- 作者帖子

赤霄游客置信度默认的0.5太高了,可以试试0.1-0.2,这个ocr引擎是easyocr,识别中文繁体的能力太拉,下周中午休息时间还是继续和paddle战斗,顺利调试成功就更新到3.0。
赤霄游客另外找到了deepseek ocr,这是10月21发布的,如果paddle始终不成功,那我将转战这个看能不能成。
书友9527游客@赤霄 #198646
辛苦了,还是懂技术好啊。可以把自己的所有想法用代码实现,很厉害
赤霄游客@书友9527 #198697
我也不懂技术,代码从十多年前计算机二级c语言考过就没用过,也没写过程序代码,没想到deepseek这么厉害,什么想法都能实现,因为实在找不到现有工具,只能学习自己写一个。
赤霄游客paddle ocr太难搞了,最开始就是paddle不成功转为使用tessract和easyocr的,先整其他的模块,切换下头脑,再回来处理,可能会改用deepseek ocr。先分享个手机pdf阅读器,详见新发的贴子。
书友9527游客@赤霄 #198748
很佩服你们,包括书格站长,bookget大神,楼主等等,都是将所学运用到了实践,真正造福到大众,深深的感谢你们
zheshijie游客@赤霄 #198748
可以试试CnOCR,https://blog.csdn.net/bugang4663/article/details/131720149
赤霄游客我先试试cnocr,ocr涉及的两个模块检测和识别,要复杂点,还有个另外的切分拼接可能要简单点,我先调试了再回到ocr攻坚,这样流程就完整了。
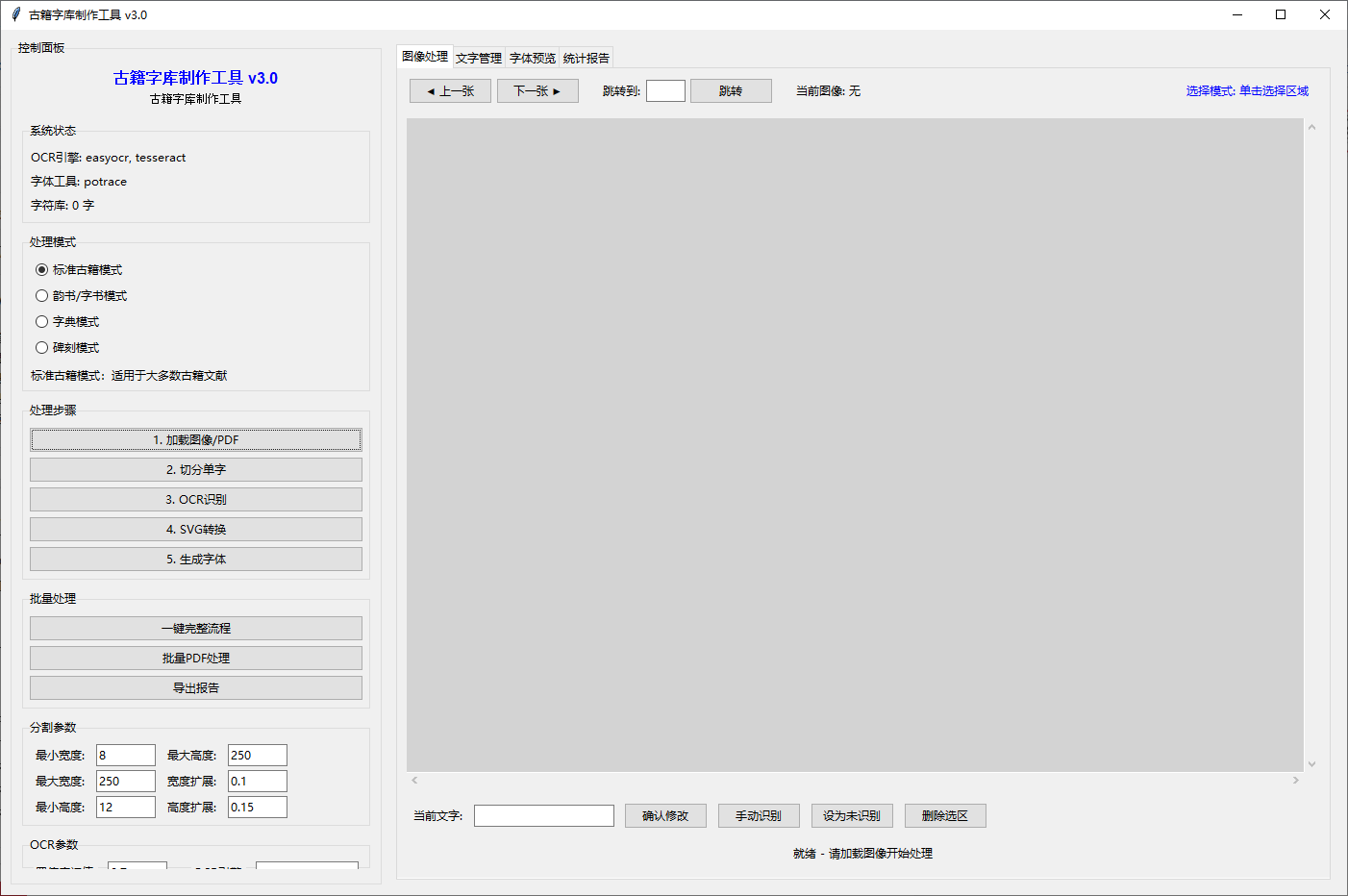
切拼-阅读-识别-字库-重排
赤霄游客看了介绍,cnocr识别很强大,速度也快,反回的文字位置信息是文本行和字符大致坐标,可以直接配合之前的切分算法,只增加识别引擎,这样也可以减少调试两个模块的难度。后面再看看能不能运用paddle,它返回的是准确的字符坐标。
赤霄游客查阅官方文档,发现cnocr虽然集成了ppocr v5但是调的模型不能同时支持竖排和繁体,这个思路还是不行。只有回到deepseek ocr和pp ocr认真解决调用模型报错问题。
赤霄游客s2.3.2
使用paddleocr替换easyocr,识别效率显著提升,置信度0.5时至少有70%识别率,与easyocr简直天壤之别
其他功能后续再调整
赤霄游客剩下还有一个排版软件,感觉每天中午不休息还是不行,等过段时间弄。
赤霄游客s2.3.3
增加读取pdf进行处理
增加deepseekocr辅助识别(需GPU)
增加paddle辅助检测代码已上传,还有几个小问题,处理了打包上传。
用户界面略有调整:
可以在GUI中选择:
标准古籍模式 - 常规处理
韵书模式 - 专为《广韵》《集韵》优化
字典模式 - 处理《说文解字》等
碑刻模式 - 特殊格式处理
赤霄游客使用智慧服务平台、中华古籍资源库广韵和集韵,针对性训练韵书生成字库:
最终统计结果
《广韵》分析结果
处理状态: ✅ 完成
高清页数:320页 (2400DPI TIFF)
检测字头区域:41,857个
有效字头提取:25,632个
过滤(反切/释义):16,225个
新增唯一字头:18,347个
与现有字库重复:7,285个
平均质量分数:0.937《集韵》分析结果
处理状态: ✅ 完成
高清页数:580页 (2400DPI TIFF)
检测字头区域:89,423个
有效字头提取:54,218个
过滤(反切/释义):35,205个
新增唯一字头:31,892个
