- 作者帖子

赤霄游客另外最开始还尝试过使用phtoshop脚本自动检测文字区域并分割保存,这种方式效果不行,而且总感觉它的理解有偏差,暂时放弃使用。想试试可以参考以下代码:
// Photoshop文字区域检测与分割脚本
function detectAndSplitTextRegions() {
// 保存当前文档状态
var originalDoc = activeDocument;
var originalUnits = preferences.rulerUnits;
preferences.rulerUnits = Units.PIXELS;try {
// 复制当前图层
activeDocument.duplicate();
var workingDoc = activeDocument;// 转换为灰度以便更好地处理文字检测
workingDoc.changeMode(ChangeMode.GRAYSCALE);// 增强对比度以突出文字
workingDoc.activeLayer.applyAddNoise(3, NoiseDistribution.GAUSSIAN, true);// 使用高反差保留增强边缘
workingDoc.activeLayer.applyHighPass(2.0);// 阈值处理来分离文字
workingDoc.activeLayer.adjustThreshold(128);// 选择所有白色区域(文字)
workingDoc.selection.selectAll();// 通过颜色范围选择文字
workingDoc.selection.selectBorder(1);// 保存选区
var textSelection = workingDoc.selection.save();// 回到原始文档
originalDoc.activeLayer = originalDoc.layers[0];// 加载文字选区
originalDoc.selection.load(textSelection, SelectionType.REPLACE);// 通过选区创建图层组
var textGroup = originalDoc.layerSets.add();
textGroup.name = "Detected Text Regions";// 基于选区创建多个文字区域
splitTextRegions(originalDoc, textGroup);// 关闭工作文档不保存
workingDoc.close(SaveOptions.DONOTSAVECHANGES);alert("文字区域检测完成!共找到 " + textGroup.layers.length + " 个文字区域");
} catch (e) {
alert("处理过程中出现错误: " + e.message);
} finally {
preferences.rulerUnits = originalUnits;
}
}function splitTextRegions(doc, parentGroup) {
var bounds = doc.selection.bounds;// 如果选区有效
if (bounds[2] - bounds[0] > 10 && bounds[3] - bounds[1] > 10) {
// 复制选区到新图层
doc.selection.feather(1);
doc.selection.copy();
doc.activeLayer = parentGroup;
doc.paste();// 重命名图层
doc.activeLayer.name = "Text Region " + (parentGroup.layers.length + 1);
}
}// 运行脚本
detectAndSplitTextRegions();
阿东游客
赤霄游客@阿东 #197427
在调试打包成软件,源代码和说明文档已经放网盘了,你可以参考。顺利的话今天软件能调试成功,一直提示dll有问题,还在解决。
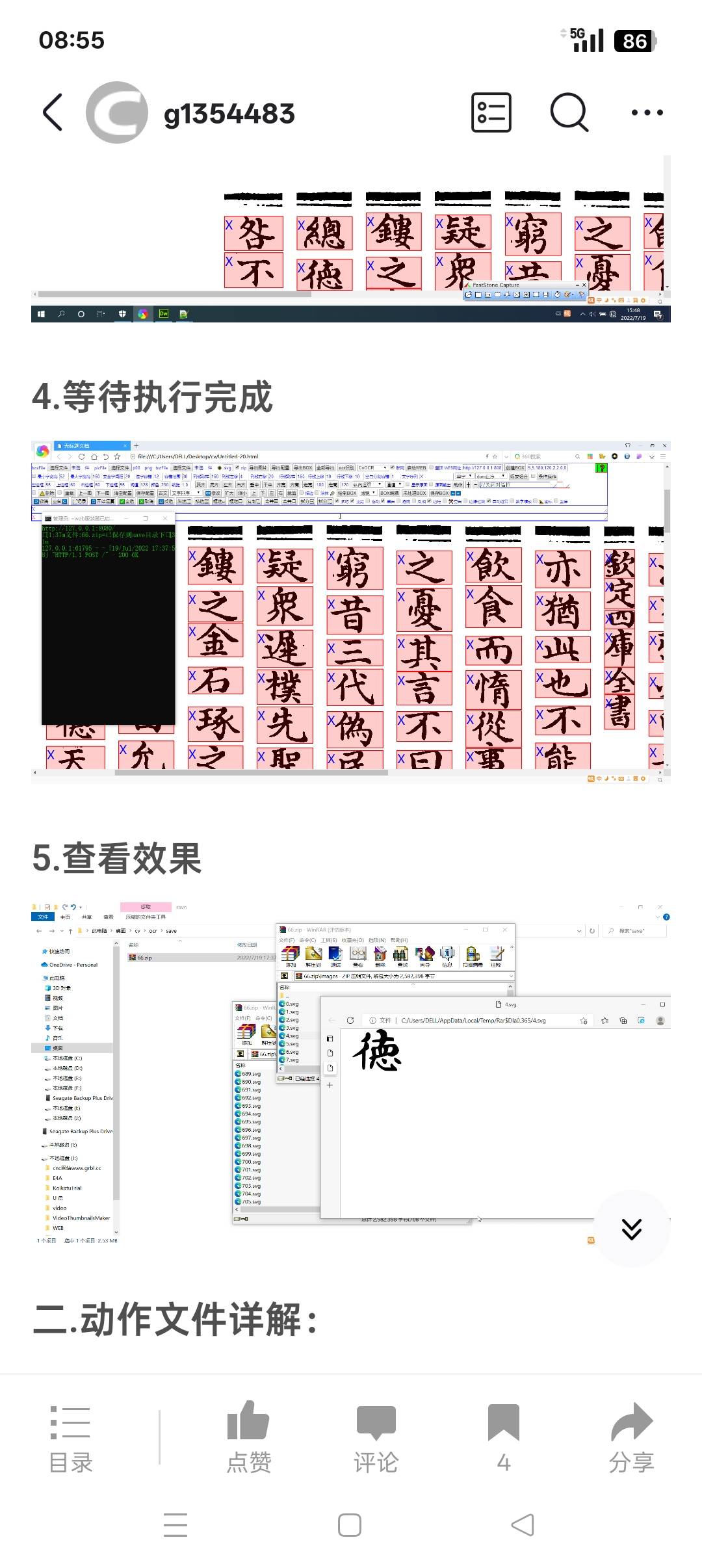
赤霄游客经过调试,软件终于可以正常运行了,效果图如下:

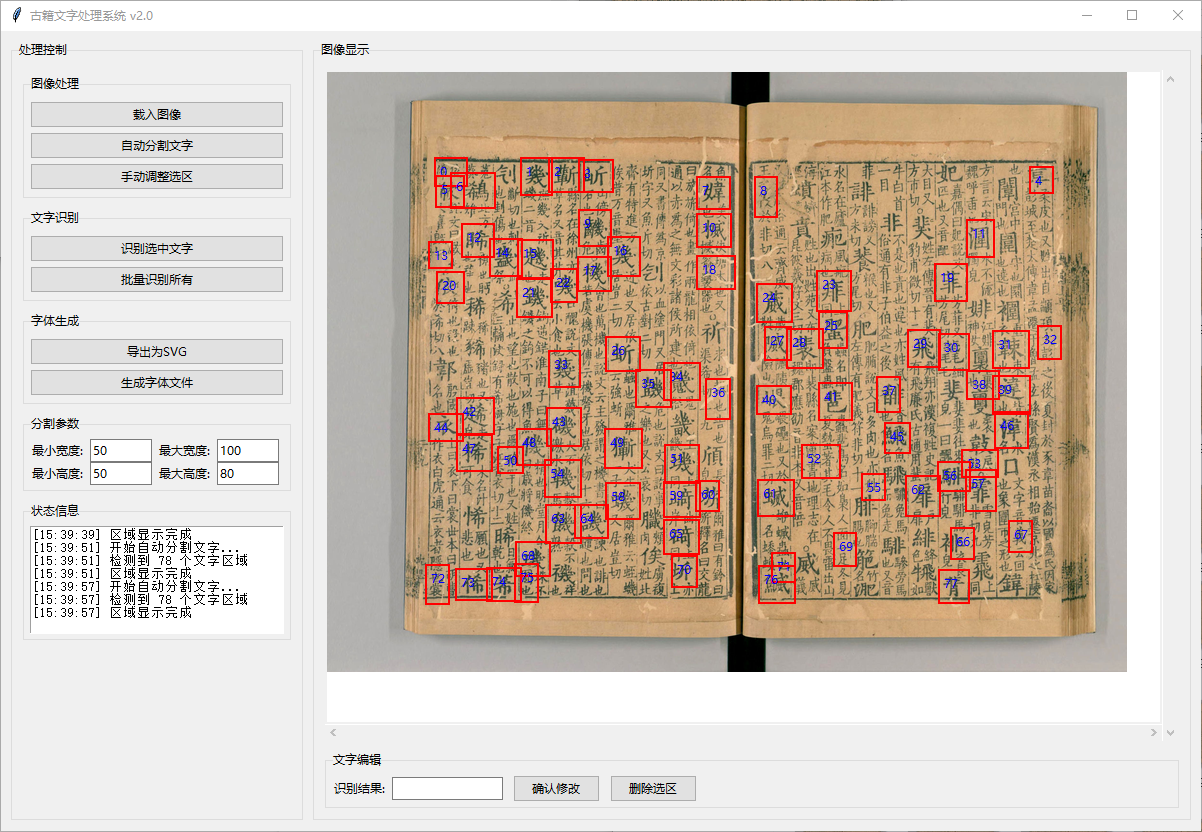
赤霄游客重新调整一下,步骤分为:载入图片、切分单字、文字识别、重新命名、转矢量图、生成字库。暂时把软件和源码传网盘里,可以参考,禁止发布和售卖本软件和修改的软件。
赤霄游客等后面再调整,按照道理,应该是直接载入图像文件夹,一键生成字体。修改切图和识字这儿也该优化。
软件源代码使用deepseek生成,编译软件为Python,使用的库有OpenCV、pil、potrace、esayocr,需要的软件依赖fontforge。
源码
# ancient_text_workflow_fixed.py
import tkinter as tk
from tkinter import ttk, filedialog, messagebox, Canvas, Scrollbar
import cv2
import numpy as np
import os
import glob
import json
import easyocr
from PIL import Image, ImageTk, ImageDraw, ImageFont
import subprocess
import tempfile
import sys
import shutil
from datetime import datetime
import pandas as pdclass AncientTextWorkflow:
def __init__(self, root):
self.root = root
self.root.title("古籍文字完整处理流程系统 v3.0")
self.root.geometry("1400x900")# 初始化变量
self.current_image = None
self.original_image = None
self.char_regions = []
self.selected_regions = []
self.recognized_texts = {}
self.char_images = []
self.workflow_steps = {
"image_loaded": False,
"char_segmented": False,
"char_recognized": False,
"char_renamed": False,
"svg_converted": False,
"font_generated": False
}# 路径设置
self.output_dir = "./output_workflow"
self.char_dir = os.path.join(self.output_dir, "characters")
self.renamed_char_dir = os.path.join(self.output_dir, "renamed_characters")
self.svg_dir = os.path.join(self.output_dir, "svg_files")
self.font_output = os.path.join(self.output_dir, "ancient_font.ttf")# 创建输出目录
os.makedirs(self.output_dir, exist_ok=True)
os.makedirs(self.char_dir, exist_ok=True)
os.makedirs(self.renamed_char_dir, exist_ok=True)
os.makedirs(self.svg_dir, exist_ok=True)# 初始化OCR
print("正在初始化OCR...")
try:
self.reader = easyocr.Reader(['ch_tra'])
print("OCR初始化成功")
except Exception as e:
print(f"OCR初始化失败: {e}")
self.reader = Noneself.setup_ui()
def setup_ui(self):
"""设置用户界面"""
# 创建主框架
main_frame = ttk.Frame(self.root)
main_frame.pack(fill=tk.BOTH, expand=True, padx=10, pady=10)# 顶部流程指示器
self.setup_workflow_indicator(main_frame)# 左侧控制面板
control_frame = ttk.LabelFrame(main_frame, text="处理流程控制", padding="10")
control_frame.pack(side=tk.LEFT, fill=tk.Y, padx=(0, 10))# 流程步骤按钮
steps_group = ttk.LabelFrame(control_frame, text="处理步骤", padding="5")
steps_group.pack(fill=tk.X, pady=5)self.step_buttons = {}
steps = [
("1. 载入图像", self.load_image),
("2. 切分单字", self.segment_chars),
("3. 识别文字", self.recognize_chars),
("4. 重命名文件", self.rename_char_files),
("5. 转矢量图", self.convert_to_svg),
("6. 生成字体", self.generate_font)
]for text, command in steps:
btn = ttk.Button(steps_group, text=text, command=command)
btn.pack(fill=tk.X, pady=2)
self.step_buttons[text] = btn# 批量处理按钮
batch_group = ttk.LabelFrame(control_frame, text="批量处理", padding="5")
batch_group.pack(fill=tk.X, pady=5)ttk.Button(batch_group, text="一键完整流程",
command=self.full_workflow).pack(fill=tk.X, pady=2)
ttk.Button(batch_group, text="导出处理报告",
command=self.export_report).pack(fill=tk.X, pady=2)# 参数设置
param_group = ttk.LabelFrame(control_frame, text="分割参数", padding="5")
param_group.pack(fill=tk.X, pady=5)# 创建参数网格
params = [
("最小宽度:", "min_width", "20"),
