- 作者帖子

未曾管理员最近计划把bookget的大部分下载功能使用浏览器(基于jszip和filesaver)实现。目的是为了减少大家对电脑环境的依赖。
大致使用方法就是,粘贴需要下载的书籍URL。然后点击解析下载,浏览器会将书籍打包(zip)下载。
当然,由于浏览器下载不一定稳定,在线获取适合临时救急使用。如果条件允许,我们还是推荐大家使用电脑+bookget。
小工具实验室主页
由于需要针对性处理,暂公开测试几个
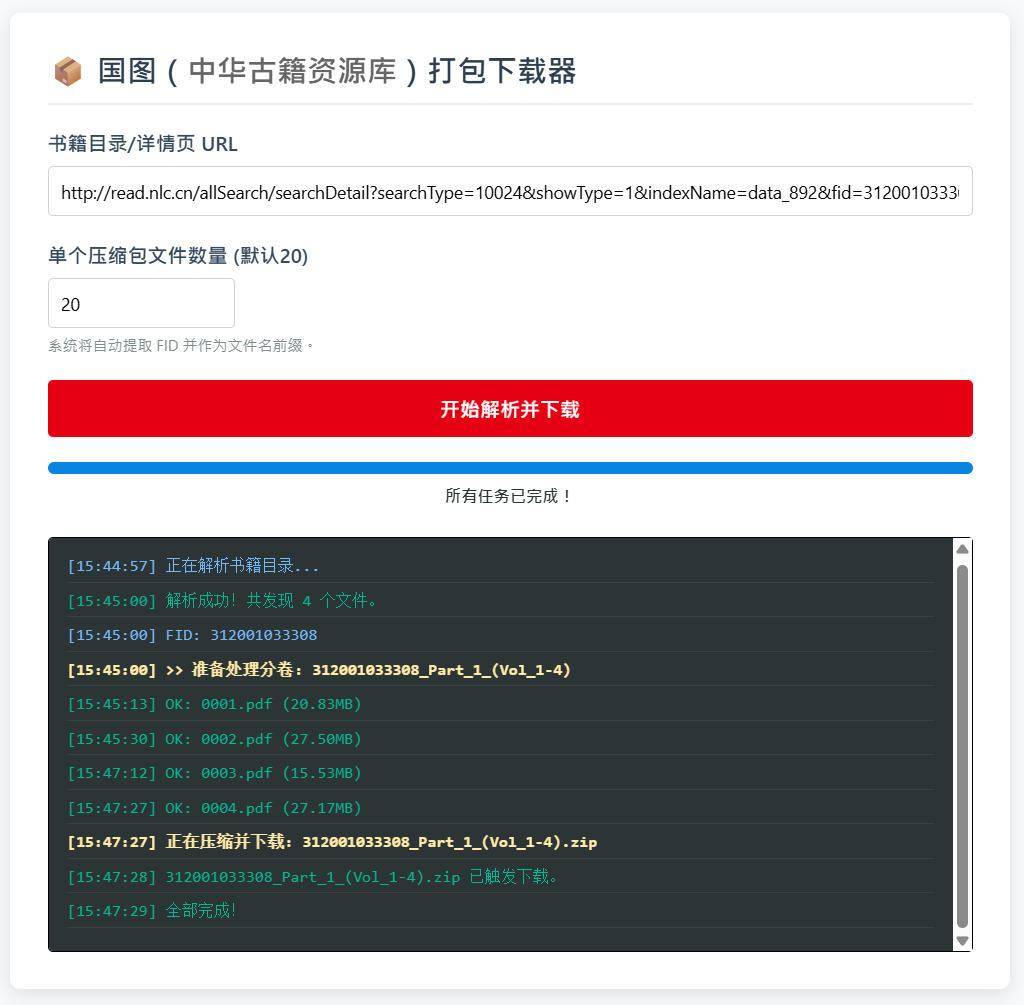
国图(中华古籍资源库)打包下载器
由于需要处理token,使用了PHP解析通过服务器中转文件到用户(可能速度会因服务负载变慢),最后前端浏览器JS打包压缩和下载。
测试地址: tools.hanjihebi.com/nlc/

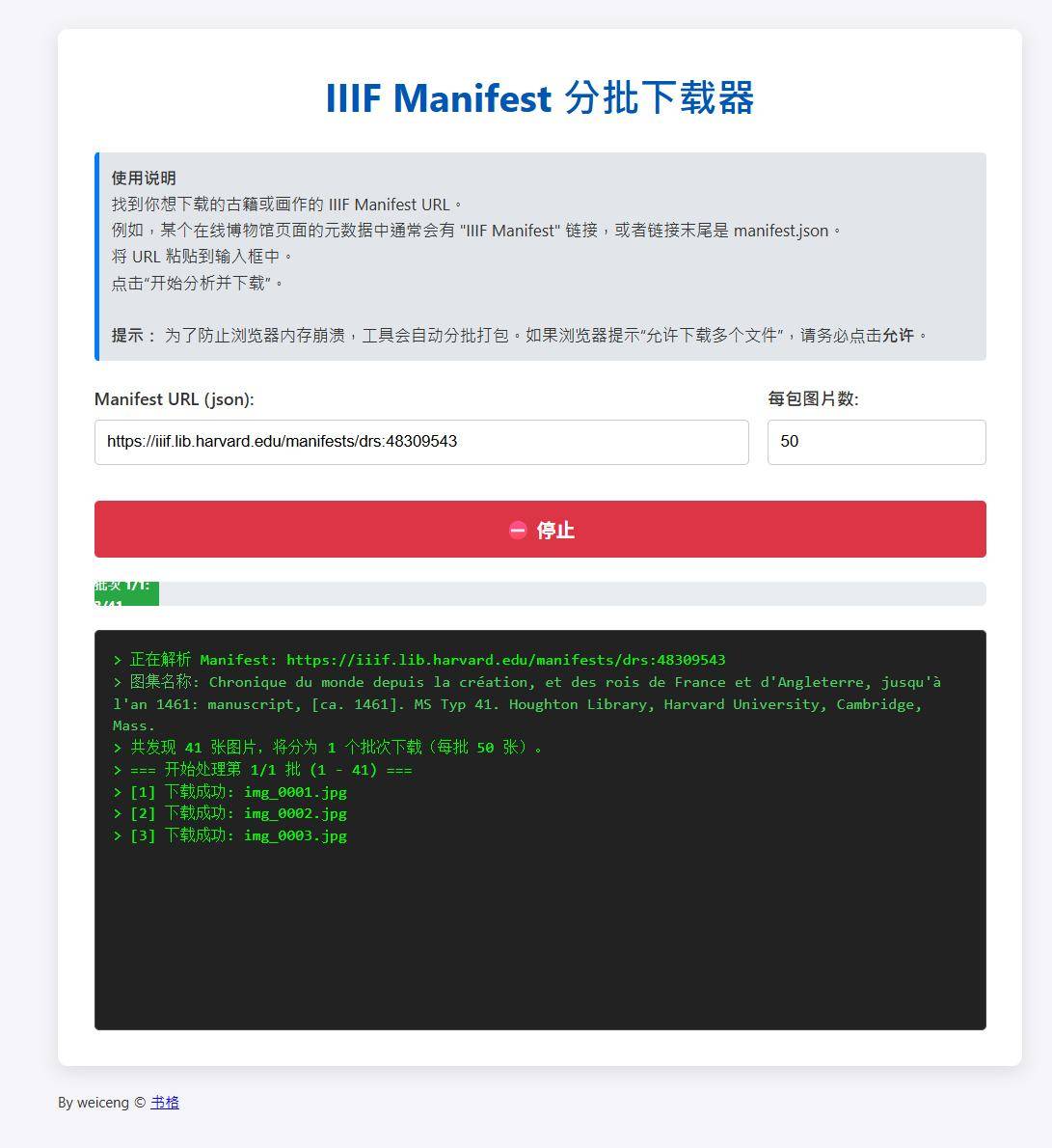
IIIF 智能下载器
这个是纯前端实现的,不依赖服务器,但是需要用户浏览器能访问对应资源。
