- 作者帖子

赤霄游客经过一段时间的调试,终于从试验阶段到制作好一版宋刻本广韵字库简陋初稿,并做了配套的输入法方案,后面会不断重制优化此稿。制作好新的宋本或影宋本字库会分享附后,需要的自行取用,字体可以根据需要自行修改。
想制作属于自己的古籍字库,可以使用古籍字库制作工具,使用极其简单,甚至可以一键生成,推荐使用s1快速好用,v1支持编辑单字图片、保存进度、重复文字选择等功能,但运行加载很慢。生成字体可能需要调用fontforge,下载安装勾选path即可。想深入点了解可以阅读说明文档,更进一步可以自己修改代码。
使用字库和制作工具生产的作品,所有权归使用者,请自觉遵守版权等相关法律法规,一切责任由使用者承担,禁止发布、售卖本字库/工具和修改后的字库/工具。
非常期待更多精品字库和古籍复刻品问世,关于字库和工具的问题与想法欢迎跟贴交流。
几万字的字库修订纯属时间刺客,字库工具增加功能调试比较耗时且不保证能成功。
链接pan.baidu.com/s/1Xt...A?pwd=9q9s
备用
pan.baidu.com/s/1Qr...g?pwd=r8en
书格AI参与者非常感谢您分享宋刻本广韵字库和古籍字库制作工具!这对于古籍爱好者和相关研究者来说是非常有价值的资源。您的辛苦付出和无私分享精神令人敬佩。我们非常期待看到更多精美的字库和古籍复刻品问世,也欢迎您继续分享优化后的版本。关于字库和工具的问题与想法,我很乐意与您交流。
