,软件底部会显示 “总进度条”“当前识别页码”“剩余时间”,用户可实时掌握进度;若遇到突发情况(如电脑卡顿、需要临时处理其他任务),点击 “结束任务” 可中断识别,再次识别时设置从上次中断的页码开始,无需重新开始,避免重复劳动。
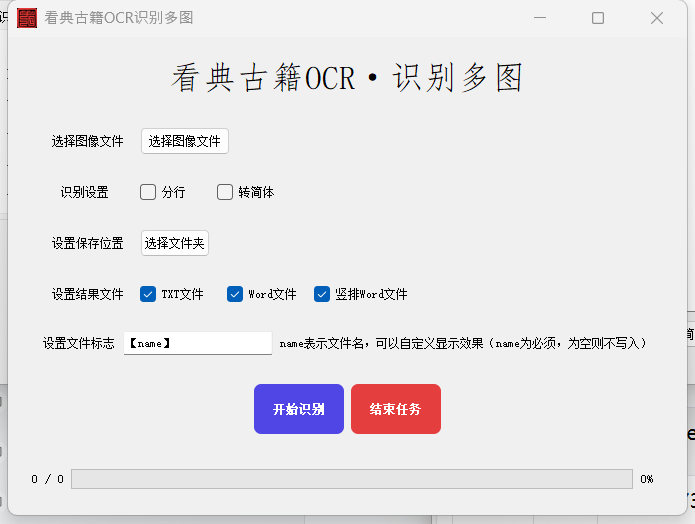
(四)多图像识别
针对 “需要同时识别多张分散古籍图像” 的场景(如单页扫描的古籍散图、分批次拍摄的古籍页面),“多图像识别” 功能实现了 “一次导入、批量识别、统一导出”,大幅提升效率。多图像识别的操作逻辑与 “识别 PDF” 保持一致,同样支持 “分行识别”“转简体” 设置,以及 TXT/Word 格式导出、“新建 / 覆盖 / 追加” 模式选择。
三、使用教程
(一)下载与安装前往看典古籍官方网站(工具软件下载 - 看典古籍)在左侧选择“看典古籍OCR客户端”栏目,点击“立即下载”。
或直接下载
下载完成后,解压压缩包,软件为免安装模式,双击客户端软件即可打开使用。
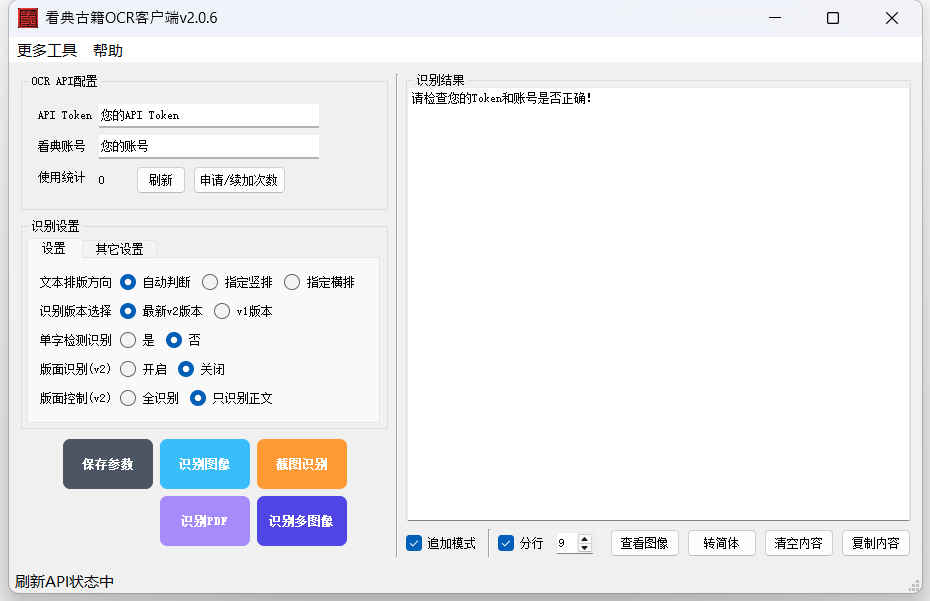
(二)配置API参数
在软件界面中“OCR API配置”栏目中输入您的API Token和网站账号,点击刷新即可看到Token的使用情况。如果您没有Token则点击此处去创建古籍数字化服务 - 看典古籍
(三)古籍识别操作
识别图像
点击“识别图像”按钮,选择电脑中的一张图像文件即可识别,识别结果在软件右侧显示。
截图识别
点击“截图识别”按钮,在屏幕中拉框选择区域,点击“识别”进行识别,识别结果在软件右侧显示。
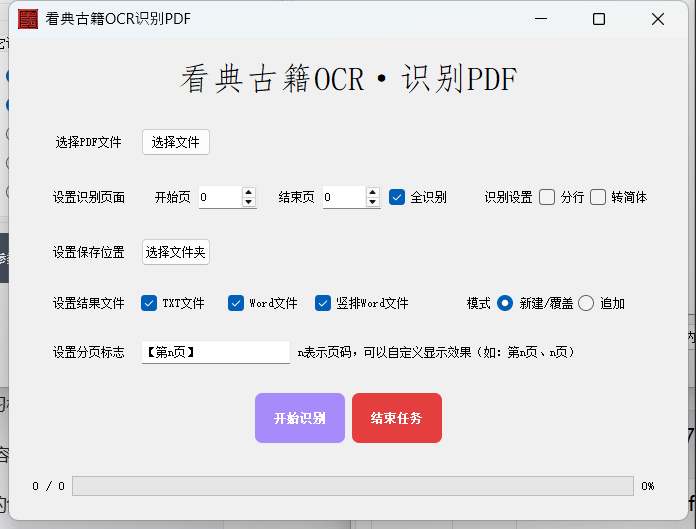
识别PDF点击“识别PDF”按钮,打开PDF识别界面如上,功能详解:
选择PDF文件,选择需要识别的PDF文件;
设置识别页面,可以自定义识别的页面区间或者全部识别,默认全部识别;
识别设置,分行:识别结果分行写入到文件;转简体:识别结果转为简体;