测试地址: tools.hanjihebi.com/iiif/
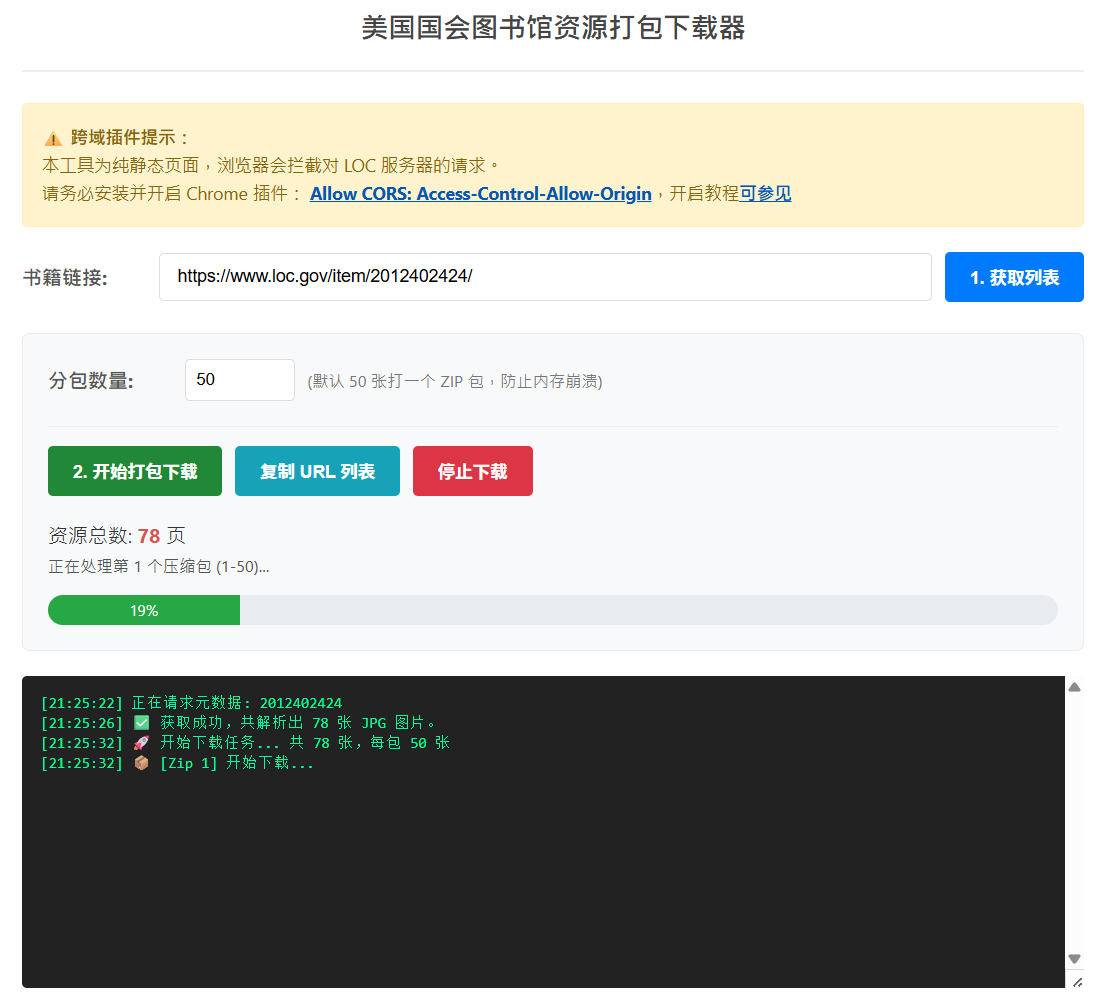
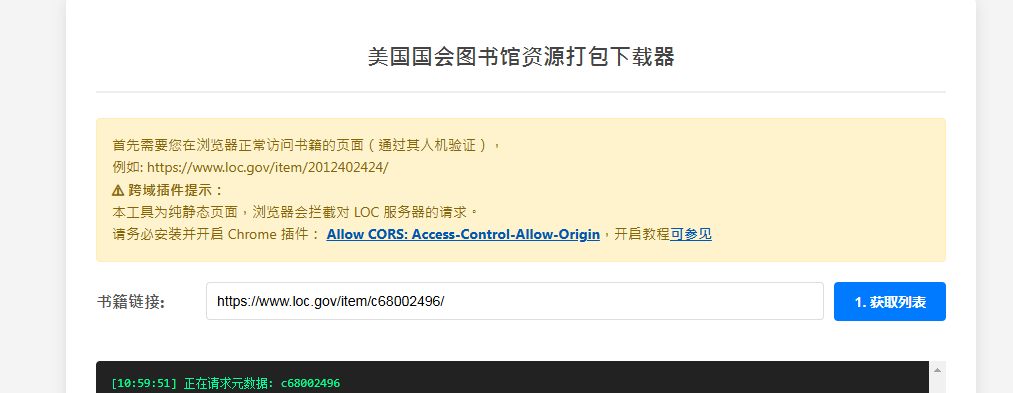
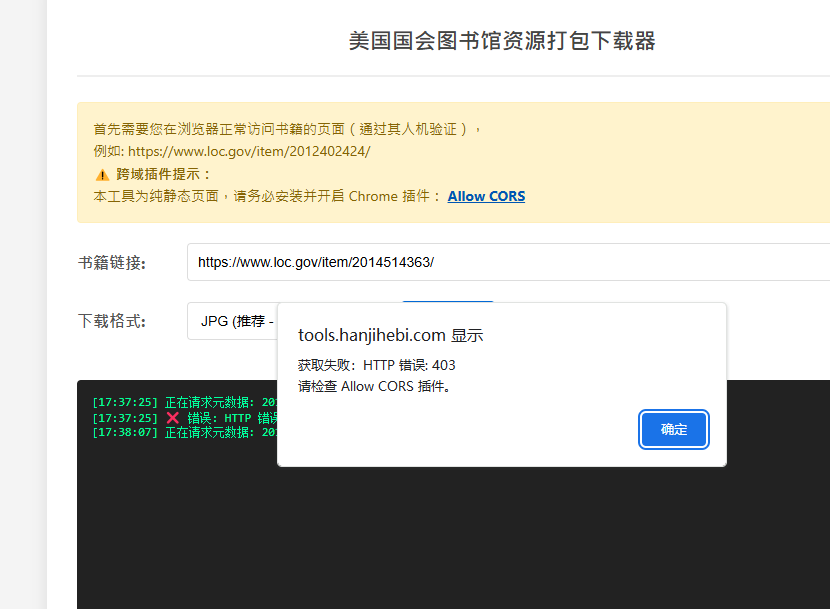
美国国会图书馆资源打包下载器
这个是纯前端实现的,不依赖服务器,但是需要用户浏览器能访问对应资源。需要安装浏览器插件:Allow CORS
测试地址: tools.hanjihebi.com/loc/
上海图书馆打包下载工具 (半自动解析)
使用教程参见
测试地址: tools.hanjihebi.com/shtsg/
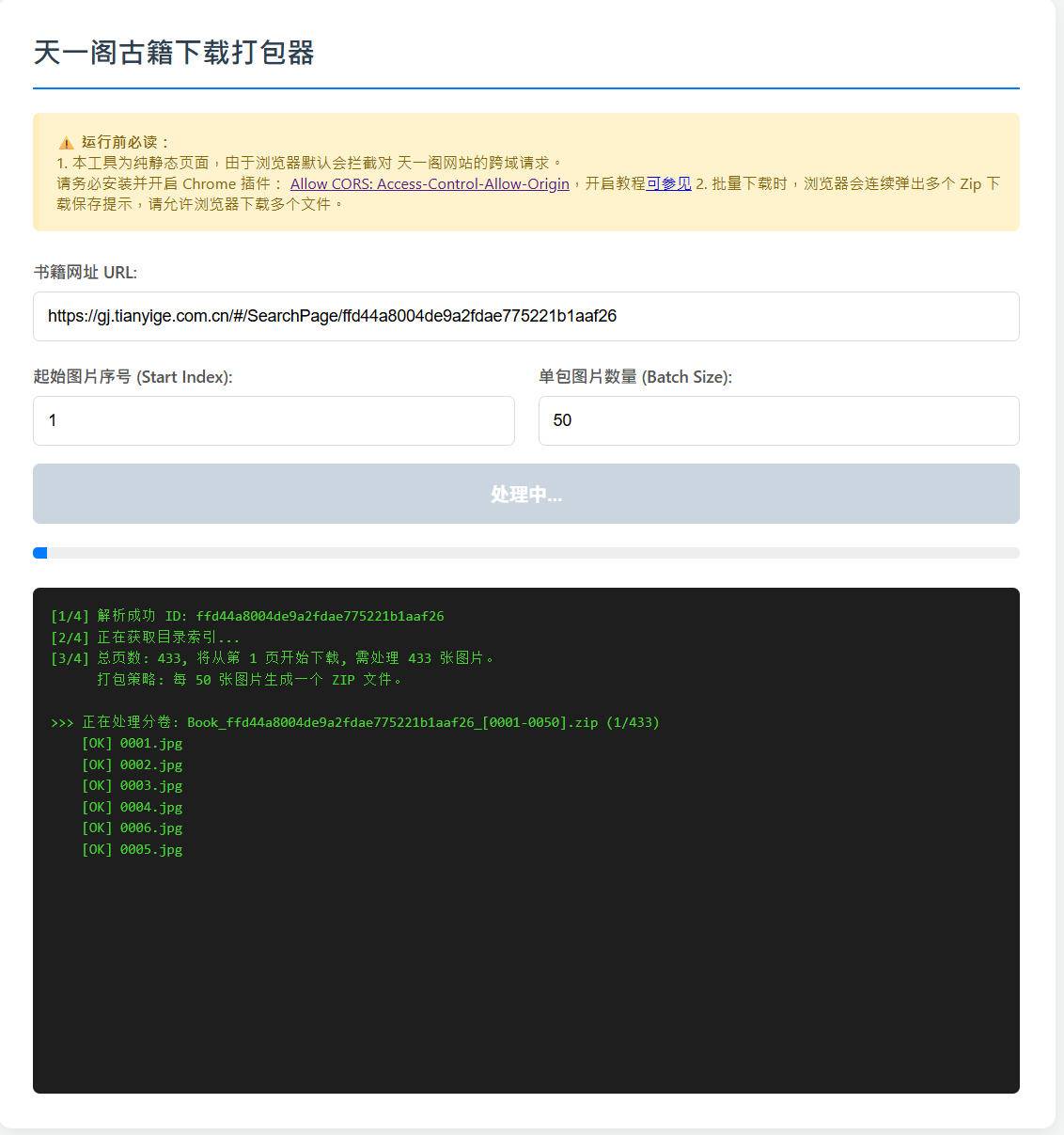
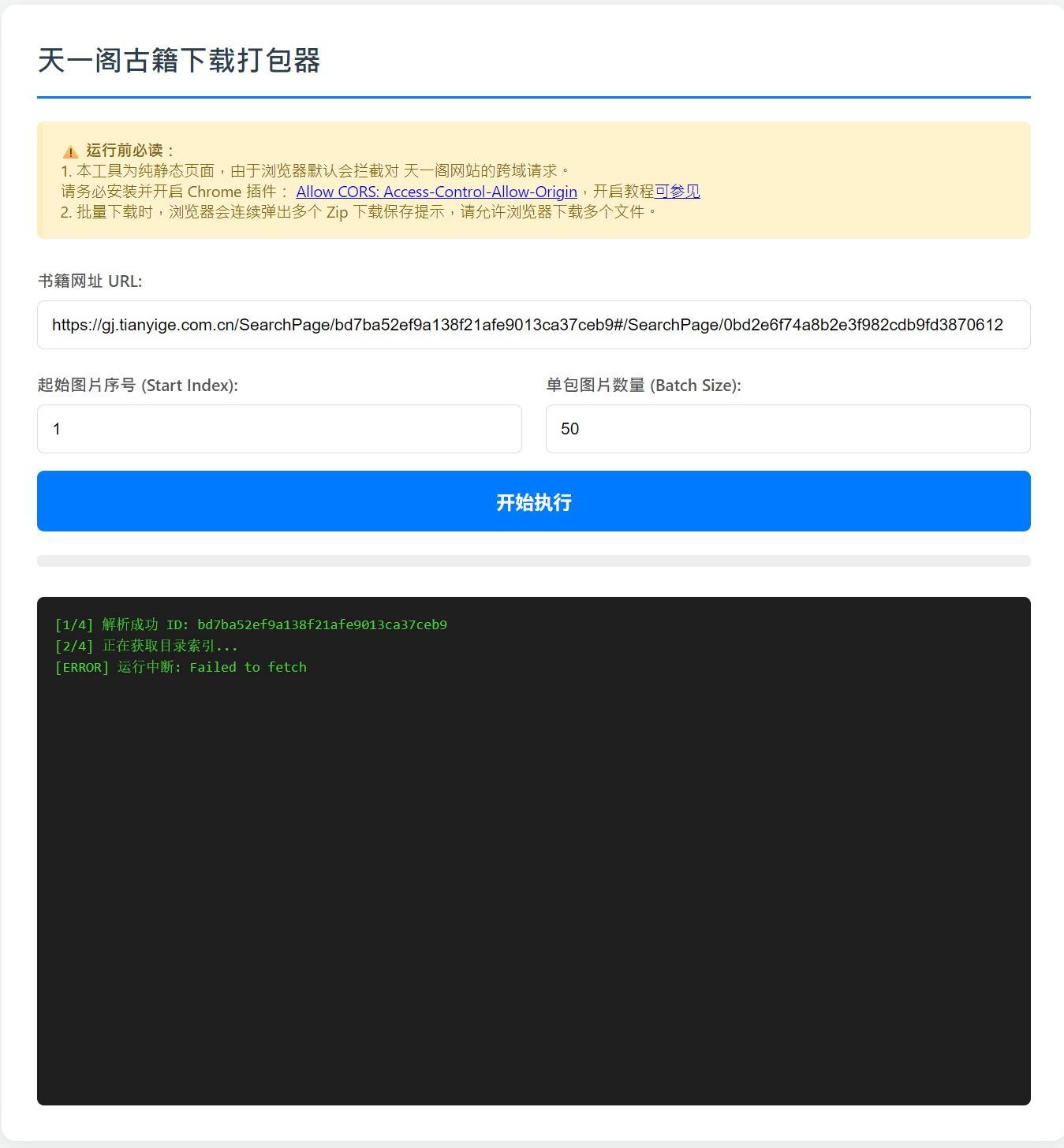
天一阁古籍下载打包器
1. 本工具为纯静态页面,由于浏览器默认会拦截对 天一阁网站的跨域请求。