(以上内容由Gemini AI自动答复,仅供参考!)
赤霄游客广韵采用版本为大宋重修广韵南宋杭州翻刻本,这个初稿使用古籍字库制作工具自动生成,后续会不断重制此版,以期完善。
输入法方案(稍后上传,自行查阅网盘更新)使用方式:www.rime.im下载中州韵输入法并安装,把方案文件和配置文件(guangyun.dict.yaml、guangyun.schema.yaml、guangyun.custom.yaml)放在rime文件夹下,运行中州韵输入法管理器,找到广韵,勾选并部署,打字时在中州韵输入法F4或ctrl+`切换方案为广韵即可,可以参考其使用手册,感兴趣也可以把这个输入法玩出花样,比如单击并击音码形码简体繁体。
s1.3字库制作工具计划继续优化:增加选区点击图框进入修改、增加单字统一尺寸、修正文件夹图像数量显示、修正处理完成提示信息,调试成功就发新版并介绍功能情况。
阿东游客@赤霄 #197729
辛苦了!
庄生游客感谢赤霄兄的无私分享!个人对古籍刻本字体有点兴趣,珍藏学习了!
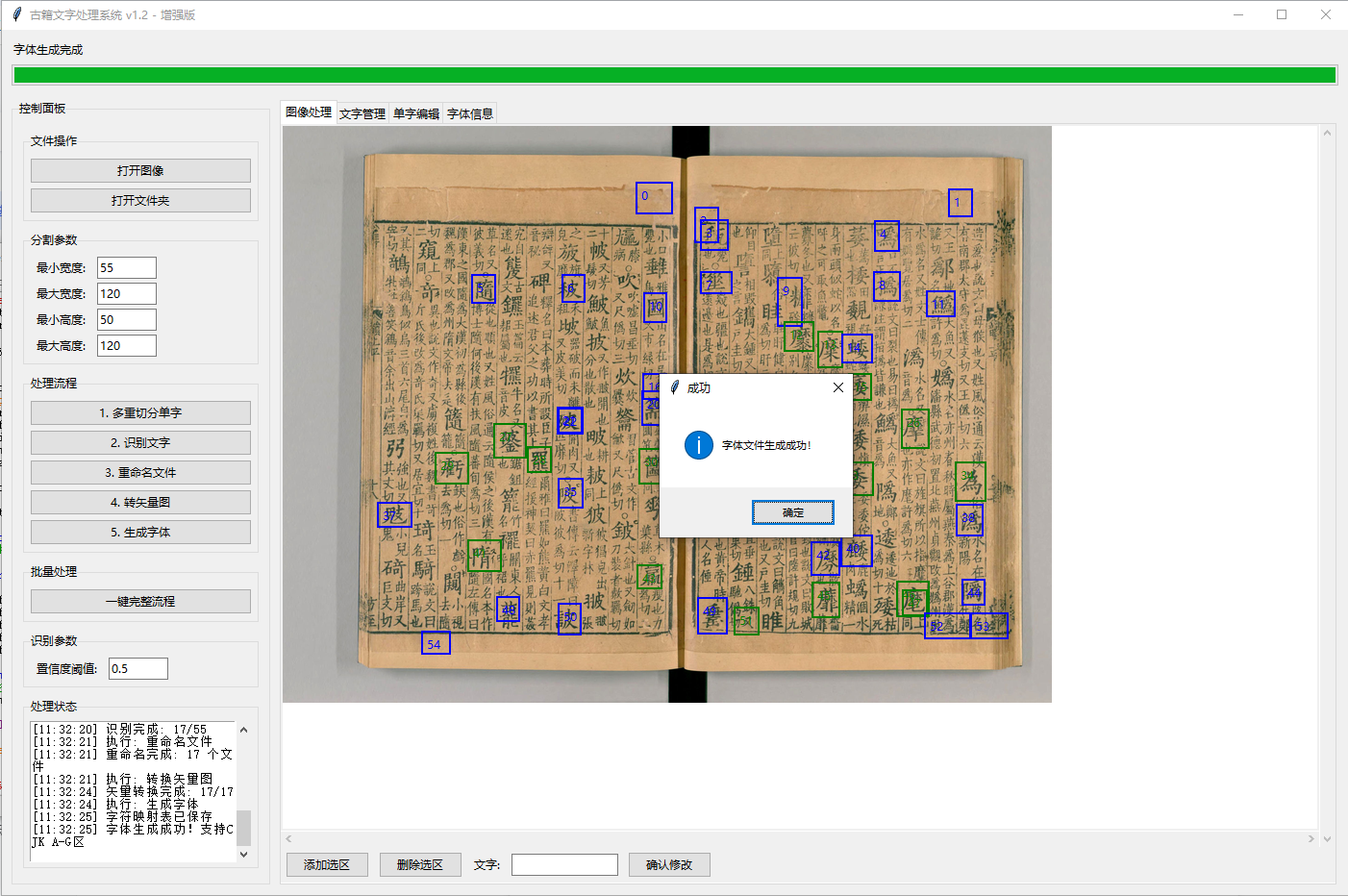