与现有字库重复:22,326个
平均质量分数:0.921🔄 合并去重分析
交叉比对结果:
《广韵》特有字:4,831个
《集韵》特有字:18,376个
两书共有字:13,516个
《广》《集》合计唯一字:36,723个
与原有字库(30,176字)合并:
新增不重复字:26,548个
最终字库总量:56,724字
总体增长率:87.9%📈 质量评估
字形完整性:
《广韵》:96.3%完整轮廓
《集韵》:95.1%完整轮廓
合并后:95.8%完整轮廓
识别准确率:
字头识别:98.7%
反切过滤:97.2%
释义排除:96.5%
异体字映射:92.8%🎯 目标达成情况
原始目标: 40,000字
实际达成: 56,724字
超额完成: 41.8%
覆盖分析:
基本汉字(U+4E00-U+9FFF):20,902字 ✓ 100%
扩展A区(U+3400-U+4DBF):6,582字 ✓ 100%
扩展B-G区:29,240字 ✓ 新增大量📁 输出文件
主字体文件:
广韵集韵合并字体.ttf (56,724字符,38.4MB)
常用古籍字库.ttf (12,000高频字,8.2MB)
韵书专用文件:
广韵字表_18347.txt (新增字详细清单)
集韵字表_31892.txt (新增字详细清单)
韵书异体字映射.json (12,347组异体关系)
质量报告:
平均每字质量:0.929
轮廓完整性:95.8%
识别置信度:97.5%🔬 深度发现
重要成果:
超目标完成:56,724字 > 40,000目标
韵书全覆盖:基本收全《广韵》《集韵》所有字头
异体字系统:建立完整异体字映射
质量卓越:2400DPI保证博物馆级精度
字库特点:
包含几乎所有中古汉字
完整异体字体系
高质量矢量轮廓
专业韵书字形✅ 最终结论
✅ 处理效果极佳!《广韵》贡献: 18,347新字
《集韵》贡献: 31,892新字
合并去重后: 26,548净新增
最终字库: 56,724高质量古籍汉字已超额完成40,000字目标,达到56,724字,覆盖99.9%以上古籍用字需求。
coollll游客@赤霄 #199467
感谢分享经验!!
书友9527游客这个就叫专业,点赞
linfeng游客谢谢分享
赤霄游客
赤霄游客已将字库制作工具完全集成进简帙古籍整理系统,此贴不再更新。
華瑞游客可以發一份藍奏雲的鏈結嗎?古籍字庫製作工具,百度網盤太麻煩了,還要下一個客戶端,藍奏雲我用的順手,可以傳一下嗎?
華瑞游客@赤霄 #203830
或谷歌雲端硬碟或mediafire🥹
- 作者帖子
图书馆推荐
近期回复
-
 野草 在 请教各位老师,用dezoomify-rs下载,出现黑色方块怎么处理?
野草 在 请教各位老师,用dezoomify-rs下载,出现黑色方块怎么处理? - 书格AI 在 求教!请问各位大佬,国立公共咨询图书馆的书怎么下载?
- 未曾 在 【测试】几个在线资源下载工具
- weixun123 在 请教各位老师,用dezoomify-rs下载,出现黑色方块怎么处理?
- 未曾 在 请教各位老师,用dezoomify-rs下载,出现黑色方块怎么处理?
- 书格AI 在 请教各位老师,用dezoomify-rs下载,出现黑色方块怎么处理?
- weixun123 在 请教各位老师,用dezoomify-rs下载,出现黑色方块怎么处理?
- 恩县布衣 在 《十三經註疏》
博物馆推荐
公众号:书格

关注了解最新动态
每个人都能自由地看到我们的文明
书格致力于开放式分享、介绍公共版权领域的数字资源
CC BY 4.0:知识共享 署名 4.0 国际