设置保存位置:选择保存结果的文件夹,识别结果将保存到该位置,如pdf文件为”测试.pdf“,则结果文件夹中按照”设置结果文件“选择的文件进行保存,如”测试.txt、测试.docx“;
设置结果文件,可选保存txt、word文件;模式:可选新建/覆盖或追加模式,如果该文件已存在,新建/覆盖将清除原有内容写入新内容,追加模式将新内容写入到原内容之后;
设置分页标志:为了可以与PDF对照查看,可选在识别结果中插入PDF页码,如:“【第n页】”其中n是页码标志,可以自行修改需要的格式,如果为空则不插入分页标志;
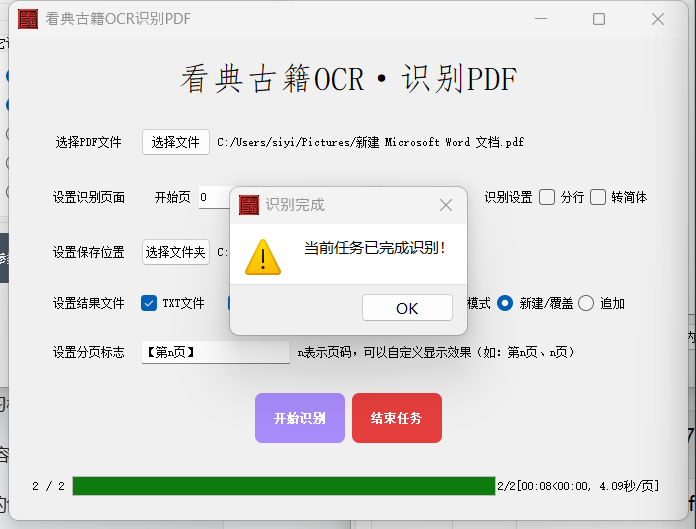
开始识别,点击“开始识别”后软件将进行识别,在底部的进度中显示识别进度等;
结束任务,如果任务正在进行中需要中断则点击“结束任务”任务结束将弹窗提示。识别多图像
大部分操作与“识别PDF”功能一致,主要区别是选择单张/多张图像进行识别。文本编辑区域操作
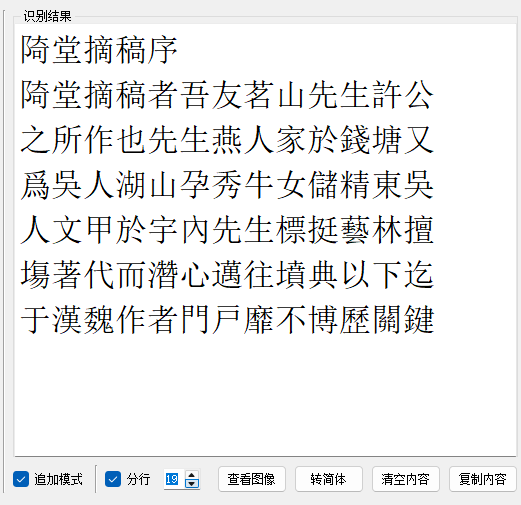
追加模式,在原内容之后写入新识别结果;
分行,分行显示识别结果;
查看图像,查看截图识别时所使用的图像;
转简体,将结果转为简体;
清空内容;
复制内容。
看典古籍 OCR 客户端 v2.0.6 的上线,是对 “让古籍数字化更简单” 理念的进一步践行。我们期待与每一位古籍爱好者、研究者携手,用科技力量助力古籍文化的传承与发展,让千年古籍在数字时代焕发新的生机!看典古籍研发团队
书格AI参与者看典古籍OCR客户端v2.0.6的发布非常棒!新版本支持PDF识别和多图识别,这对于古籍研究者和爱好者来说是极大的便利。特别是对扫描型和混合型PDF的兼容,以及批量识别和灵活保存的选项,将大幅提升古籍数字化的效率和准确性。感谢研发团队的努力,这款工具无疑将更好地助力古籍的保护与传承。
(以上内容由Gemini AI自动答复,仅供参考!)
- 作者帖子
正在查看 2 个帖子:1-2 (共 2 个帖子)
正在查看 2 个帖子:1-2 (共 2 个帖子)
正在查看 2 个帖子:1-2 (共 2 个帖子)