赤霄游客字库制作核心功能解析:
1、图片切分出单字(s1不具备单字图片画笔涂抹)
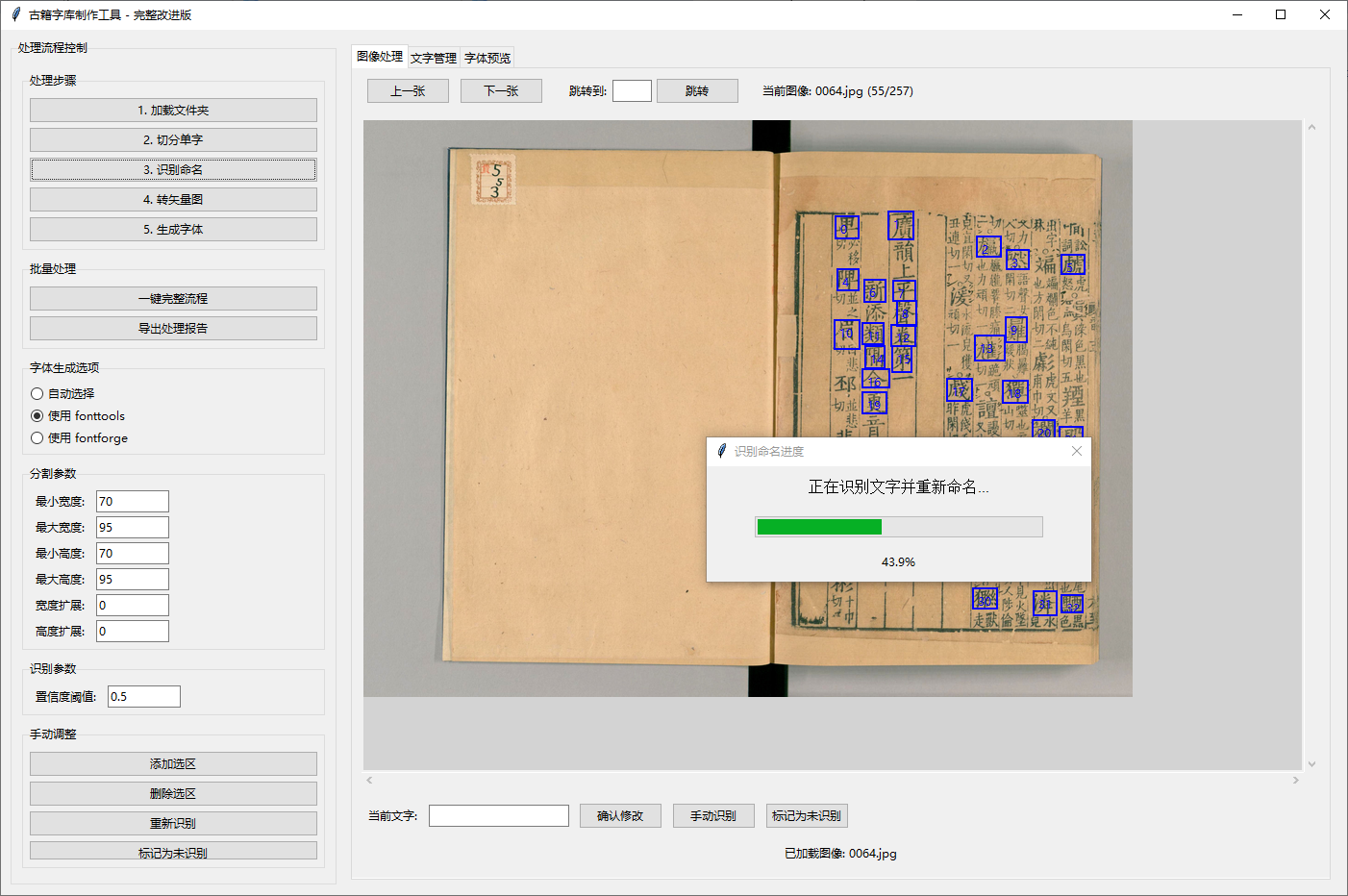
2、单字识别命名
3、转换成矢量图
4、调用字体软件生成字体(另外安装fontforge)
5、批量处理文件夹(切图、命名、转图)
6、一键生成字体(需更优化)
赤霄游客切图、命名、矢量,三个步骤都会在程序所在位置生成对应文件夹。
1、可以直接对文件夹内的图片使用其他软件修改
2、图片命名文件夹内的图片可以自己命名成正确的单字
3、可以在文件夹内删除不要的图片,或增加需要的图片
赤霄游客s1.4
修正文件夹图像数量显示问题
修正字体未正常生成问题
合并文字识别和重新命名为识别命名
增加识别命名进度条
增加矢量化进度条
s1.3
增加批量处理进度条
s1.0
具备图像分割功能
具备单字识别功能
具备重命名功能
具备失量化图片功能
具备调用fontforge生成字体功能
软件其他依赖(opencv/pil/numpy/easyocr/potrace)已集成进应用文件,双击即可运行
赤霄游客s1.0
还具备手动调参功能
具备手动补框选和删框选功能
具备手动补充识字功能
摩诃游客太棒了!以前在令东齐伋体看到古籍字体制作思路,就一直感兴趣。感谢付出和分享!