请务必安装并开启 Chrome 插件: Allow CORS
2. 批量下载时,浏览器会连续弹出多个 Zip 下载保存提示,请允许浏览器下载多个文件。测试地址: tools.hanjihebi.com/tygbwg/
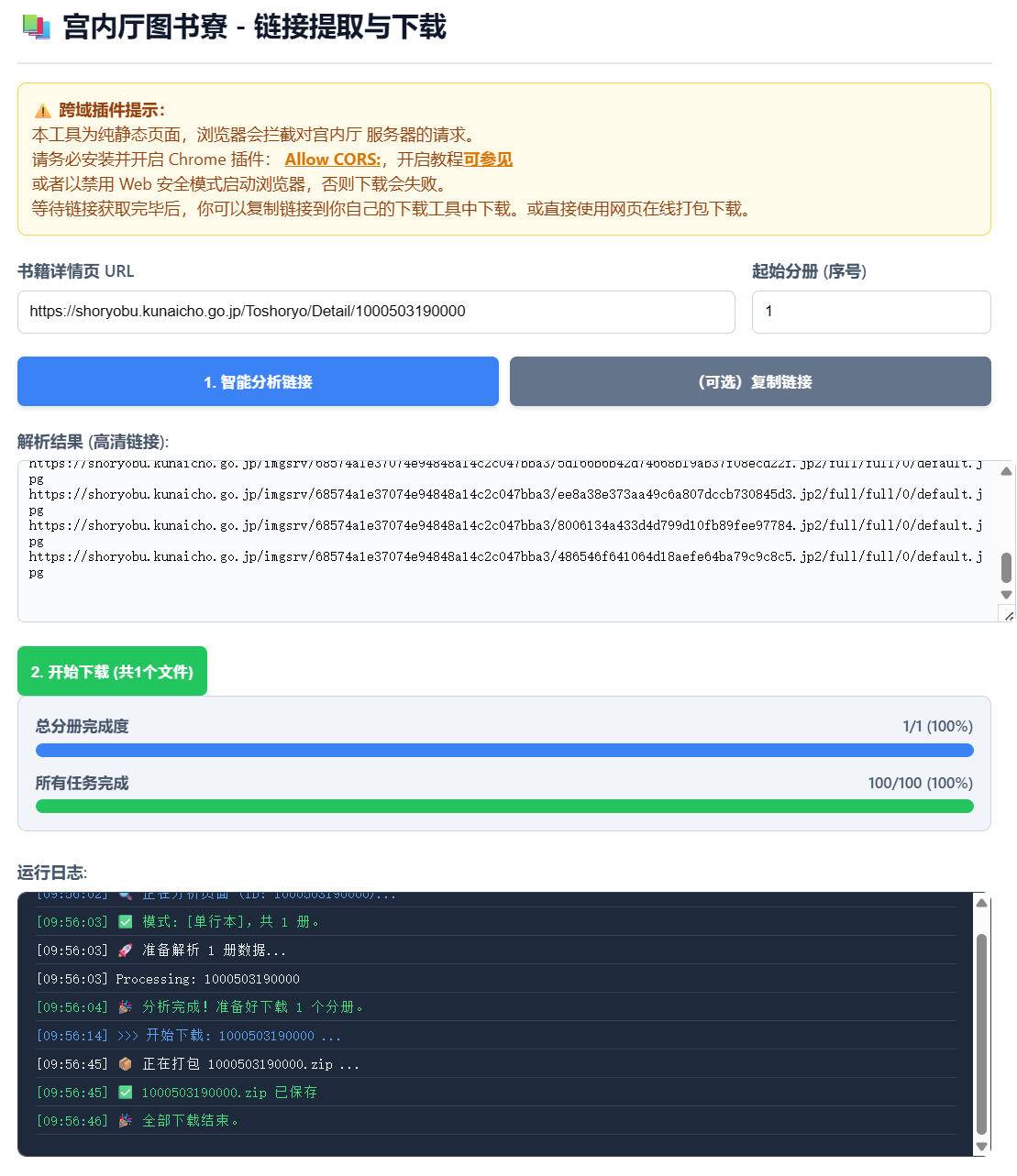
宫内厅图书寮 - 链接提取与下载
本工具为纯静态页面,浏览器会拦截对宫内厅 服务器的请求。
请务必安装并开启 Chrome 插件: Allow CORS,开启教程可参见
或者以禁用 Web 安全模式启动浏览器,否则下载会失败。
等待链接获取完毕后,你可以复制链接到你自己的下载工具中下载。或直接使用网页在线打包下载。测试地址: tools.hanjihebi.com/gnt/
网址链接批量生成器 (通用打包下载器)
你可以通过规律生成批量的URL列表,也可以粘贴你需要批量下载的URL。然后打包下载~
测试地址: tools.hanjihebi.com/url/
以上工具代码使用了Gemini辅助完成。
欢迎大家测试使用!