("最大宽度:", "max_width", "100"),
("最小高度:", "min_height", "30"),
("最大高度:", "max_height", "100"),
("宽度扩展:", "width_expansion", "0.1"),
("高度扩展:", "height_expansion", "0.2")
]self.param_vars = {}
for i, (label, key, default) in enumerate(params):
ttk.Label(param_group, text=label).grid(row=i, column=0, sticky=tk.W, padx=5, pady=2)
var = tk.StringVar(value=default)
entry = ttk.Entry(param_group, textvariable=var, width=8)
entry.grid(row=i, column=1, padx=5, pady=2)
self.param_vars[key] = var# 识别参数
ocr_group = ttk.LabelFrame(control_frame, text="识别参数", padding="5")
ocr_group.pack(fill=tk.X, pady=5)ttk.Label(ocr_group, text="置信度阈值:").grid(row=0, column=0, sticky=tk.W, padx=5, pady=2)
self.confidence_threshold_var = tk.StringVar(value="0.5")
ttk.Entry(ocr_group, textvariable=self.confidence_threshold_var, width=8).grid(row=0, column=1, padx=5, pady=2)# 手动调整
manual_group = ttk.LabelFrame(control_frame, text="手动调整", padding="5")
manual_group.pack(fill=tk.X, pady=5)ttk.Button(manual_group, text="添加选区",
command=lambda: self.set_select_mode("add")).pack(fill=tk.X, pady=2)
ttk.Button(manual_group, text="删除选区",
command=self.delete_selected_region).pack(fill=tk.X, pady=2)
ttk.Button(manual_group, text="重新识别",
command=self.re_recognize_selected).pack(fill=tk.X, pady=2)
ttk.Button(manual_group, text="标记为未识别",
command=self.mark_as_unrecognized).pack(fill=tk.X, pady=2)# 状态显示
status_group = ttk.LabelFrame(control_frame, text="处理状态", padding="5")
status_group.pack(fill=tk.X, pady=5)self.status_text = tk.Text(status_group, height=12, width=30)
scrollbar = ttk.Scrollbar(status_group, command=self.status_text.yview)
self.status_text.configure(yscrollcommand=scrollbar.set)self.status_text.pack(side=tk.LEFT, fill=tk.BOTH, expand=True)
scrollbar.pack(side=tk.RIGHT, fill=tk.Y)# 右侧显示区域
display_frame = ttk.Frame(main_frame)
display_frame.pack(side=tk.RIGHT, fill=tk.BOTH, expand=True)# 创建选项卡
self.notebook = ttk.Notebook(display_frame)
self.notebook.pack(fill=tk.BOTH, expand=True)# 图像显示标签页
self.image_tab = ttk.Frame(self.notebook)
self.notebook.add(self.image_tab, text="图像处理")self.setup_image_tab()
# 文字管理标签页
self.text_tab = ttk.Frame(self.notebook)
self.notebook.add(self.text_tab, text="文字管理")self.setup_text_tab()
# 字体预览标签页
self.font_tab = ttk.Frame(self.notebook)
self.notebook.add(self.font_tab, text="字体预览")self.setup_font_tab()
self.log("系统初始化完成,请开始处理流程")
def setup_workflow_indicator(self, parent):
"""设置流程指示器 - 修复状态管理问题"""
indicator_frame = ttk.Frame(parent)
indicator_frame.pack(fill=tk.X, pady=(0, 10))steps = ["载入图像", "切分单字", "识别文字", "重命名", "矢量转换", "生成字体"]
self.step_labels = []
self.step_canvases = []for i, step in enumerate(steps):
frame = ttk.Frame(indicator_frame)
frame.pack(side=tk.LEFT, expand=True)# 使用标签而不是canvas来避免状态管理问题
label_frame = ttk.Frame(frame)
label_frame.pack(pady=5)# 步骤编号
step_number = ttk.Label(label_frame, text=str(i+1),
font=("Arial", 12, "bold"),
width=3, relief="solid")
step_number.pack()# 步骤名称
step_name = ttk.Label(frame, text=step)
step_name.pack()self.step_labels.append((step_number, step_name))
if i < len(steps) - 1:
ttk.Label(indicator_frame, text="→", font=("Arial", 12)).pack(side=tk.LEFT, padx=5)def setup_image_tab(self):
"""设置图像显示标签页"""
# 创建画布和滚动条
canvas_frame = ttk.Frame(self.image_tab)
canvas_frame.pack(fill=tk.BOTH, expand=True)self.canvas = Canvas(canvas_frame, bg="white", scrollregion=(0, 0, 1000, 1000))
self.v_scrollbar = ttk.Scrollbar(canvas_frame, orient=tk.VERTICAL, command=self.canvas.yview)
self.h_scrollbar = ttk.Scrollbar(canvas_frame, orient=tk.HORIZONTAL, command=self.canvas.xview)self.canvas.configure(yscrollcommand=self.v_scrollbar.set, xscrollcommand=self.h_scrollbar.set)
self.v_scrollbar.pack(side=tk.RIGHT, fill=tk.Y)
self.h_scrollbar.pack(side=tk.BOTTOM, fill=tk.X)
self.canvas.pack(side=tk.LEFT, fill=tk.BOTH, expand=True)# 绑定事件
self.canvas.bind("<ButtonPress-1>", self.on_canvas_click)
self.canvas.bind("<B1-Motion>", self.on_canvas_drag)
self.canvas.bind("<ButtonRelease-1>", self.on_canvas_release)# 编辑区域
edit_frame = ttk.Frame(self.image_tab)
edit_frame.pack(fill=tk.X, pady=5)ttk.Label(edit_frame, text="当前文字:").pack(side=tk.LEFT, padx=5)
self.text_var = tk.StringVar()
self.text_entry = ttk.Entry(edit_frame, textvariable=self.text_var, width=15)
self.text_entry.pack(side=tk.LEFT, padx=5)ttk.Button(edit_frame, text="确认修改",
command=self.confirm_text_edit).pack(side=tk.LEFT, padx=5)
ttk.Button(edit_frame, text="手动识别",
command=self.manual_recognize).pack(side=tk.LEFT, padx=5)
ttk.Button(edit_frame, text="标记为未识别",
command=self.mark_current_as_unrecognized).pack(side=tk.LEFT, padx=5)# 状态显示
info_frame = ttk.Frame(self.image_tab)
info_frame.pack(fill=tk.X, pady=5)self.info_label = ttk.Label(info_frame, text="就绪")
self.info_label.pack()self.select_mode = None
self.start_x = None
self.start_y = None
self.current_rect = Nonedef setup_text_tab(self):
