- 作者帖子

何足道游客偶然看到朋友分享的这个页面系统,网址: ocr.ancientbooks.cn/index
试了一下,感觉挺好用。

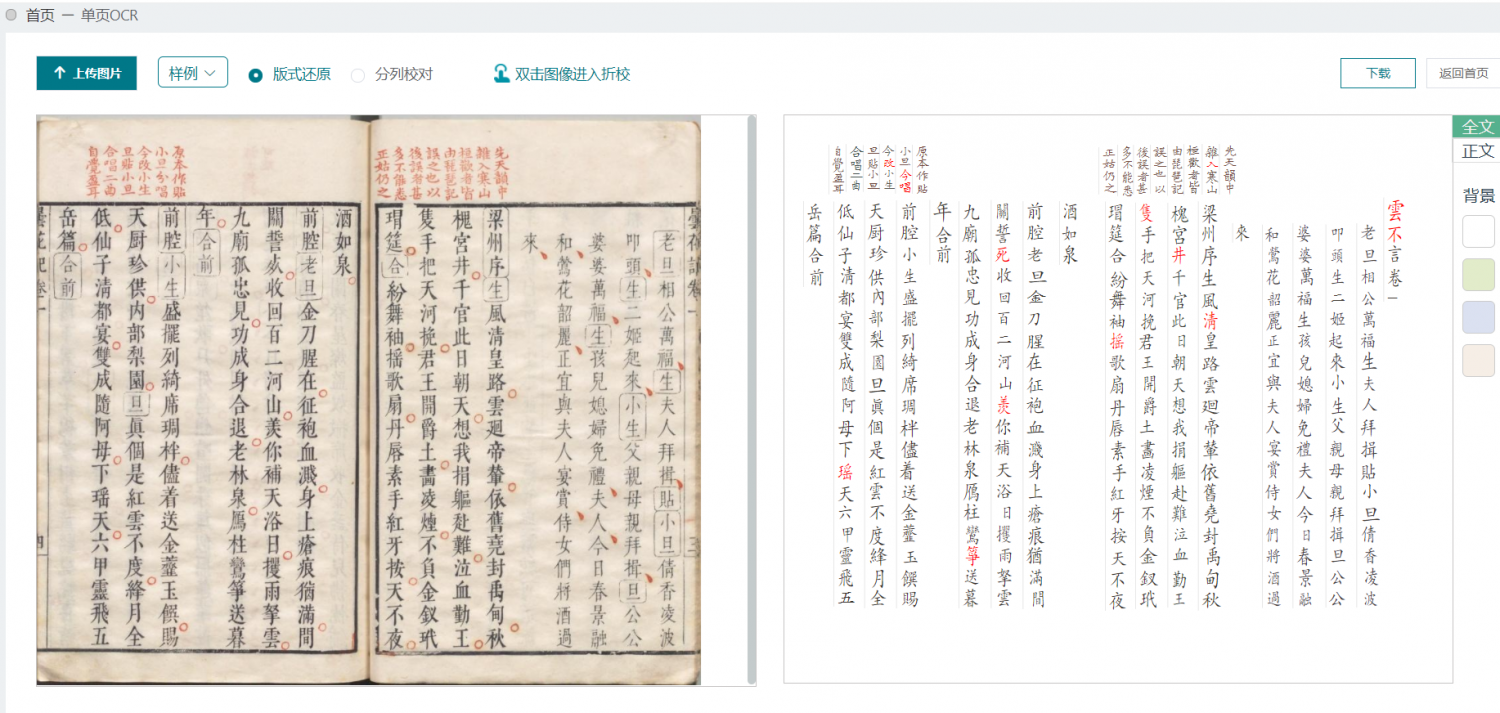
可以识别刻本,正确率颇高,识别手写本稍微困难一些。眉批、注解等部位也能识别出来,而且格式不乱。
还有非常惊艳的“分行校对”功能,可以把古籍页面的文字按列切割成长条,所识别的文字附在一侧,两下对照着进行人工校对,直观而又便捷,效率极大提高。
最后可以导出word文件。不过,句读还得人工添加。而且试用期只有100页的权限,超过了要收费,费用还不算低。但如果真有需要的话,还是值得的,毕竟节省太多录入时间。
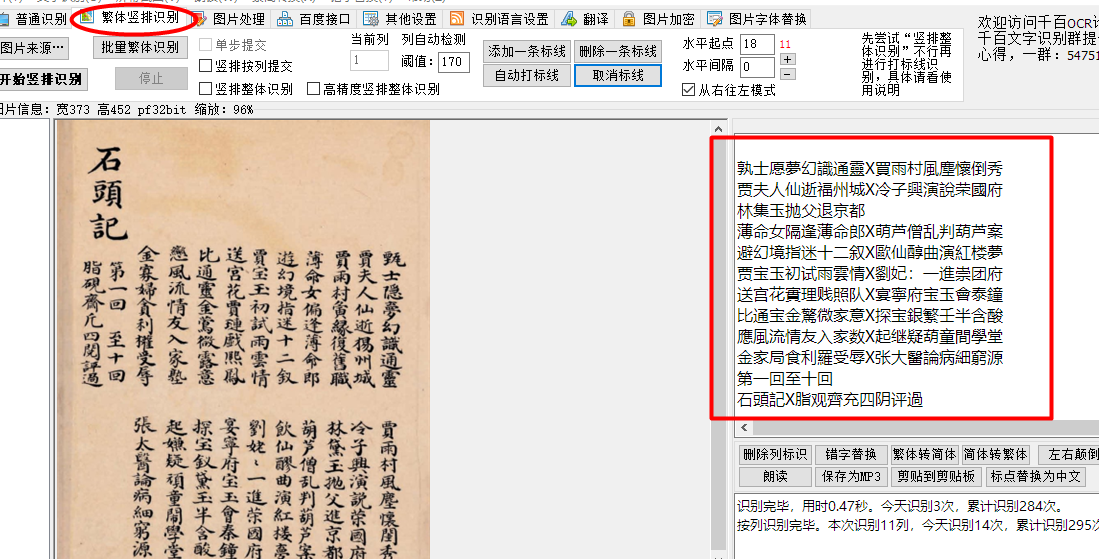
崇鹂游客感谢分享,我以前用过一个叫《千百图片文字识别》的软件,也是繁体竖排古籍的,好像是用百度的接口,只是批量识别比较麻烦,但是每天可以识别500页(图)次日更新,算是免费里比较好了。
直接识别效果如图
画格子后的效果图
最后放弃使用,是因为:
1、限制比较大,可能是明刻风格比较能识别,手写体错误太多。如果是现代繁体出版物,可识别的OCR就很多了,我习惯用ABBYY了,也很强大、破解版也免费。就是说古籍类OCR强大免费的软件还是少的。