另外
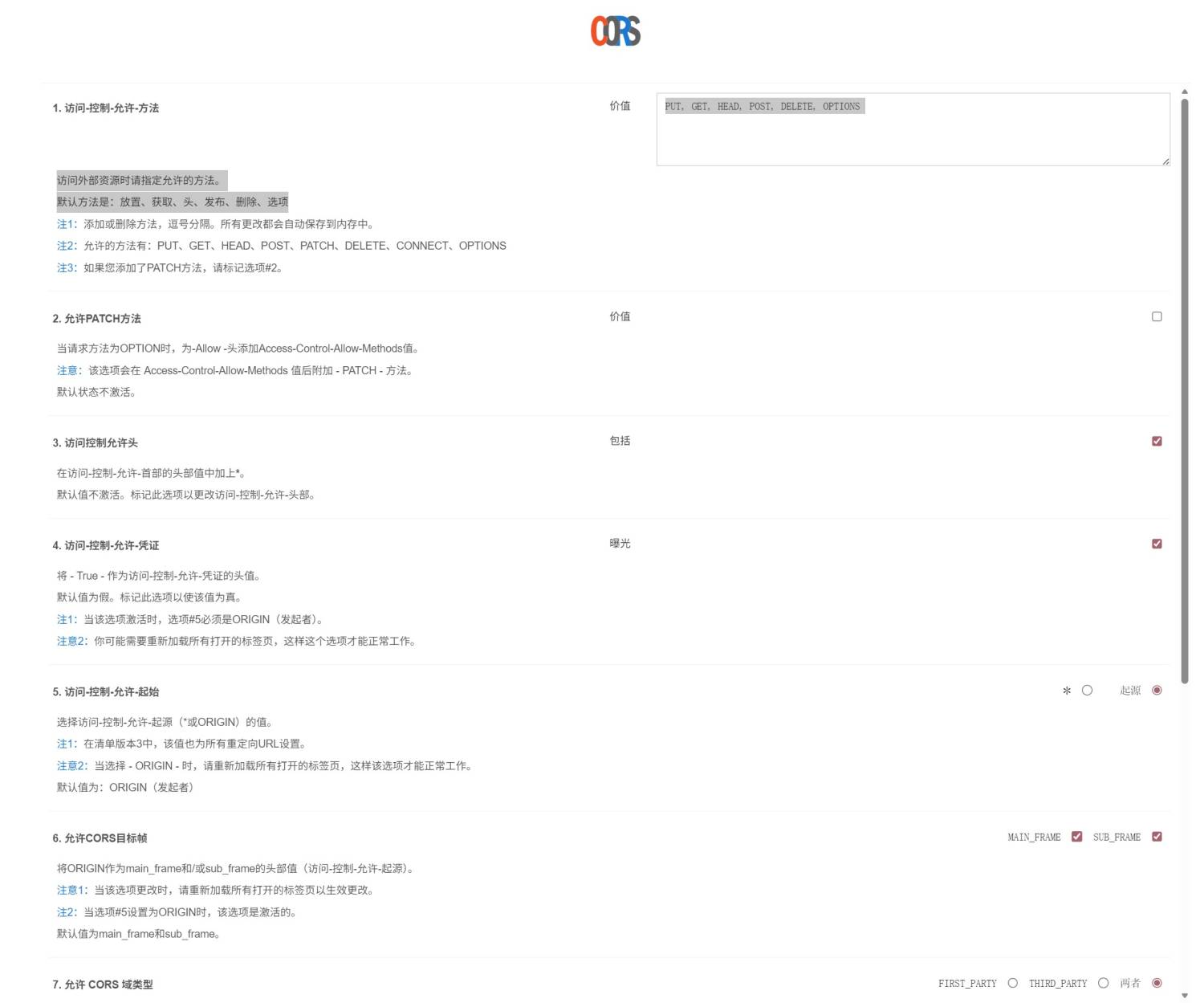
推荐安装插件Allow CORS
由于使用的是纯前端 JS 获取。如果来源没有正确配置 CORS 头(允许跨域访问),浏览器会拦截 JS 的下载请求,并在日志中报错 "Failed to fetch"。
需要安装这个浏览器插件(例如 "Allow CORS")来临时绕过浏览器的限制。
插件(chrome)链接:Allow CORS
edge浏览器也有这个插件,用edge浏览器也是一样的
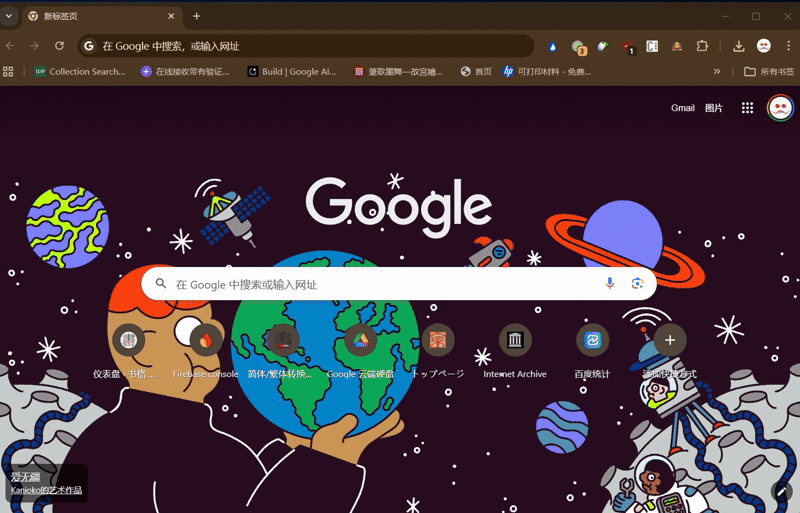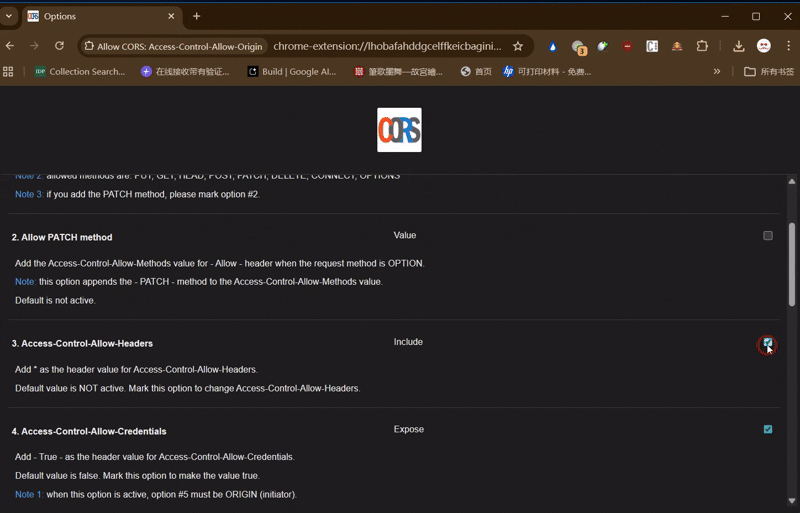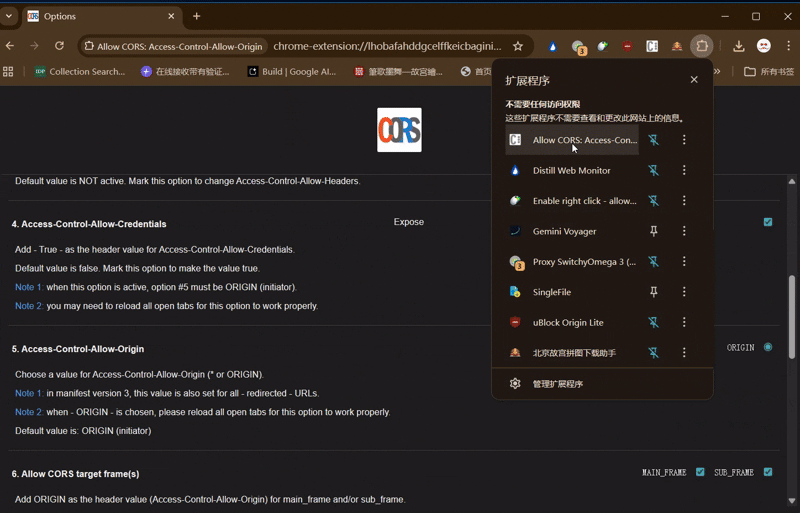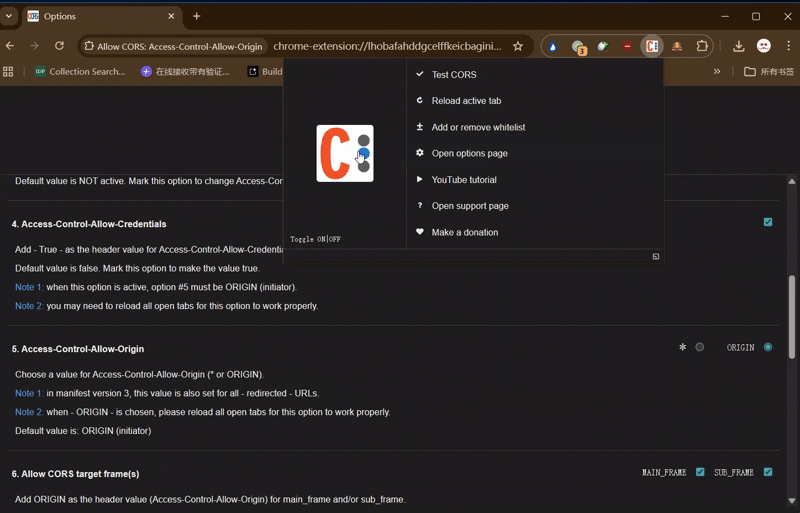
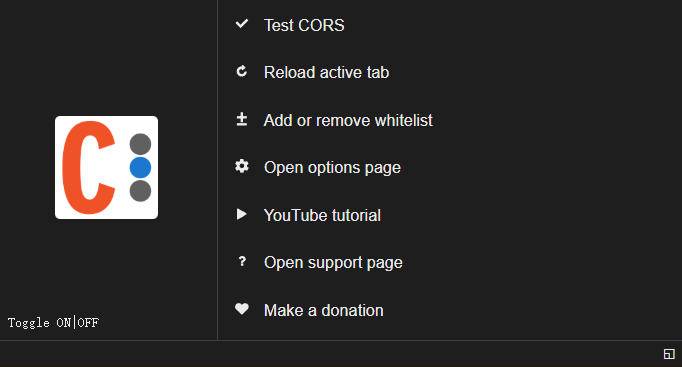
设置参考如图(勾选第3、4项)
打开扩展程序点击左边logo启动插件,变亮则已开启
*如果平时不使用时请关闭插件,图标点成灰色即可(部分网站可能会引起冲突)
玄默游客@未曾 #202463