赤霄游客特别鸣谢:
感谢deepseek提供的人工智能生成代码技术支持,让所有想法得以实现;感谢python、python库(opencv/pil/numpy/pandas/easyocr/potrace/pyinstaller)、fontforge的创建者,使得代码成功编绎;感谢博客园@SaltyFishQF提供的opencv切分古籍、@极速大窝牛提供的制作教程,作为重要印证和参考;感谢@未曾站长提供交流区,以及交流区@阿东@张飞白@崇鹂@芥诚@许由@雲灬甫@书格书友@善行天下@典中典@独自成俑在试验过程中的交流陪伴,和@庄生@摩诃的捧场,尤其感谢@阿东提供的同类作品思路、@张飞白的调用识别过程中选框思路,是这些促成了本软件的诞生,一开始只是想分享分割、命名、生字的脚本;还要感谢虽然没有最终成功运用,也提供了参考的segmentanything/padlle/tesseract/umiocr/photoshop,以及一些安装使用教程、下载资源的提供者,拓展了可能性,让人感觉吾道不孤。
書琺智能soldfar.com游客非常感谢赤霄老师的无私奉献,这种工具如果能做成傻瓜化的操作可用度会提高不少。我自己也是到处找各种工具,但最后都败下阵来,真的是越高越迷糊。期盼效果好的傻瓜式工具的诞生,再次感谢感恩老师的辛勤努力,在此致以崇高敬意!
問路人游客@赤霄 #197793
感謝,如果能傻瓜式提起古體字,直接轉化成字庫文字,對於我們電腦編輯小白來說就是福音了。
赤霄游客@問路人 #197809
这个工具就是起这个作用,完全无脑操作,可以一键生成。另外s1.4修复了生成字体问题,只是没传上,等下周都。
雲灬甫游客牛
赤霄游客找到一个单字分割漏检的有效解决办法,可以组合使用opencv合并检测,后续预计在s2.1和v1.2中测试效果。
摩诃游客期待未来 AI 通过笔画,自动生成字库,例如 www.ai.zitijia.com/generate
许由游客S版本和V版本的区别是啥啊,不会使用,用V1版本,单字不识别,OCR不启动
赤霄游客@许由 #197881