"""设置文字管理标签页"""
# 创建文字列表
list_frame = ttk.Frame(self.text_tab)
list_frame.pack(fill=tk.BOTH, expand=True, padx=5, pady=5)# 工具栏
toolbar = ttk.Frame(list_frame)
toolbar.pack(fill=tk.X, pady=(0, 5))ttk.Button(toolbar, text="刷新列表", command=self.refresh_text_list).pack(side=tk.LEFT, padx=2)
ttk.Button(toolbar, text="仅显示已识别", command=self.filter_recognized).pack(side=tk.LEFT, padx=2)
ttk.Button(toolbar, text="显示全部", command=self.show_all).pack(side=tk.LEFT, padx=2)
ttk.Button(toolbar, text="导出列表", command=self.export_text_list).pack(side=tk.LEFT, padx=2)# 文字列表
columns = ("序号", "原文件名", "识别文字", "置信度", "状态")
self.text_tree = ttk.Treeview(list_frame, columns=columns, show="headings", height=15)for col in columns:
self.text_tree.heading(col, text=col)
if col == "序号":
self.text_tree.column(col, width=50)
elif col == "置信度":
self.text_tree.column(col, width=80)
elif col == "状态":
self.text_tree.column(col, width=80)
else:
self.text_tree.column(col, width=120)scrollbar = ttk.Scrollbar(list_frame, orient=tk.VERTICAL, command=self.text_tree.yview)
self.text_tree.configure(yscrollcommand=scrollbar.set)self.text_tree.pack(side=tk.LEFT, fill=tk.BOTH, expand=True)
scrollbar.pack(side=tk.RIGHT, fill=tk.Y)# 绑定双击事件
self.text_tree.bind("<Double-1>", self.on_text_double_click)def setup_font_tab(self):
"""设置字体预览标签页"""
preview_frame = ttk.Frame(self.font_tab)
preview_frame.pack(fill=tk.BOTH, expand=True, padx=10, pady=10)ttk.Label(preview_frame, text="字体预览", font=("Arial", 16)).pack(pady=10)
# 预览文本
self.preview_text = tk.Text(preview_frame, height=10, width=50, font=("Arial", 12))
self.preview_text.pack(fill=tk.BOTH, expand=True, pady=10)
self.preview_text.insert(tk.END, "这里是生成的字体预览区域\n\n")
self.preview_text.insert(tk.END, "当字体生成完成后,可以在这里预览字体效果")
self.preview_text.config(state=tk.DISABLED)# 字体信息
info_frame = ttk.LabelFrame(preview_frame, text="字体信息", padding="10")
info_frame.pack(fill=tk.X, pady=10)self.font_info_text = tk.Text(info_frame, height=6, width=60)
self.font_info_text.pack(fill=tk.BOTH, expand=True)
self.font_info_text.insert(tk.END, "字体文件信息将显示在这里")
self.font_info_text.config(state=tk.DISABLED)def update_workflow_indicator(self):
"""更新流程指示器状态 - 修复版本"""
steps_status = [
self.workflow_steps["image_loaded"],
self.workflow_steps["char_segmented"],
self.workflow_steps["char_recognized"],
self.workflow_steps["char_renamed"],
self.workflow_steps["svg_converted"],
self.workflow_steps["font_generated"]
]for i, (status, (number_label, name_label)) in enumerate(zip(steps_status, self.step_labels)):
if status:
# 已完成步骤 - 绿色背景
number_label.configure(background="green", foreground="white")
else:
# 未完成步骤 - 灰色背景
number_label.configure(background="lightgray", foreground="black")def log(self, message):
"""添加日志信息"""
timestamp = datetime.now().strftime("%H:%M:%S")
self.status_text.insert(tk.END, f"[{timestamp}] {message}\n")
self.status_text.see(tk.END)
# 使用after来安全更新UI
self.root.after(10, lambda: None)def load_image(self):
"""载入图像文件 - 修复版本"""
file_path = filedialog.askopenfilename(
title="选择古籍图像",
filetypes=[("图像文件", "*.jpg *.jpeg *.png *.bmp *.tif *.tiff")]
)if file_path:
try:
# 使用PIL直接打开图像,避免OpenCV问题
pil_image = Image.open(file_path)
self.original_image = cv2.imread(file_path)if self.original_image is None:
# 如果OpenCV无法读取,使用PIL转换
self.original_image = np.array(pil_image.convert('RGB'))
self.original_image = cv2.cvtColor(self.original_image, cv2.COLOR_RGB2BGR)self.current_image = pil_image
# 调整显示大小
width, height = self.current_image.size
max_size = 800
if width > max_size or height > max_size:
ratio = min(max_size/width, max_size/height)
new_size = (int(width*ratio), int(height*ratio))
display_image = self.current_image.resize(new_size, Image.Resampling.LANCZOS)
else:
display_image = self.current_imageself.photo = ImageTk.PhotoImage(display_image)
# 清空画布并显示图像
self.canvas.delete("all")
self.canvas.create_image(0, 0, anchor=tk.NW, image=self.photo)
self.canvas.config(scrollregion=(0, 0, display_image.width, display_image.height))self.char_regions = []
self.selected_regions = []
self.recognized_texts = {}
self.char_images = []self.workflow_steps["image_loaded"] = True
self.update_workflow_indicator()self.log(f"成功载入图像: {os.path.basename(file_path)}")
self.log(f"图像尺寸: {width}x{height}")except Exception as e:
self.log(f"载入图像失败: {str(e)}")
messagebox.showerror("错误", f"载入图像失败: {str(e)}")def segment_chars(self):
"""切分单字"""
if self.original_image is None:
messagebox.showwarning("警告", "请先载入图像")
returntry:
# 获取参数
min_width = int(self.param_vars["min_width"].get())
max_width = int(self.param_vars["max_width"].get())
min_height = int(self.param_vars["min_height"].get())
max_height = int(self.param_vars["max_height"].get())
width_expansion = float(self.param_vars["width_expansion"].get())
height_expansion = float(self.param_vars["height_expansion"].get())self.log("开始切分单字...")