亲测有效
xiaopengyou游客
未曾管理员@xiaopengyou #202469
这是优化重构过的代码(相较于一月前的版本)。计划统一发布到这里(tools.hanjihebi.com),未来会集成到一个导览页。
夢夢游客用手机浏览器下载了国图一个四十来页的,速度不错。
開物成務游客
xiaopengyou游客@未曾 #202470
了解,謝謝
xiaopengyou游客都是陶淵明學派,好讀書不求甚解!
"国图(中华古籍资源库) "
未曾管理员@開物成務 #202473
中华古籍智慧化服务平台的分页逻辑相对复杂的,我还没开始针对处理。
建议先用bookget处理吧,而且这种分页方式的,还是bookget处理更合适。当然我们未来也会尝试对中华古籍智慧化服务平台支持在线获取。
未曾管理员增加了
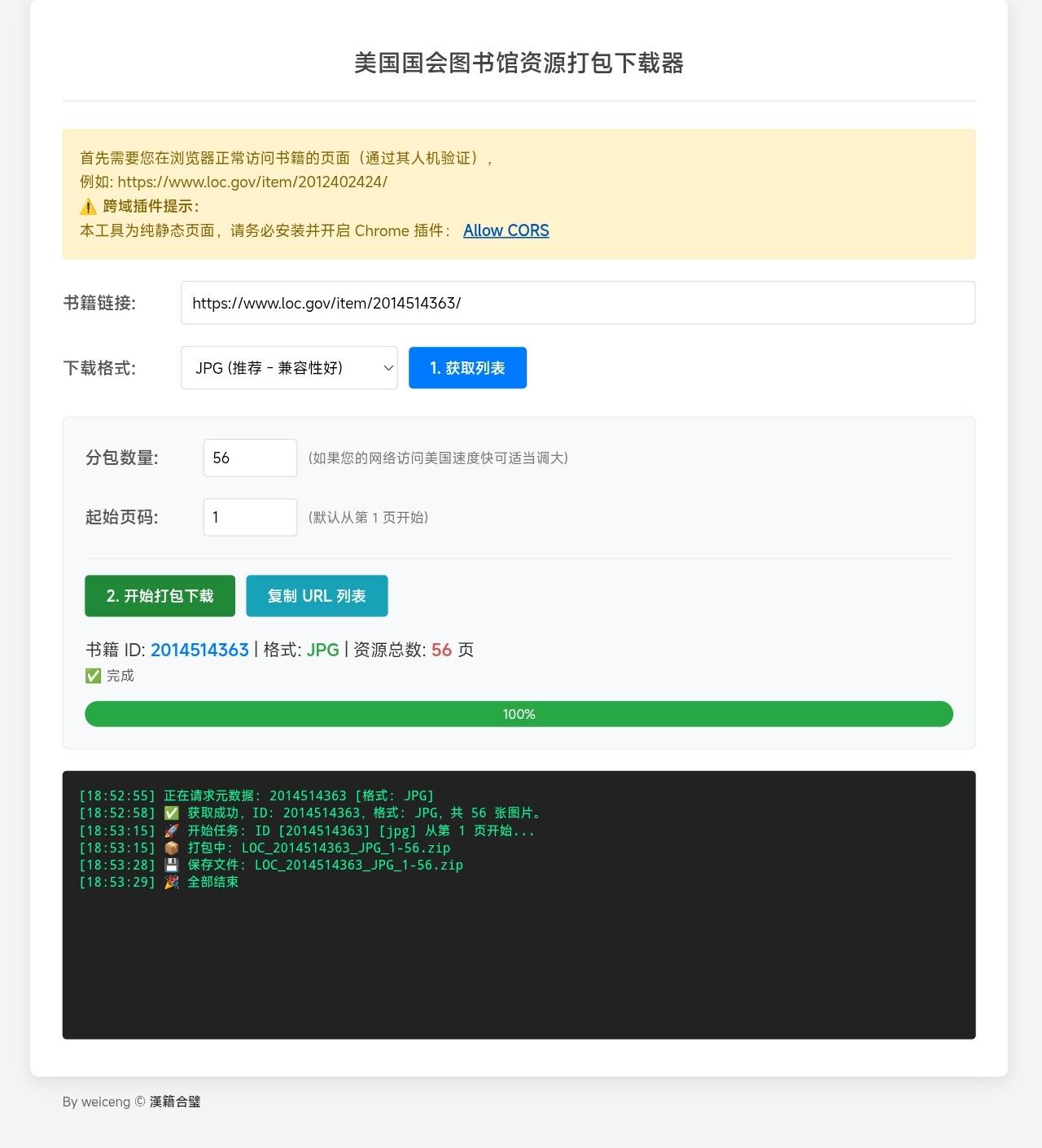
美国国会图书馆资源打包下载器
这个是纯前端实现的,不依赖服务器,但是需要用户浏览器能访问对应资源。需要安装浏览器插件:Allow CORS
测试地址: tools.hanjihebi.com/loc/
鹦山读书人游客感谢未曾先生,美国国会的终于可以下载了。感谢!