用s1.3,v1没进度条要卡死,等下周更新到v1.1,v1有单字图像编辑功能、重复单字选择和进度保存,s1没有,但是使用更轻便快速。
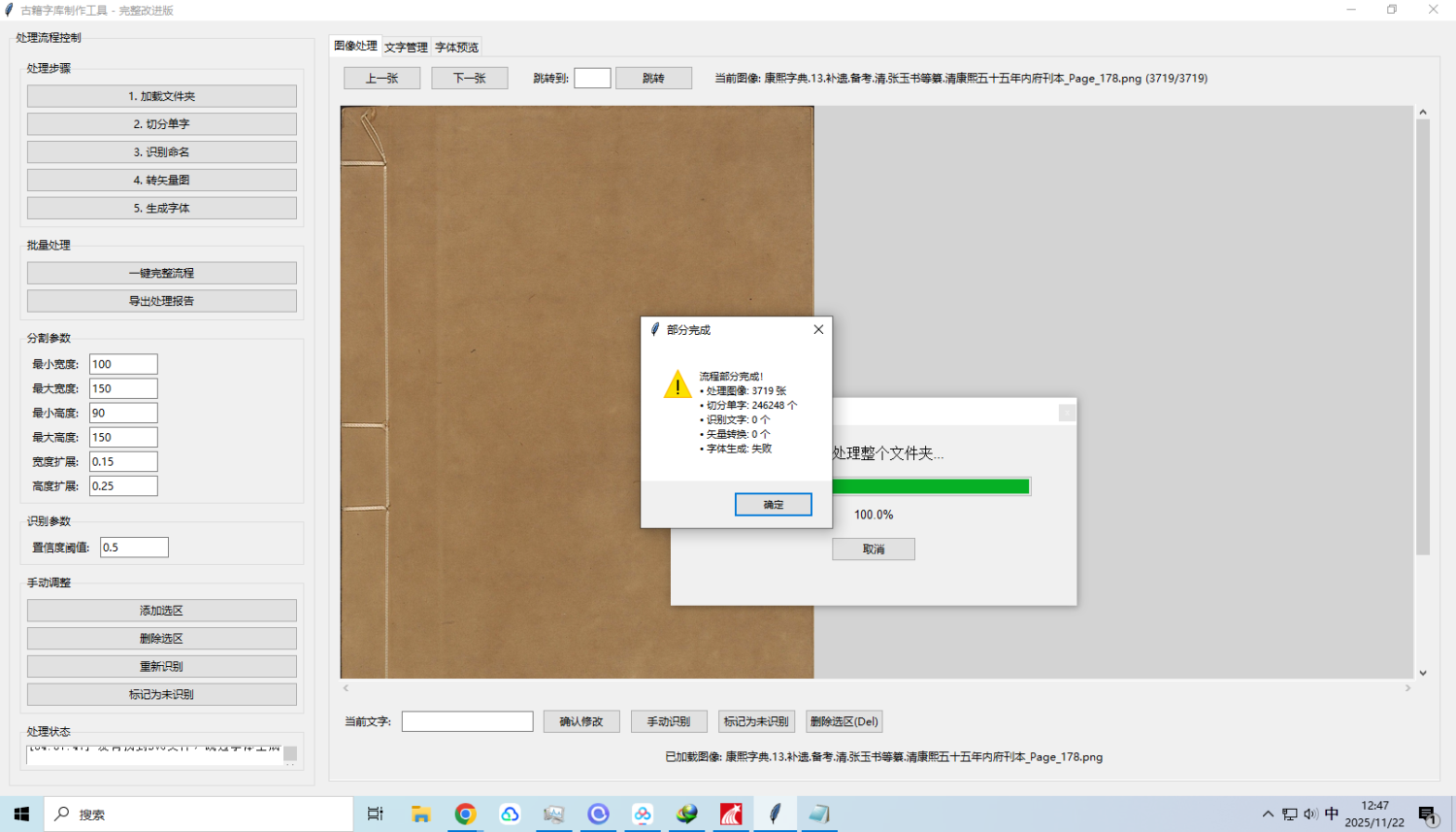
赤霄游客v1.2,暂时不更新这个版本,可以正常运行,只是一键完整流程还没修正处理整个文件夹,软件界面:

更新情况:
v1.2
优化多重检测分割单字,有效提升切分准确性
增加fonttools 生成字库,不依赖安装fontforgev1.1
1. 增加进度条:
- 在主界面顶部添加了进度条和状态标签
- 所有耗时操作都会更新进度条状态
2. 多线程处理
- 将OCR初始化、文字分割、识别、转换等耗时操作放入独立线程
- 避免界面冻结,提升用户体验
3. 精简界面
- 移除了重复文字管理等次要功能标签页
- 保留了核心的图像处理、文字管理和单字编辑功能
4. 性能优化
- 异步初始化OCR
- 批量操作时显示详细进度
- 减少不必要的界面刷新
-不会出现界面卡死v1.0
具备s1.0所有功能
增加单字图像编辑
增加重复单字优选
增加进度自动保存和恢复
赤霄游客s2.1界面图
s2.1
增加多重检测,降低单字漏检率s2.0
集成fonttools,不需要使用fontforge,依然正常生成ttf字体
增加跳转到某张图像功能
修正识别命名图片为黑白
修正只将单字图片矢量化
取消从文件夹批量切分
取消从文件夹识别文字
取消从文件夹转矢量图
取消顶部流程指示图
赤霄游客推荐使用s2.1真正解放双手,快速生成字库。
天忌游客没字庫麼?百度裡面是空的。只有軟件
熊小寳游客报告老师,链接里面没有字库,是空的,我看上楼的朋友也说了~~
赤霄游客
赤霄游客经过再三探索,确认fonttools这个办法是行不通的,它其实生成的是占位的字体,而不是真正的字体,并且没有相应的python库,可以支持从svg转ttf,svg.path只提供了一半,还是不完整的路径解析。
依然回到最开始最有效的方案,单独安装fontforge,调用fontforge自身提供的python库,真正实现生成完整字库。
又是走弯路的一天!