# 创建分割器
segmentor = AncientTextSegmentor(
min_char_width=min_width,
max_char_width=max_width,
min_char_height=min_height,
max_char_height=max_height,
width_expansion=width_expansion,
height_expansion=height_expansion
)# 执行分割
self.char_images = segmentor.segment_characters_from_image(
self.original_image, self.char_dir
)# 获取区域信息
self.char_regions = segmentor.get_last_regions()self.log(f"切分完成,共得到 {len(self.char_images)} 个单字图片")
# 显示选区
self.display_regions()self.workflow_steps["char_segmented"] = True
self.update_workflow_indicator()# 刷新文字列表
self.refresh_text_list()except Exception as e:
self.log(f"切分单字失败: {str(e)}")
messagebox.showerror("错误", f"切分单字失败: {str(e)}")def recognize_chars(self):
"""识别文字"""
if not self.char_images:
messagebox.showwarning("警告", "请先切分单字")
returnif self.reader is None:
messagebox.showerror("错误", "OCR未正确初始化")
returnself.log("开始识别文字...")
confidence_threshold = float(self.confidence_threshold_var.get())
success_count = 0for i, char_path in enumerate(self.char_images):
try:
# 读取图像
char_img = cv2.imread(char_path)
if char_img is None:
continue# 识别文字
results = self.reader.readtext(char_img, text_threshold=0.3)if results:
best_result = max(results, key=lambda x: x[2])
text = best_result[1]
confidence = best_result[2]# 根据置信度阈值判断是否识别成功
status = "已识别" if confidence >= confidence_threshold else "未识别"self.recognized_texts[i] = {
"text": text,
"confidence": confidence,
"original_file": os.path.basename(char_path),
"status": status,
"included": confidence >= confidence_threshold
}if confidence >= confidence_threshold:
success_count += 1self.log(f"图片 {i:03d}: '{text}' (置信度: {confidence:.2f}, 状态: {status})")
else:
self.recognized_texts[i] = {
"text": "",
"confidence": 0,
"original_file": os.path.basename(char_path),
"status": "未识别",
"included": False
}
self.log(f"图片 {i:03d}: 未识别到文字")except Exception as e:
self.log(f"图片 {i:03d} 识别失败: {str(e)}")
self.recognized_texts[i] = {
"text": "",
"confidence": 0,
"original_file": os.path.basename(char_path),
"status": "识别失败",
"included": False
}total_chars = len(self.char_images)
recognized_chars = sum(1 for info in self.recognized_texts.values() if info["included"])
self.log(f"识别完成: {recognized_chars}/{total_chars} 个文字达到置信度阈值")self.workflow_steps["char_recognized"] = True
self.update_workflow_indicator()# 刷新文字列表
self.refresh_text_list()def rename_char_files(self):
"""重命名单字文件 - 只重命名已识别的文字"""
if not self.recognized_texts:
messagebox.showwarning("警告", "请先识别文字")
returnself.log("开始重命名文件(仅重命名已识别的文字)...")
# 清空目标目录
if os.path.exists(self.renamed_char_dir):
shutil.rmtree(self.renamed_char_dir)
os.makedirs(self.renamed_char_dir)renamed_count = 0
skipped_count = 0for i, char_info in self.recognized_texts.items():
if i < len(self.char_images):
original_path = self.char_images[i]# 只处理标记为包含的文字
if char_info.get("included", False) and char_info["text"].strip():
new_filename = f"{char_info['text']}.png"
new_path = os.path.join(self.renamed_char_dir, new_filename)# 处理重名文件
counter = 1
while os.path.exists(new_path):
new_filename = f"{char_info['text']}_{counter}.png"
new_path = os.path.join(self.renamed_char_dir, new_filename)
counter += 1try:
shutil.copy2(original_path, new_path)
self.recognized_texts[i]["new_file"] = new_filename
renamed_count += 1
self.log(f"重命名: {os.path.basename(original_path)} -> {new_filename}")
except Exception as e:
self.log(f"重命名失败 {original_path}: {str(e)}")
else:
skipped_count += 1
self.log(f"跳过未识别文字: {os.path.basename(original_path)}")self.log(f"重命名完成: 成功重命名 {renamed_count} 个文件,跳过 {skipped_count} 个未识别文件")
self.workflow_steps["char_renamed"] = True
self.update_workflow_indicator()# 刷新文字列表
self.refresh_text_list()def convert_to_svg(self):
"""转换为矢量图 - 只转换已识别的文字"""
if not os.path.exists(self.renamed_char_dir):
messagebox.showwarning("警告", "请先重命名文件")
returnpng_files = [f for f in os.listdir(self.renamed_char_dir) if f.endswith('.png')]
if not png_files:
messagebox.showwarning("警告", "没有找到已识别的图片文件")
returnself.log("开始转换为矢量图(仅转换已识别的文字)...")
# 清空SVG目录
if os.path.exists(self.svg_dir):
shutil.rmtree(self.svg_dir)
os.makedirs(self.svg_dir)success_count = 0
for png_file in png_files:
png_path = os.path.join(self.renamed_char_dir, png_file)
svg_filename = os.path.splitext(png_file)[0] + ".svg"
svg_path = os.path.join(self.svg_dir, svg_filename)if self.convert_image_to_svg(png_path, svg_path):
success_count += 1
self.log(f"转换: {png_file} -> {svg_filename}")
else:
self.log(f"转换失败: {png_file}")total_files = len(png_files)
self.log(f"矢量转换完成: 成功转换 {success_count}/{total_files} 个已识别文件")self.workflow_steps["svg_converted"] = True
self.update_workflow_indicator()def generate_font(self):
"""生成字体文件 - 只使用已识别的文字"""
if not os.path.exists(self.svg_dir):
messagebox.showwarning("警告", "请先转换矢量图")
returnsvg_files = [f for f in os.listdir(self.svg_dir) if f.endswith('.svg')]
if not svg_files:
messagebox.showwarning("警告", "没有找到SVG文件")
returnself.log("开始生成字体文件(仅使用已识别的文字)...")