书友9527游客太好了,感谢
oldestman游客@未曾 #202485
美國國會的要安裝插件,我上不了谷歌,沒法安裝,有其他解決方法嗎
未曾管理员更新:IIIF 智能下载器
支持自动转换链接: 直接粘贴 Harvard, Gallica (BnF), 国文学研究资料馆 (NIJL) 的阅览页地址,程序会自动转换为 Manifest JSON 地址。
例如哈佛的阅览页 https://iiif.lib.harvard.edu/manifests/view/drs:24623648$1i 法国国家图书馆(Gallica)的阅览页 https://gallica.bnf.fr/ark:/12148/btv1b525041685.r=Chinois%201236?rk=21459;2 国文学研究资料馆的阅览页 https://kokusho.nijl.ac.jp/biblio/300112532/1?ln=en
oldestman游客@未曾 #202608
可以訪問
光游客@未曾 #202609
先生好!哈佛的没挂梯子不能下载对么?
未曾管理员@光 #202710
嗯,这个是纯前端的程序,首先确保你自己能访问哈佛对应的资源。
光游客@未曾 #202713
好的,谢谢!
未曾管理员增加一个测试版:上海图书馆打包下载工具 (半自动解析)
使用方法
首先,用户需要注册上海图书馆的帐户,登录使用。
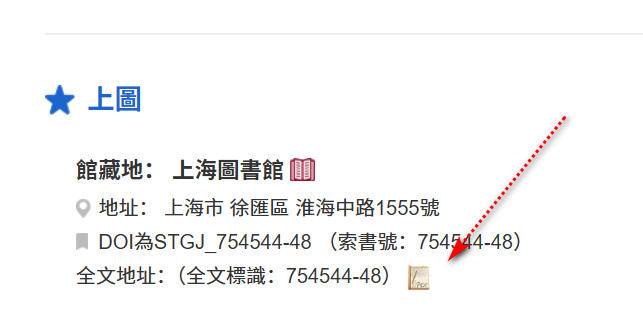
其次,需要官方已公布数字资源在线。大致如图
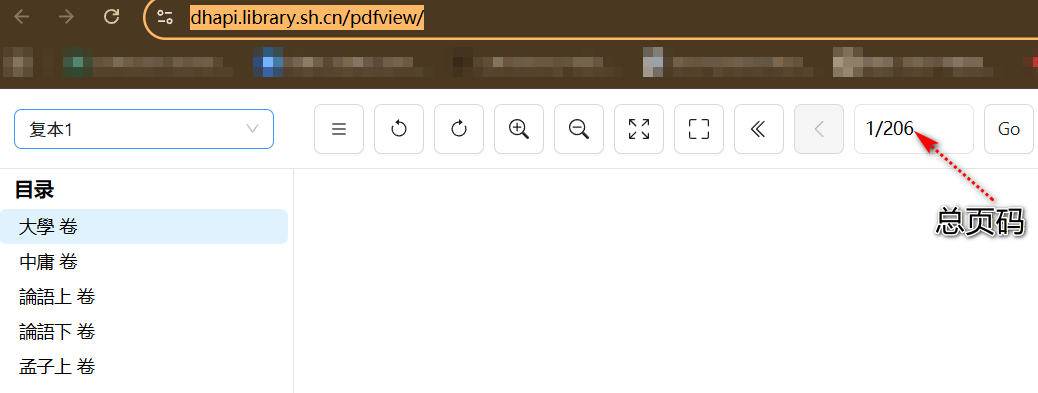
一般打开的书籍页面是:https://dhapi.library.sh.cn/pdfview/,不是早期IIIF资源
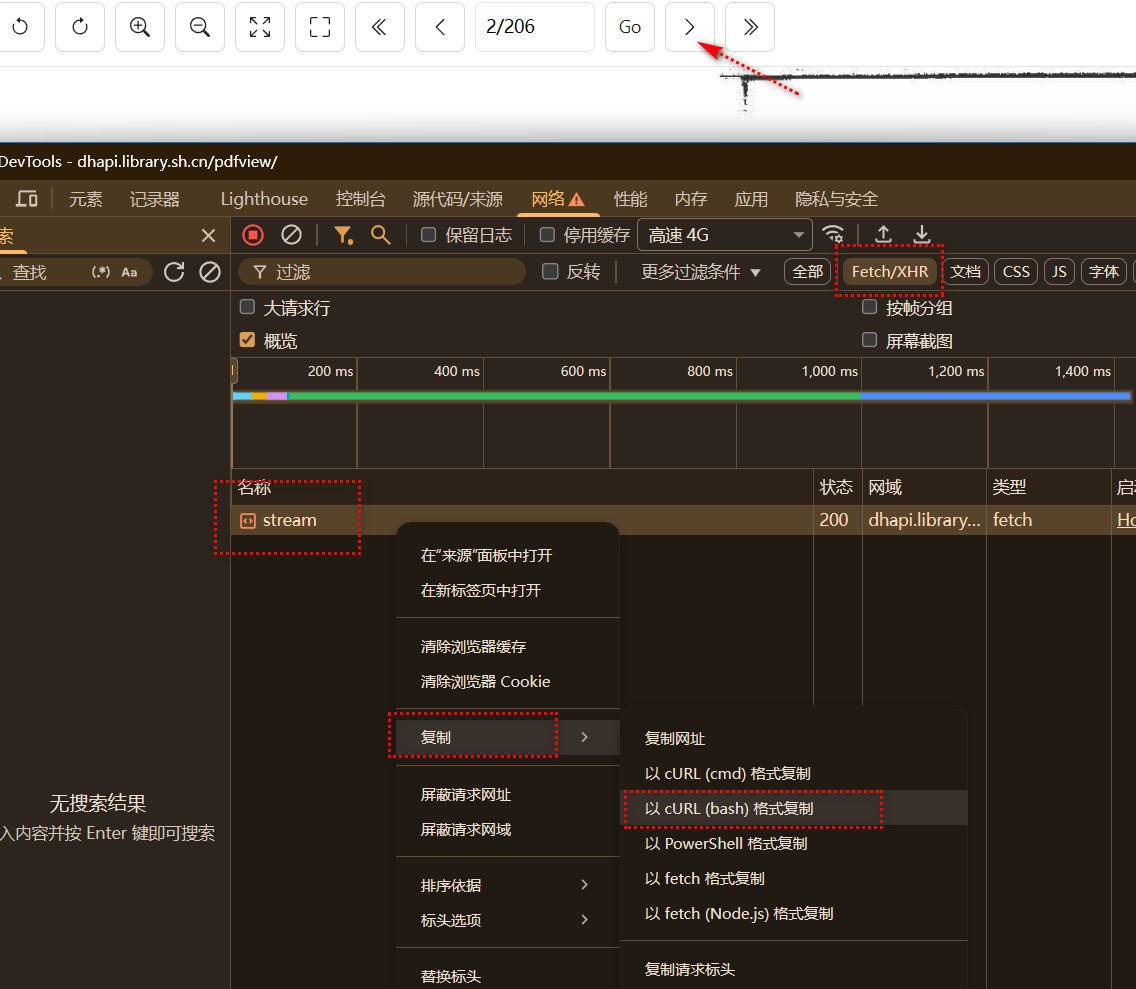
第三,需要手动复制参数,填写总页码。
然后,浏览器按F12进入开发者模式,点下一页(不要刷新页面)复制这里的 cURL 内容
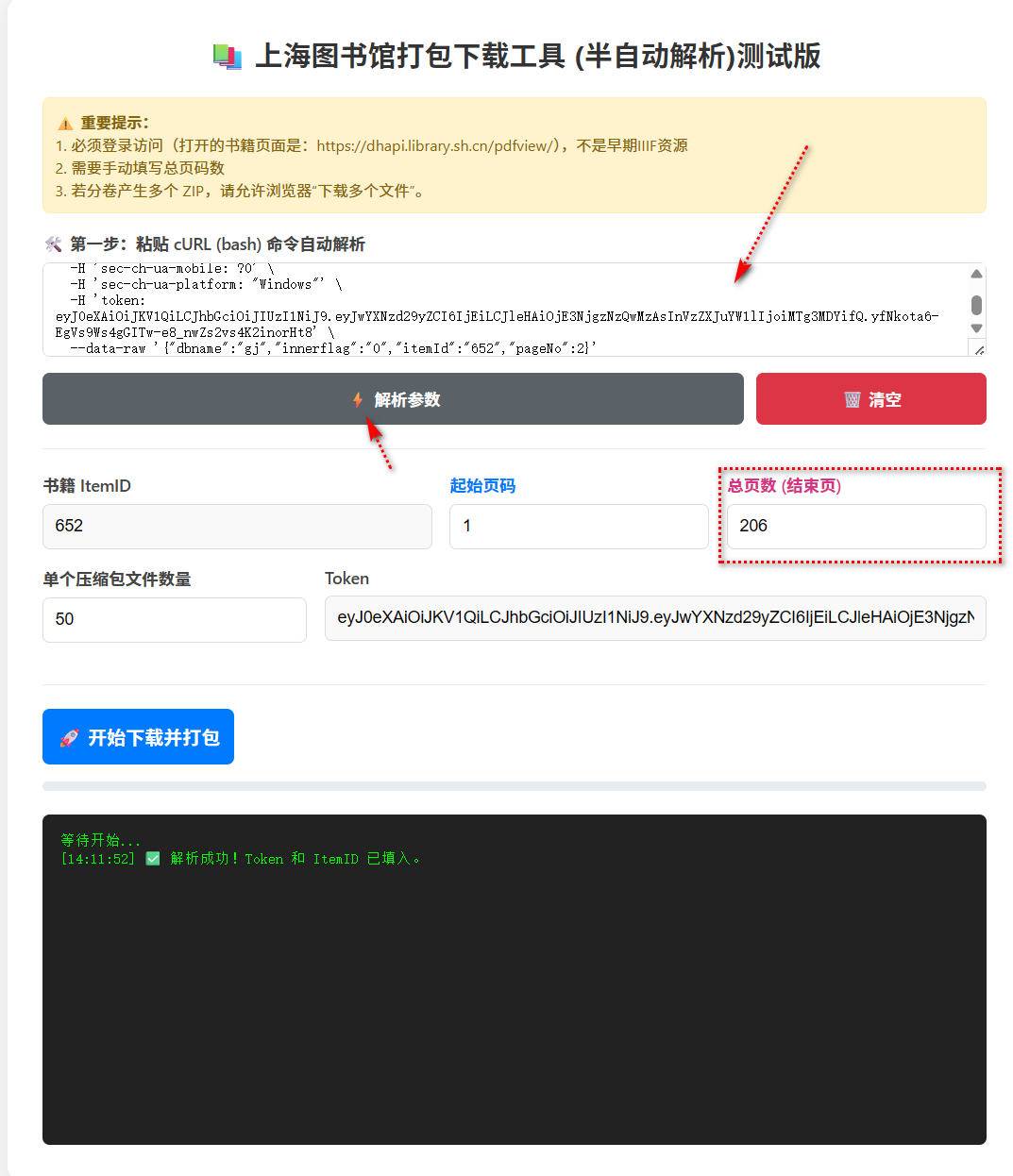
打开测试地址: tools.hanjihebi.com/shtsg/ ,填入以上信息到对应位置
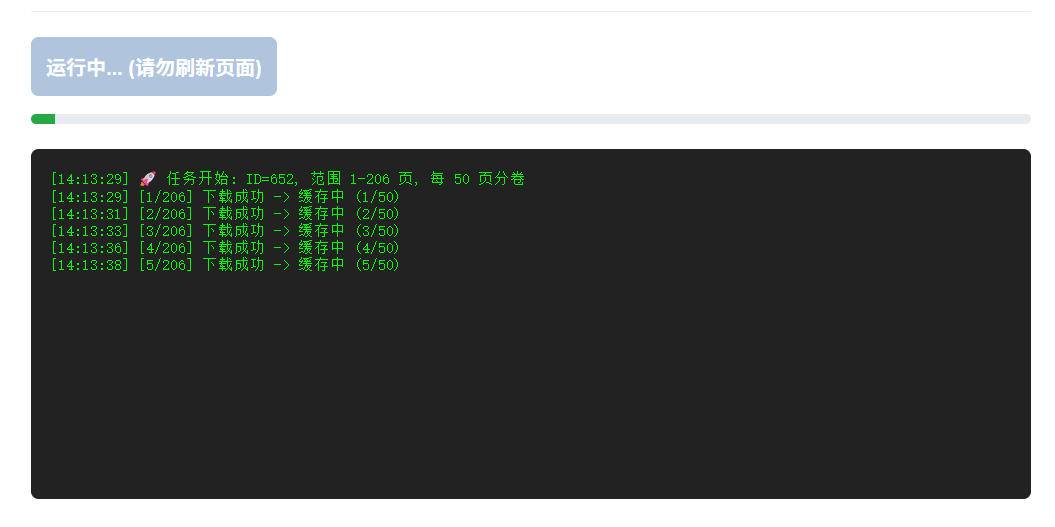
然后点击打包下载,默认50页一个压缩包,如果失败可以更改起始页(从失败的页)
这个是纯前端实现的,不依赖服务器,但是需要用户浏览器能访问对应资源。
这个下载目前使用还是比较繁琐,我还需要研究对应接口,看看还有没有简化的方法。