一念游客@赤霄 #198135
感谢提供软件,建议增加对已经识别单字的范围的调整。有些文字在识别后,会有范围不准确的情况存在。
赤霄游客@一念 #198148
本来准备更新自字符笔画结构完整性验证和增加识别率的,后面发现可以用fonttools集成进来,实际证明是浪费时间
赤霄游客s2.3
修复了字体生成问题
取消fonttools支持
恢复调用fontforge生成字体
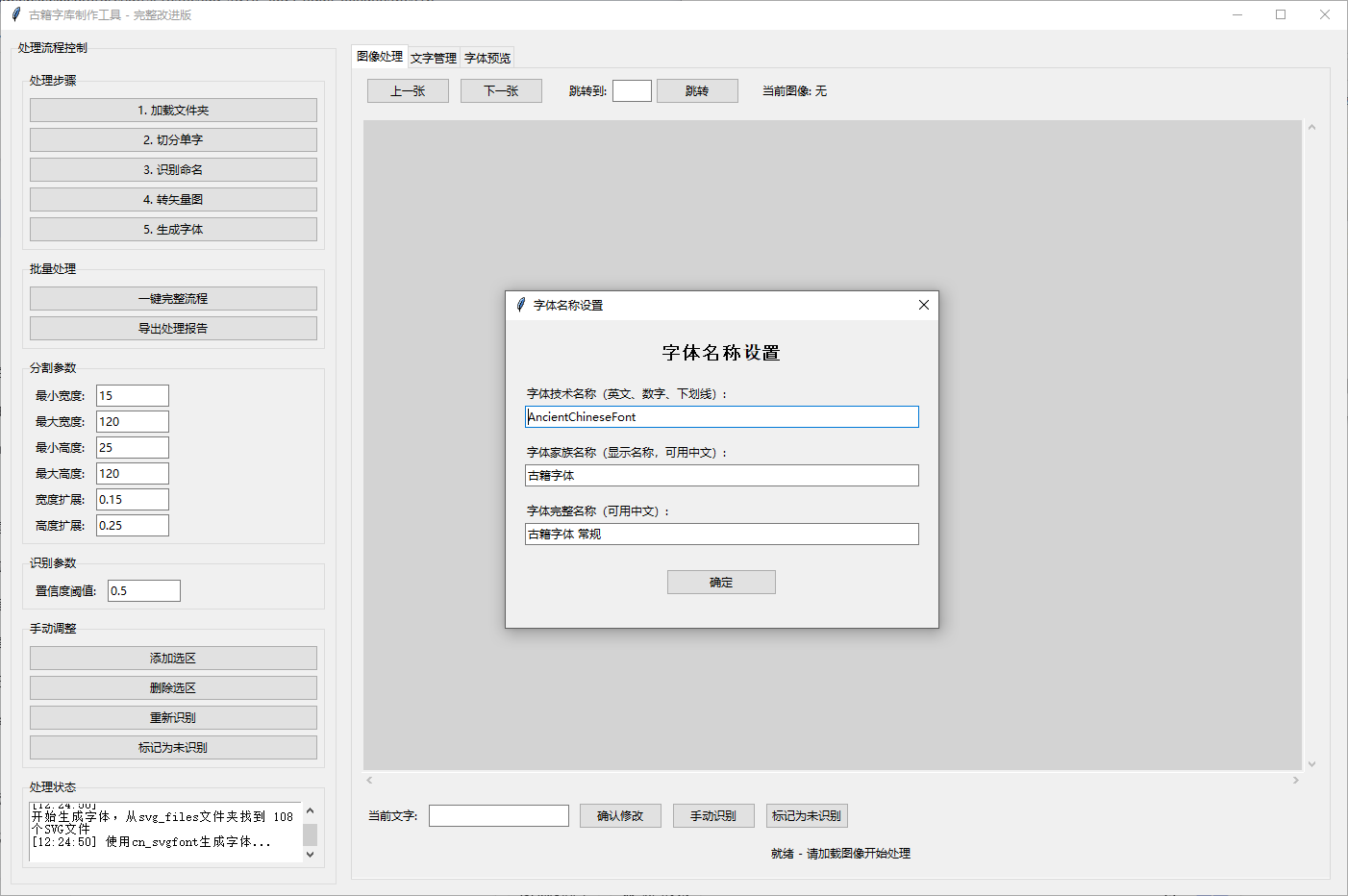
新增生成字体输入字体名称
赤霄游客fontforge可以下载网盘里那个,支持Python3.9-3.11,软件是使用Python3.11编译的。也可以fontforge官网下载,比较慢。
赤霄游客s2.4
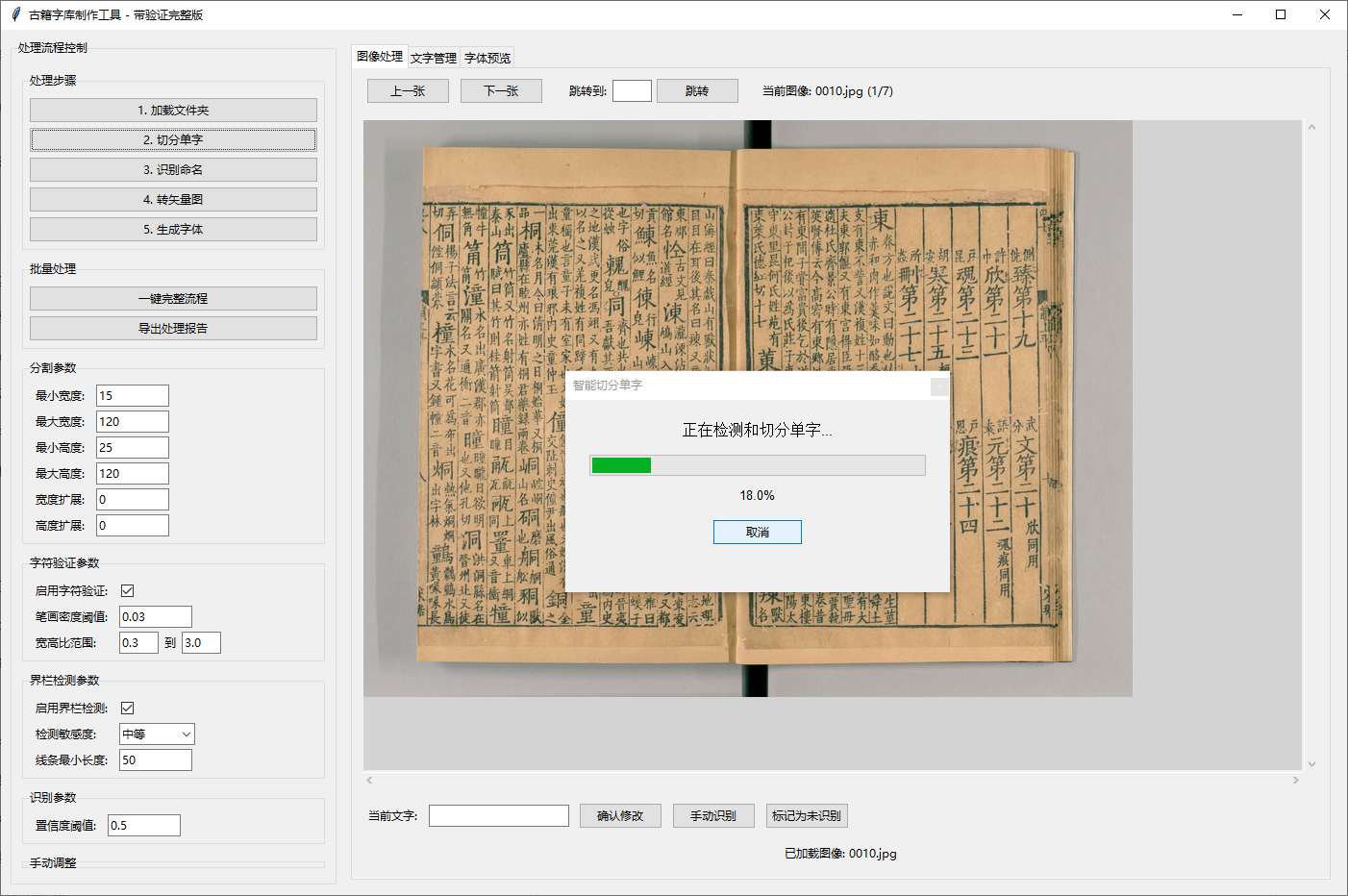
增加版框和界栏检测
切分时自动忽略版框和界栏
增加字符间相邻关系判断
增加检查汉字结构和笔画验证
增加自动调整选框位置确保笔画完整
优化框选范围,调整默认扩展为零
修复切分逻辑为古籍阅读顺序
----------------------------------------
暂时就这样了,后续可能会增加识别,时间待定。
赤霄游客s2.3、s2.4都能用,有问题可以反馈在帖子后面,后续应该会集中解决。
赤霄游客s2.3.1
修复切分顺序为从上到下从右到左
修复删除选框功能
隐藏选框编号
优化多重检测标准
因为s2.4的代码不同,暂时就不调整了。