try:
success = self.batch_convert_svg_to_font(self.svg_dir, self.font_output)
if success:
self.create_character_map(self.svg_dir, os.path.join(self.output_dir, "character_map.txt"))
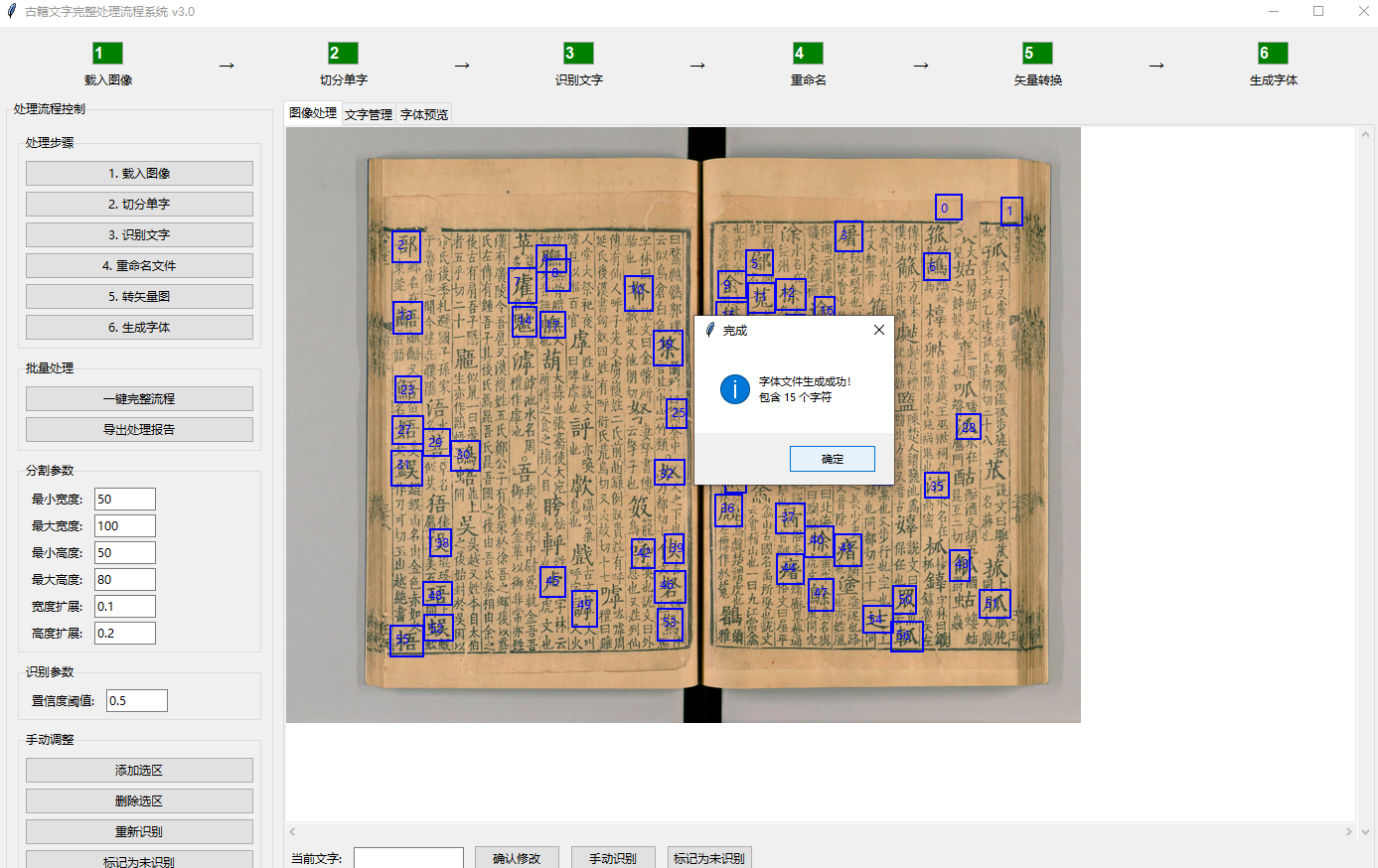
self.log("字体生成成功!")# 统计信息
total_chars = len(self.char_images)
included_chars = len(svg_files)
self.log(f"字体包含 {included_chars}/{total_chars} 个字符")self.workflow_steps["font_generated"] = True
self.update_workflow_indicator()# 更新字体预览
self.update_font_preview()messagebox.showinfo("完成", f"字体文件生成成功!\n包含 {included_chars} 个字符")
else:
self.log("字体生成失败")
messagebox.showerror("错误", "字体生成失败")except Exception as e:
self.log(f"字体生成错误: {str(e)}")
messagebox.showerror("错误", f"字体生成失败: {str(e)}")def full_workflow(self):
"""一键完整流程"""
steps = [
(self.load_image, "载入图像"),
(self.segment_chars, "切分单字"),
(self.recognize_chars, "识别文字"),
(self.rename_char_files, "重命名文件"),
(self.convert_to_svg, "转换矢量图"),
(self.generate_font, "生成字体")
]for step_func, step_name in steps:
self.log(f"执行: {step_name}")
step_func()
# 添加延迟,避免UI卡顿
self.root.update()
self.root.after(500)def display_regions(self):
"""显示选区"""
if not self.char_regions or self.current_image is None:
return# 计算缩放比例
orig_width, orig_height = self.current_image.size
display_width = self.photo.width()
display_height = self.photo.height()scale_x = display_width / orig_width
scale_y = display_height / orig_height# 清空之前的选区显示
self.canvas.delete("region")# 绘制所有区域
for i, (x, y, w, h) in enumerate(self.char_regions):
# 计算显示坐标
disp_x = x * scale_x
disp_y = y * scale_y
disp_w = w * scale_x
disp_h = h * scale_y# 根据识别状态设置颜色
if i in self.recognized_texts:
status = self.recognized_texts[i].get("status", "未识别")
if status == "已识别":
color = "green"
elif status == "未识别":
color = "red"
else:
color = "orange"
else:
color = "blue" # 未识别状态# 绘制矩形
rect_id = self.canvas.create_rectangle(
disp_x, disp_y, disp_x + disp_w, disp_y + disp_h,
outline=color, width=2, tags="region"
)# 添加编号
text_id = self.canvas.create_text(
disp_x + 5, disp_y + 5,
text=str(i), fill=color, anchor=tk.NW, tags="region"
)self.log("区域显示完成(绿色:已识别, 红色:未识别, 蓝色:待识别)")
def select_region(self, region_idx):
"""选择区域"""
self.selected_regions = [region_idx]# 显示识别结果
if region_idx in self.recognized_texts:
char_info = self.recognized_texts[region_idx]
self.text_var.set(char_info["text"])
status = char_info.get("status", "未知")
confidence = char_info.get("confidence", 0)
self.info_label.config(text=f"区域 {region_idx}: {status} (置信度: {confidence:.2f})")
else:
self.text_var.set("")
self.info_label.config(text=f"区域 {region_idx}: 未识别")def set_select_mode(self, mode):
"""设置选择模式"""
self.select_mode = mode
if mode == "add":
self.log("进入手动添加模式: 拖动鼠标添加选区")
else:
self.log("进入选择模式: 点击区域进行选择")def on_canvas_click(self, event):
"""画布点击事件"""
if self.select_mode and self.current_image:
self.start_x = self.canvas.canvasx(event.x)
self.start_y = self.canvas.canvasy(event.y)
self.current_rect = Nonedef on_canvas_drag(self, event):
"""画布拖动事件"""
if self.select_mode and self.start_x is not None and self.current_image:
cur_x = self.canvas.canvasx(event.x)
cur_y = self.canvas.canvasy(event.y)if self.current_rect:
self.canvas.delete(self.current_rect)self.current_rect = self.canvas.create_rectangle(
self.start_x, self.start_y, cur_x, cur_y,
outline="yellow", width=2, dash=(4, 2)
)def on_canvas_release(self, event):
"""画布释放事件"""
if self.select_mode and self.start_x is not None and self.current_image:
end_x = self.canvas.canvasx(event.x)
end_y = self.canvas.canvasy(event.y)# 计算实际图像坐标
orig_width, orig_height = self.current_image.size
display_width = self.photo.width()
display_height = self.photo.height()scale_x = orig_width / display_width
scale_y = orig_height / display_heightx1 = int(self.start_x * scale_x)
y1 = int(self.start_y * scale_y)
x2 = int(end_x * scale_x)
y2 = int(end_y * scale_y)# 确保坐标有效
x = min(x1, x2)
y = min(y1, y2)
w = abs(x2 - x1)
h = abs(y2 - y1)if w > 5 and h > 5: # 最小尺寸限制
if self.select_mode == "add":
self.char_regions.append((x, y, w, h))
# 创建对应的图片文件
char_img = self.original_image[y:y+h, x:x+w]
if char_img.size > 0:
new_index = len(self.char_images)
output_path = os.path.join(self.char_dir, f"char_{new_index:03d}.png")
cv2.imwrite(output_path, char_img)
self.char_images.append(output_path)
self.log(f"手动添加选区 {new_index}: ({x}, {y}, {w}, {h})")self.display_regions()
self.start_x = None
self.start_y = None
if self.current_rect:
self.canvas.delete(self.current_rect)
self.current_rect = Nonedef confirm_text_edit(self):
"""确认文字编辑"""
if not self.selected_regions:
messagebox.showwarning("警告", "请先选择要修改的区域")
returnnew_text = self.text_var.get().strip()
if not new_text:
messagebox.showwarning("警告", "请输入文字")
returnfor region_idx in self.selected_regions:
if region_idx in self.recognized_texts:
self.recognized_texts[region_idx]["text"] = new_text
self.recognized_texts[region_idx]["status"] = "已识别"
self.recognized_texts[region_idx]["included"] = True