問路人游客未曾先生,厉害。还是以前那个挺好。就是原来那种,不管新老系统,软件都可以下载高清图,图片再怎么处理成其他文件格式都方便。
辛苦了,大爱无疆,福顺康宁。
未曾管理员@問路人 #202792
抱歉,我没听懂这段描述。什么以前那个?
jsaren游客我估计他说的就是bookget
yuewu游客感谢未曾先生分享这么方便好用的在线工具,最近天一阁新增了一部之前未开放的资源,不知道好不好弄,尝试了bookget现在好像失效了
未曾管理员增加了:天一阁古籍下载打包器
1. 本工具为纯静态页面,由于浏览器默认会拦截对 天一阁网站的跨域请求。
请务必安装并开启 Chrome 插件: Allow CORS
2. 批量下载时,浏览器会连续弹出多个 Zip 下载保存提示,请允许浏览器下载多个文件。
karlie游客用网页打开最后提示> 错误: Cannot read properties of undefined (reading 'replace'),这是什么代码.
karlie游客emuseum.nich.go.jp/iiifa...ifest.json
来个好心人看看能不能把这个链接里的图帮忙下载下来,我完全搞不了,图倒是下载完了,最后打包直接提示错误代码
undefined is not an object (evaluating 'baseName.replace')
未曾管理员@karlie #202889
感谢反馈~已修复
因为兼容性问题导致
它把 manifest.label 当作了传统的 IIIF 2.x 语言映射对象(例如 {"en": ["Title"]})。当它尝试读取数组中第一个元素(那个对象 {"@value":...})的第 [0] 属性时,因为对象不是数组,所以返回了 undefined。
随后这个 undefined 被传给了下载函数,执行 undefined.replace(...) 时就报错了。
問路人游客@未曾 #202793
bookget 挺好用的,个人是碍于电脑系统太低的问题。
jbgy游客WIN7系统 360浏览器,插件已设置,网站正常打开,下载提示错误,请问下这是怎么回事?
ccicc游客你好,未曾先生。感谢您做的网页功能,我在使用国会图书馆下载工具时,用Google chrome浏览器并下载启用了跨域插件,下载网址https://www.loc.gov/item/2014514474/。。。试了好几次,都只能下载前200页的内容,能否帮忙测试一下,看下具体什么原因,谢谢!!!!
未曾管理员@ccicc #203324
我测试是正常的,您的代理服务器是不是不太理想?