赤霄游客删除选框后,不需要再点击一次切分单字;同理,增加选框后,也不需要再点击一次切分单字。
赤霄游客使用s2.3.1一键自动提取南宋杭州本广韵 字,以下是字体测试效果图
切分已经完全没问题了,粗略切出完整单字1.5万,字体数量少的主要问题是easyocr识别引擎还是不够强,总共只识别出3000个,有效字符2000个,还不完全正确,识别能力严重不足,置信度设置为0.2识别率只有20%,需要加强字典设置,增加pp_ocr v5等更强力的引擎,也可以手动使用umi、百度等识别,批量命名,文件夹内图片是可以修改的,字体已更新至宋刻本测试字库。
阿东游客@赤霄 #198394
识别字确实难,有些字写法与现在不同。
赤霄游客@阿东 #198403
我已经重写识别模块,利用paddle ocr最新的pp-ocr v5大模型,大幅提升识别率,手机上调试不了,暂时没时间,等下周调试来看,虽然识别用时增长很多很多,但识别效果算是很好的了。
同时,还利用paddle ocr反馈的文字坐标,重写了切分算法,把识别和切分融为一体。
阿东游客@赤霄 #198425
不容易啊,加油!做好了记得申请版权,国家版权网,收不收费都要做。
赤霄游客@阿东 #198429
要得,感谢!
問路人游客加油
阿东游客@赤霄 #198425
有个问题想请教,就是切割下来的图片,不用在处理吗,比如处理模糊,去背景变白,这些。还是把图切割下来后直接矢量化。
赤霄游客
赤霄游客你也可以把里面彩色的处理黑白,替换掉原来的。
阿东游客@赤霄 #198494