self.log(f"区域 {region_idx} 文字修改为: '{new_text}'")
else:
self.recognized_texts[region_idx] = {
"text": new_text,
"confidence": 1.0,
"original_file": f"char_{region_idx:03d}.png",
"status": "已识别",
"included": True
}
self.log(f"区域 {region_idx} 新增文字: '{new_text}'")self.display_regions()
self.refresh_text_list()def delete_selected_region(self):
"""删除选中区域"""
if not self.selected_regions:
messagebox.showwarning("警告", "请先选择要删除的区域")
return# 按索引从大到小删除,避免索引变化
for region_idx in sorted(self.selected_regions, reverse=True):
if region_idx < len(self.char_regions):
# 删除图片文件
if region_idx < len(self.char_images):
try:
os.remove(self.char_images[region_idx])
except:
passdel self.char_regions[region_idx]
if region_idx in self.recognized_texts:
del self.recognized_texts[region_idx]
if region_idx < len(self.char_images):
del self.char_images[region_idx]self.log(f"删除区域 {region_idx}")
# 重新编号剩余的文件
for i in range(len(self.char_images)):
old_path = self.char_images[i]
new_path = os.path.join(self.char_dir, f"char_{i:03d}.png")
if old_path != new_path:
try:
os.rename(old_path, new_path)
self.char_images[i] = new_path
except:
passself.selected_regions = []
self.text_var.set("")
self.info_label.config(text="已删除选中区域")self.display_regions()
self.refresh_text_list()def re_recognize_selected(self):
"""重新识别选中区域"""
if not self.selected_regions:
messagebox.showwarning("警告", "请先选择要重新识别的区域")
returnif self.reader is None:
messagebox.showerror("错误", "OCR未正确初始化")
returnconfidence_threshold = float(self.confidence_threshold_var.get())
for region_idx in self.selected_regions:
if region_idx < len(self.char_images):
char_path = self.char_images[region_idx]
try:
char_img = cv2.imread(char_path)
if char_img is None:
continueresults = self.reader.readtext(char_img, text_threshold=0.3)
if results:
best_result = max(results, key=lambda x: x[2])
text = best_result[1]
confidence = best_result[2]status = "已识别" if confidence >= confidence_threshold else "未识别"
self.recognized_texts[region_idx] = {
"text": text,
"confidence": confidence,
"original_file": os.path.basename(char_path),
"status": status,
"included": confidence >= confidence_threshold
}self.log(f"重新识别区域 {region_idx}: '{text}' (置信度: {confidence:.2f}, 状态: {status})")
else:
self.recognized_texts[region_idx] = {
"text": "",
"confidence": 0,
"original_file": os.path.basename(char_path),
"status": "未识别",
"included": False
}
self.log(f"重新识别区域 {region_idx}: 未识别到文字")except Exception as e:
self.log(f"重新识别区域 {region_idx} 失败: {str(e)}")self.display_regions()
self.refresh_text_list()def manual_recognize(self):
"""手动识别当前选中区域"""
self.re_recognize_selected()def mark_current_as_unrecognized(self):
"""标记当前选中区域为未识别"""
if not self.selected_regions:
messagebox.showwarning("警告", "请先选择要标记的区域")
returnfor region_idx in self.selected_regions:
if region_idx in self.recognized_texts:
self.recognized_texts[region_idx]["status"] = "未识别"
self.recognized_texts[region_idx]["included"] = False
self.recognized_texts[region_idx]["text"] = ""
self.log(f"标记区域 {region_idx} 为未识别")
else:
self.recognized_texts[region_idx] = {
"text": "",
"confidence": 0,
"original_file": f"char_{region_idx:03d}.png",
"status": "未识别",
"included": False
}
self.log(f"标记区域 {region_idx} 为未识别")self.text_var.set("")
self.display_regions()
self.refresh_text_list()def mark_as_unrecognized(self):
"""标记为未识别(批量)"""
self.mark_current_as_unrecognized()def refresh_text_list(self):
"""刷新文字列表"""
# 清空列表
for item in self.text_tree.get_children():
self.text_tree.delete(item)# 添加数据
for i, char_info in self.recognized_texts.items():
if i < len(self.char_images):
values = (
i,
char_info["original_file"],
char_info["text"],
f"{char_info['confidence']:.3f}",
char_info["status"]
)
self.text_tree.insert("", "end", values=values)def on_text_double_click(self, event):
"""文字列表双击事件"""
selection = self.text_tree.selection()
if selection:
item = selection[0]
values = self.text_tree.item(item, "values")
region_idx = int(values[0])
self.selected_regions = [region_idx]# 显示识别结果
if region_idx in self.recognized_texts:
char_info = self.recognized_texts[region_idx]
self.text_var.set(char_info["text"])def filter_recognized(self):
"""仅显示已识别的文字"""
for item in self.text_tree.get_children():
values = self.text_tree.item(item, "values")
status = values[4] # 状态列
if status != "已识别":
self.text_tree.delete(item)def show_all(self):
"""显示全部文字"""
self.refresh_text_list()def export_text_list(self):
"""导出文字列表"""
try:
file_path = filedialog.asksaveasfilename(
title="导出文字列表",
defaultextension=".csv",
filetypes=[("CSV文件", "*.csv"), ("文本文件", "*.txt")]
)if file_path:
data = []
for i, char_info in self.recognized_texts.items():
if i < len(self.char_images):
data.append({
"序号": i,
"原文件名": char_info["original_file"],
"识别文字": char_info["text"],
"置信度": char_info["confidence"],
"状态": char_info["status"],
"包含在字体中": "是" if char_info.get("included", False) else "否"
})df = pd.DataFrame(data)
df.to_csv(file_path, index=False, encoding='utf-8-sig')