————
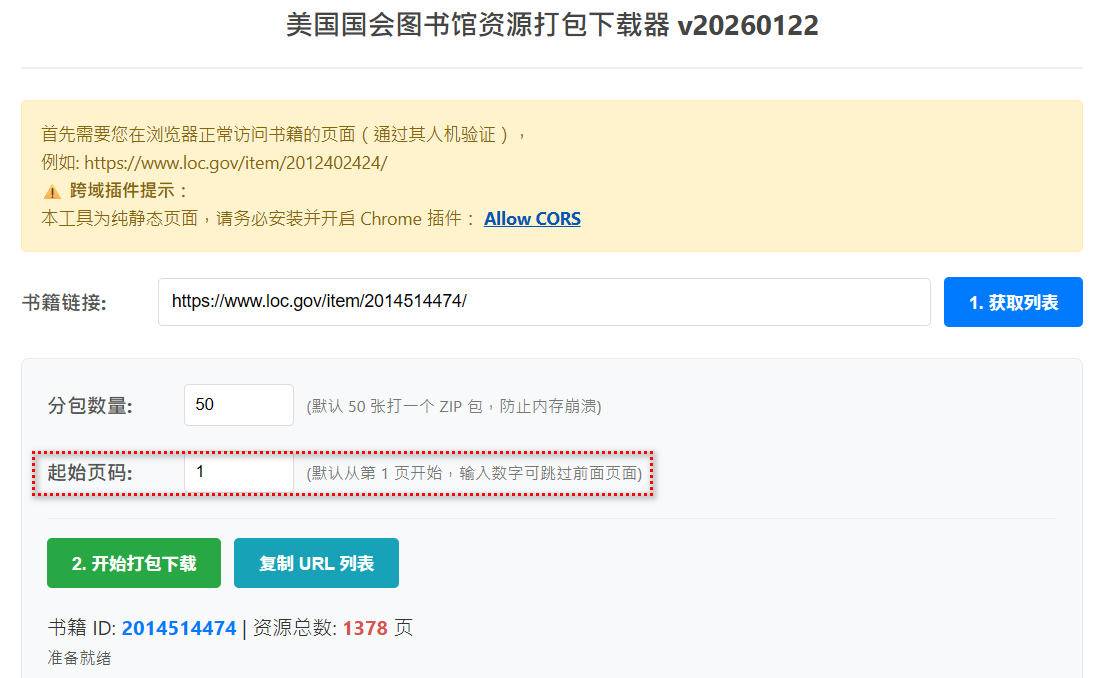
为了避免中途中断重新开始的问题,新增了用户设定起始页的选项,您可以从失败的地方重新开始下载
未曾管理员新增
宫内厅图书寮 - 链接提取与下载
本工具为纯静态页面,浏览器会拦截对宫内厅 服务器的请求。
请务必安装并开启 Chrome 插件: Allow CORS,开启教程可参见
或者以禁用 Web 安全模式启动浏览器,否则下载会失败。
等待链接获取完毕后,你可以复制链接到你自己的下载工具中下载。或直接使用网页在线打包下载。测试地址: tools.hanjihebi.com/gnt/
未曾管理员
谢耳朵游客哈哈我这几天还在想自己做一个,你已经实现了。
可不可以集成到一个网页?根据网址决定后面的逻辑?
另外是否考虑开源不同网站的解析、下载逻辑?这样大家都可以帮忙添加、维护新的网站。我最近刚刚帮bookget增加了甘肃图书馆和InternetArchive。
未曾管理员@谢耳朵 #203467
嗯,集成到一个网页是最终的逻辑~
考虑到目前阶段是对各个适配,可能会有大量修改调整,一个个处理相对不容易出错。
等测试到稳定期会整合集成到通过URL自动分析调用对应接口
另外是否考虑开源不同网站的解析、下载逻辑?
目前都是JS+HTML纯前端代码实现的。源码就是右键的源代码~
未曾管理员将这些工具列表到一个网页了
xiaopengyou游客
海鹰游客请教这种怎么批量下载?
CHEN游客增加古籍與特藏文獻資源 - 國家圖書館吗?这个站的用bookget-gui只能下载90页以内的,超过不能刷新翻页。
当归黄芪游客@未曾 请教未曾,我的怎么获取不了呢
未曾管理员
剔藓扫尘游客请问未曾兄这是什么情况?安装的edge和firefox版都这样显示
未曾管理员@剔藓扫尘 #204171
Allow CORS插件安装启用了吗
剔藓扫尘游客
未曾管理员
剔藓扫尘游客
未曾管理员@剔藓扫尘 #204178
你的代理IP不太理想
ihuang游客@未曾,为什么我上海图书馆下载都是0字节?
未曾管理员@ihuang #204329
请举例
- 作者帖子
 WIN7系统 360浏览器,插件已设置,网站正常打开,下载提示错误,请问下这是怎么回事?
WIN7系统 360浏览器,插件已设置,网站正常打开,下载提示错误,请问下这是怎么回事?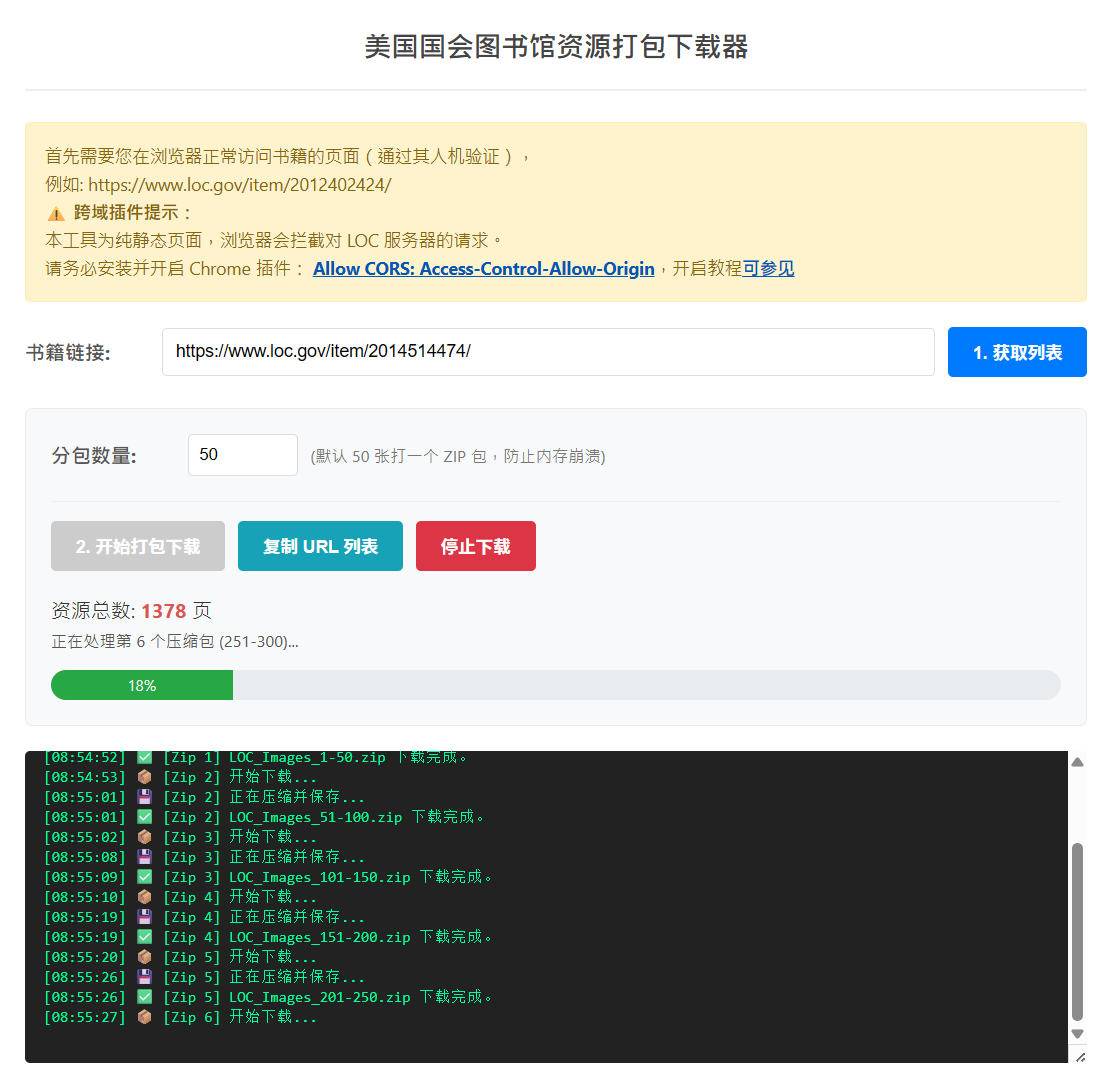
 )
)图书馆推荐
近期回复
-
 xiaopengyou 在 关于叶逢春本《通俗演义三国志史传》的缺卷
xiaopengyou 在 关于叶逢春本《通俗演义三国志史传》的缺卷 - 米科 在 求:高峰文集十七卷
- 未曾 在 求:高峰文集十七卷
- xiaopengyou 在 求:高峰文集十七卷
- Michwzh 在 求国家艺术档案的“朝元图(永乐宫三清殿壁画)全图”
- 米科 在 求:高峰文集十七卷
- 未曾 在 求:高峰文集十七卷
- 未曾 在 【测试】几个在线资源下载工具
博物馆推荐
公众号:书格

关注了解最新动态
每个人都能自由地看到我们的文明
书格致力于开放式分享、介绍公共版权领域的数字资源
CC BY 4.0:知识共享 署名 4.0 国际