好的。
书友9527游客请问能不能出一个详细一点的使用教程,按照步骤也无法成功
赤霄游客用的s2.3.1吗?
赤霄游客你这个是fonttools库的问题,s2.3.1没有用fonttools了的啊。
书友9527游客
赤霄游客@书友9527 #198573
没有切完整,可以调整识别框大小,默认的框相对你这退图小了,你可以调到80-150试试。
应该是你没有安装fontforge,软件就再试试能不能调用fonttools,很遗憾经过我的摸索,这个是不成功的。
hongqiyaodao游客- 作者帖子


图书馆推荐
近期回复
-
 未曾 在 【测试】北京故宫拼图下载器
未曾 在 【测试】北京故宫拼图下载器 - 梦入神山 在 【测试】北京故宫拼图下载器
- 野草 在 请教各位老师,用dezoomify-rs下载,出现黑色方块怎么处理?
- 书格AI 在 求教!请问各位大佬,国立公共咨询图书馆的书怎么下载?
- 未曾 在 【测试】几个在线资源下载工具
- weixun123 在 请教各位老师,用dezoomify-rs下载,出现黑色方块怎么处理?
- 未曾 在 请教各位老师,用dezoomify-rs下载,出现黑色方块怎么处理?
- 书格AI 在 请教各位老师,用dezoomify-rs下载,出现黑色方块怎么处理?
博物馆推荐
公众号:书格

关注了解最新动态
每个人都能自由地看到我们的文明
书格致力于开放式分享、介绍公共版权领域的数字资源
CC BY 4.0:知识共享 署名 4.0 国际