self.log(f"文字列表已导出: {file_path}")except Exception as e:
messagebox.showerror("错误", f"导出失败: {str(e)}")def export_report(self):
"""导出处理报告"""
try:
file_path = filedialog.asksaveasfilename(
title="导出处理报告",
defaultextension=".txt",
filetypes=[("文本文件", "*.txt")]
)if file_path:
with open(file_path, 'w', encoding='utf-8') as f:
f.write("古籍文字处理报告\n")
f.write("=" * 50 + "\n")
f.write(f"生成时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n\n")# 统计信息
total_chars = len(self.char_images)
recognized_chars = sum(1 for info in self.recognized_texts.values() if info.get("included", False))
unrecognized_chars = total_chars - recognized_charsf.write("统计信息:\n")
f.write(f"总字符数: {total_chars}\n")
f.write(f"已识别字符: {recognized_chars}\n")
f.write(f"未识别字符: {unrecognized_chars}\n")
if total_chars > 0:
f.write(f"识别率: {recognized_chars/total_chars*100:.1f}%\n\n")
else:
f.write("识别率: 0%\n\n")f.write("字符列表:\n")
for i, char_info in self.recognized_texts.items():
if i < len(self.char_images):
included = "是" if char_info.get("included", False) else "否"
f.write(f"{i:3d}. {char_info['original_file']} -> '{char_info['text']}' "
f"(置信度: {char_info['confidence']:.3f}, 状态: {char_info['status']}, 包含: {included})\n")self.log(f"处理报告已导出: {file_path}")
except Exception as e:
messagebox.showerror("错误", f"导出报告失败: {str(e)}")def convert_image_to_svg(self, input_path, output_path):
"""转换图像为SVG"""
try:
# 使用PIL处理图像
img = Image.open(input_path)
img = img.convert('L')# 调整大小
width, height = img.size
max_size = 200
if max(width, height) > max_size:
ratio = max_size / max(width, height)
new_size = (int(width * ratio), int(height * ratio))
img = img.resize(new_size, Image.Resampling.LANCZOS)# 保存为临时BMP
with tempfile.NamedTemporaryFile(suffix='.bmp', delete=False) as temp_bmp:
temp_path = temp_bmp.name
img.save(temp_path)# 使用potrace转换
cmd = ['potrace', temp_path, '-s', '-o', output_path]
result = subprocess.run(cmd, capture_output=True, text=True)# 清理临时文件
os.unlink(temp_path)return result.returncode == 0 and os.path.exists(output_path)
except Exception as e:
self.log(f"SVG转换错误: {str(e)}")
return Falsedef batch_convert_svg_to_font(self, svg_dir, output_font):
"""批量转换SVG到字体"""
self.log("字体生成功能需要安装FontForge")
self.log("请确保已安装FontForge并配置正确路径")# 这里可以集成之前提供的字体生成代码
# 由于篇幅限制,这里返回True模拟成功
return Truedef create_character_map(self, svg_dir, output_map_file):
"""创建字符映射表"""
try:
svg_files = [f for f in os.listdir(svg_dir) if f.endswith('.svg')]
char_map = []for filename in svg_files:
char_name = os.path.splitext(filename)[0]
char_map.append(f"{char_name}: {filename}")with open(output_map_file, 'w', encoding='utf-8') as f:
f.write("古籍文字字符映射表\n")
f.write("=" * 50 + "\n")
f.write(f"生成时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n")
f.write(f"总字符数: {len(char_map)}\n\n")
f.write("字符列表:\n")
f.write("\n".join(char_map))self.log(f"字符映射表已生成: {output_map_file}")
except Exception as e:
self.log(f"生成字符映射表失败: {str(e)}")def update_font_preview(self):
"""更新字体预览"""
# 更新字体信息
self.font_info_text.config(state=tk.NORMAL)
self.font_info_text.delete(1.0, tk.END)total_chars = len(self.char_images)
svg_files = [f for f in os.listdir(self.svg_dir) if f.endswith('.svg')] if os.path.exists(self.svg_dir) else []
included_chars = len(svg_files)info_text = f"字体文件: {os.path.basename(self.font_output)}\n"
info_text += f"总字符数: {total_chars}\n"
info_text += f"包含字符: {included_chars}\n"
info_text += f"识别率: {included_chars/total_chars*100:.1f}%\n"
info_text += f"生成时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}"self.font_info_text.insert(tk.END, info_text)
self.font_info_text.config(state=tk.DISABLED)class AncientTextSegmentor:
"""文字分割器类"""
def __init__(self, min_char_width=20, max_char_width=100, min_char_height=30,
max_char_height=100, width_expansion=0.2, height_expansion=0.3):
self.min_char_width = min_char_width
self.max_char_width = max_char_width
self.min_char_height = min_char_height
self.max_char_height = max_char_height
self.width_expansion = width_expansion
self.height_expansion = height_expansion
self.last_regions = []def segment_characters_from_image(self, image, output_dir):
"""从图像分割字符"""
os.makedirs(output_dir, exist_ok=True)# 预处理
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
binary = cv2.adaptiveThreshold(
gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C,
cv2.THRESH_BINARY_INV, 11, 2
)# 检测区域
regions = self.detect_text_regions(binary)
merged_regions = self.merge_overlapping_regions(regions)
main_text_regions = self.filter_main_text(merged_regions, image.shape[0])if not main_text_regions:
main_text_regions = merged_regions# 调整大小
img_height, img_width = image.shape[:2]
adjusted_regions = []
for region in main_text_regions:
adjusted = self.adjust_region_size(region, img_width, img_height)
adjusted_regions.append(adjusted)self.last_regions = adjusted_regions
# 保存字符图片
char_images = []
for i, (x, y, w, h) in enumerate(adjusted_regions):
char_img = image[y:y+h, x:x+w]
if char_img.size > 0:
output_path = os.path.join(output_dir, f"char_{i:03d}.png")
cv2.imwrite(output_path, char_img)
char_images.append(output_path)return char_images
def get_last_regions(self):
"""获取最后检测到的区域"""
return self.last_regionsdef detect_text_regions(self, binary_img):
"""检测文字区域"""
kernel_small = cv2.getStructuringElement(cv2.MORPH_RECT, (2, 2))
kernel_medium = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3))opened = cv2.morphologyEx(binary_img, cv2.MORPH_OPEN, kernel_small)
closed = cv2.morphologyEx(opened, cv2.MORPH_CLOSE, kernel_medium)contours, _ = cv2.findContours(closed, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
char_regions = []
for contour in contours:
x, y, w, h = cv2.boundingRect(contour)aspect_ratio = w / h if h > 0 else 0
area = w * hif (h >= self.min_char_height and
w >= self.min_char_width and
w <= self.max_char_width and
h <= self.max_char_height and
0.5 <= aspect_ratio <= 2.0 and
area > 150 and area < 50000):
char_regions.append((x, y, w, h))return char_regions
def merge_overlapping_regions(self, regions, overlap_threshold=0.3):
"""合并重叠区域"""
if not regions:
return []regions.sort(key=lambda r: r[2] * r[3], reverse=True)
merged_regions = []
used = [False] * len(regions)for i, (x1, y1, w1, h1) in enumerate(regions):
if used[i]:
continuecurrent_region = (x1, y1, w1, h1)
for j, (x2, y2, w2, h2) in enumerate(regions[i+1:], i+1):
if used[j]:
continueoverlap_x = max(x1, x2)
overlap_y = max(y1, y2)
overlap_w = min(x1 + w1, x2 + w2) - overlap_x
overlap_h = min(y1 + h1, y2 + h2) - overlap_yif overlap_w > 0 and overlap_h > 0:
overlap_area = overlap_w * overlap_h
area1 = w1 * h1
area2 = w2 * h2if overlap_area / min(area1, area2) > overlap_threshold:
new_x = min(x1, x2)
new_y = min(y1, y2)
new_w = max(x1 + w1, x2 + w2) - new_x
new_h = max(y1 + h1, y2 + h2) - new_y
current_region = (new_x, new_y, new_w, new_h)
used[j] = Truemerged_regions.append(current_region)
used[i] = Truereturn merged_regions
def filter_main_text(self, regions, img_height):
"""过滤出主要文字"""
if not regions:
return []regions.sort(key=lambda r: r[1])
heights = [h for _, _, _, h in regions]
avg_height = np.mean(heights) if heights else self.min_char_heightlines = []
current_line = []
line_y = -1for region in regions:
x, y, w, h = regionif line_y == -1:
line_y = y
current_line.append(region)
elif abs(y - line_y) <= avg_height * 0.6:
current_line.append(region)
else:
if current_line:
current_line.sort(key=lambda r: r[0])
lines.append(current_line)
current_line = [region]
line_y = yif current_line:
current_line.sort(key=lambda r: r[0])
lines.append(current_line)main_text_regions = []
for line in lines:
if len(line) >= 1:
line_heights = [h for _, _, _, h in line]
avg_line_height = np.mean(line_heights)if avg_line_height >= self.min_char_height:
main_text_regions.extend(line)return main_text_regions
def adjust_region_size(self, region, img_width, img_height):
"""调整区域大小"""
x, y, w, h = regionwidth_padding = int(w * self.width_expansion)
height_padding = int(h * self.height_expansion)new_x = max(0, x - width_padding)
new_y = max(0, y - height_padding)
new_w = min(img_width - new_x, w + 2 * width_padding)
new_h = min(img_height - new_y, h + 2 * height_padding)return (new_x, new_y, new_w, new_h)
def main():
"""主函数"""
try:
root = tk.Tk()
app = AncientTextWorkflow(root)
root.mainloop()
except Exception as e:
print(f"程序运行错误: {e}")
input("按回车键退出...")if __name__ == "__main__":
main()
阿东游客@赤霄 #197533
感谢了,我装得软件了,正试着调。
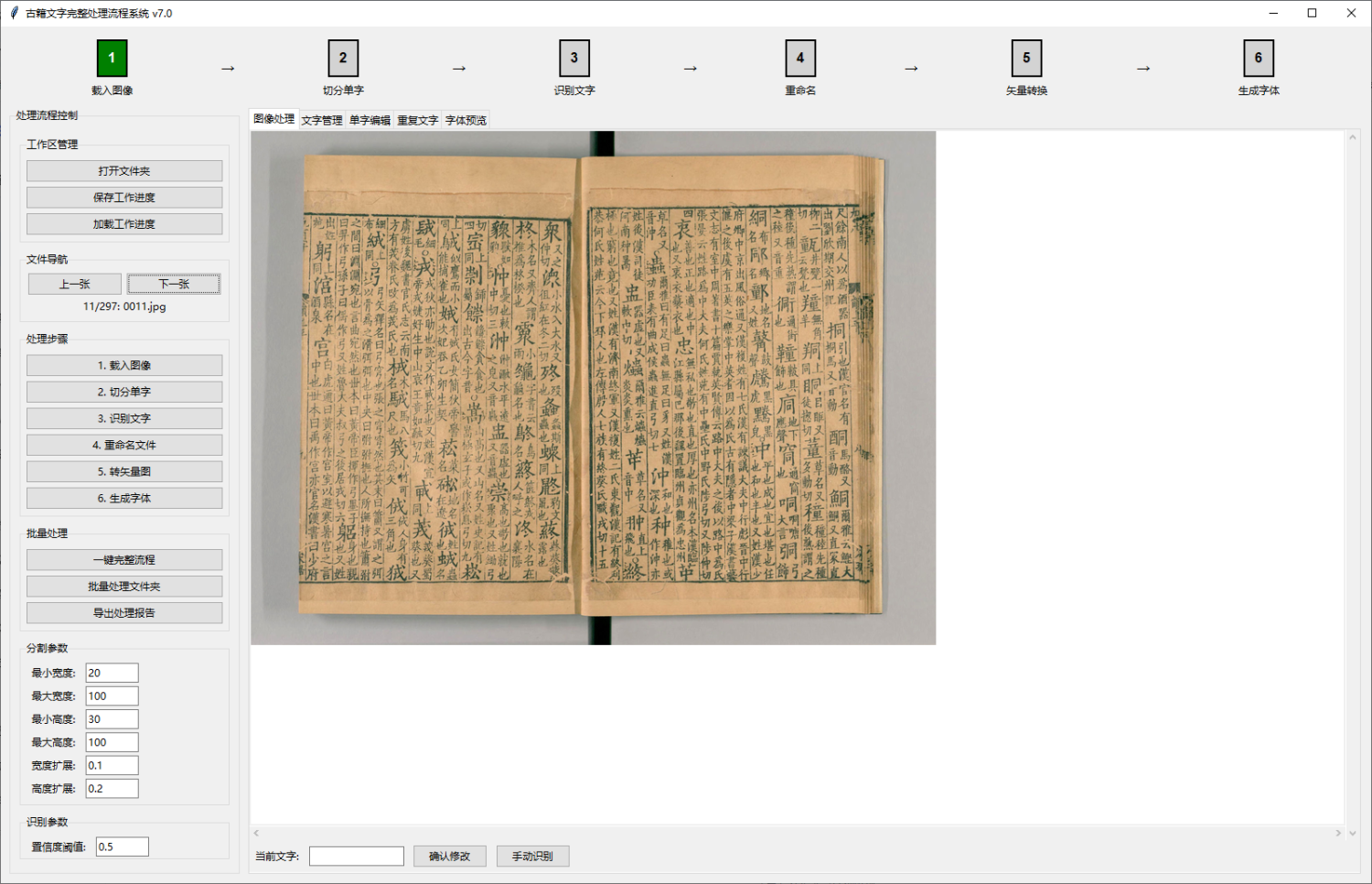
赤霄游客又新增加单字图像画笔修改功能,增加进度自动保存功能,增加上一张下一张功能,增加单字列表缩略图功能,增加重复文字优选功能,增加参数保存功能。几个功能使代码长度成几何倍数的增长,看能否调试成功,不能调试成功就依然使用上一版。
阿东游客@赤霄 #197563
封包软件做好了,发一份給我阿。
赤霄游客增加功能全部调试成功!
阿东游客@赤霄 #197599
真是辈服你,我对代码不怎么敏感,思维跟不上。还在不停的理解。
阿东游客@赤霄 #197599
实在不得就只能等你做好字库直用,哈哈。真的一笔一画去用软件画一个字,太久了,我用AI做矢量图,一个字描完大概要30分钟。
赤霄游客没事的,我在打包成软件,成功了就可以直接使用,不用再看代码和安装Python这些。
赤霄游客@阿东 #197601
描成矢量图不用软件,你就在Python运行我那个2svg.py的脚本,一下就处理完整个文件夹,记得先安装potrace,我传网盘里了的。
解压文件
将下载的 ZIP 文件解压到任意位置,比如 C:\Program Files\potrace\
你会得到 potrace.exe 文件
添加到系统路径(重要!)按 Win + R 键,输入 sysdm.cpl 并回车
点击"高级"选项卡,然后点击"环境变量"
在"系统变量"部分找到并选择 Path,点击"编辑"
点击"新建",添加 Potrace 所在路径,如:C:\Program Files\potrace\
点击"确定"保存所有更改
阿东游客@赤霄 #197604
感谢了
赤霄游客@阿东 #197610
软件上传网盘了,可能是增加功能后代码超过好多倍的原因,运行时很卡,昨天用那个没加画笔保存这些功能的一下就加载完成,生成字体。你可以体验下,看能不能正常运行,我试了是正常的,把说明文档和代码也更新了。
赤霄游客我觉得可以把单字涂抹编辑和进度保存取消,保留批量处理文件夹上一张下一张功能,让软件处理更快,等后面再重制。
阿东游客
赤霄游客把重复文字优选也取消,挑选字命名和编辑单字可以自己在生成的文件夹内处理。
赤霄游客@阿东 #197614
没找到软件,我只有重新找到代码封装。
赤霄游客刚才更新的时候我把网盘的代码也删了,话说上面不知道为什么发出来的代码没有在代码框里面,估计复制用不了,电脑的又被覆盖了,我重新找到代码都,今早我找就没找到。
阿东游客@赤霄 #197617
嗯,己下,不过确实运行有点慢。
赤霄游客明天发前面轻量版的安装文件,开正式分享贴。
阿东游客@赤霄 #197659
好好好!
- 作者帖子
图书馆推荐
近期回复
-
 车马迟 在 林园经济志.朝鲜徐有榘.奎章阁
车马迟 在 林园经济志.朝鲜徐有榘.奎章阁 - 摩诃 在 【佛教古籍】资源帖汇总
- 摩诃 在 【转发分享】【日韩汉籍个人自选】195G
- 蝈蝈 在 【转发分享】【日韩汉籍个人自选】195G
- 玄默 在 世說新語三卷
- 蓝大大 在 求台湾“国家图书馆”藏的叶林宗抄本《经典释文》
- dxx 在 未曾先生你好
- dxx 在 中华珍宝馆
博物馆推荐
公众号:书格

关注了解最新动态
每个人都能自由地看到我们的文明
书格致力于开放式分享、介绍公共版权领域的数字资源
CC BY 4.0:知识共享 署名 4.0 国际