2、最要命的是,我对当前OCR技术不信任,保不住哪里蹦出一个错误。其实还是要多次目验。
例如ABBYY批量识别(适合现代繁体出版物),随便放一本书(其实也不随便,简、繁、俗、异混合的清人抄本),玉字,机器就没发现错误,可能我这种不联网的更渣吧
崇鹂游客但ABBYY在现代繁体出版物上,是真的强大
未曾管理员其实 阿里的 汉典重光 识别效果很好,免费又没页数限制
何足道游客@未曾 #78834
没看到汉典重光有识别的页面啊
未曾管理员@何足道 #78932
需要登录进去使用,用阿里的账户就行
麻黄游客根据既往群里的推荐,用了白描还不错,为此买了黄金会员。
会的小猪游客@何足道 #78721
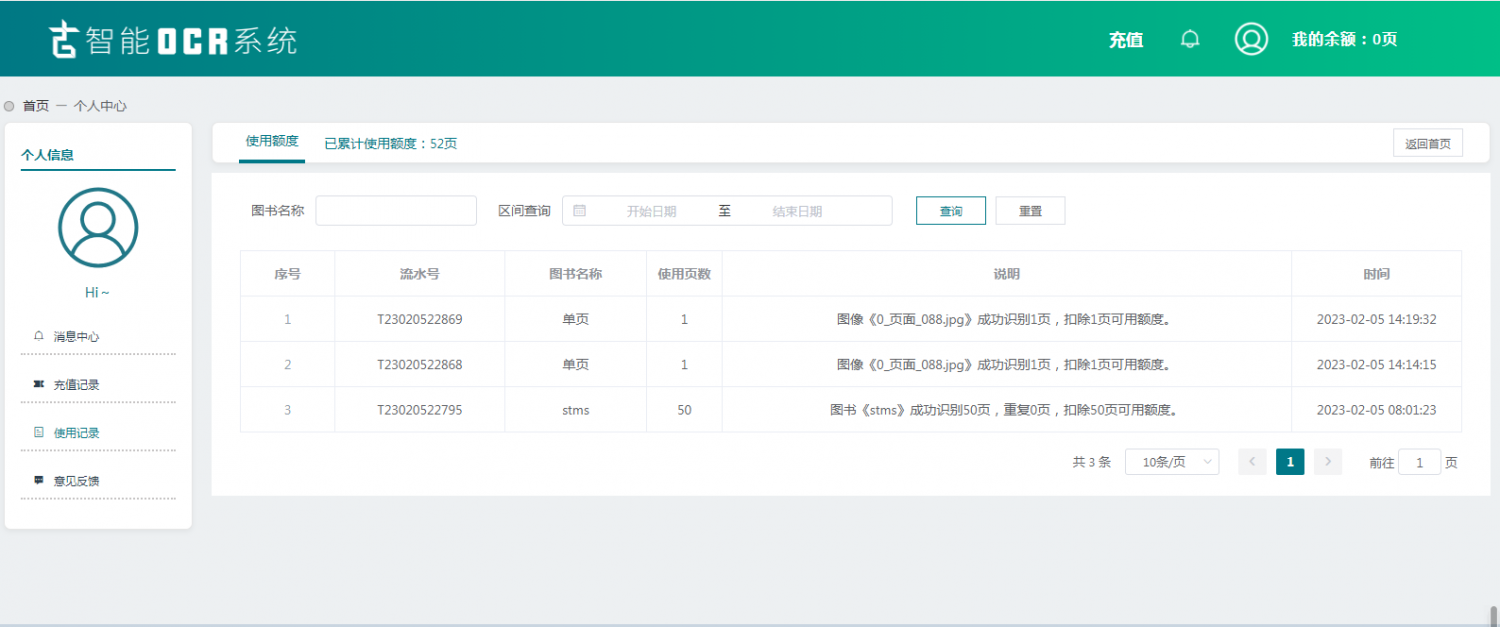
這個真的很不錯,就是價格太貴了。。。。。。
会的小猪游客送的100頁,只用了52頁就,剩餘頁數全部清空了,所以這個軟件還是有危險的
小古游客@会的小猪 #79015
您好~我是古联智能OCR的工作人员,很抱歉之前系统出现了这种问题给您带来不好的体验,我们后台查询看到您的问题当时得到了解决,但还是希望能与您建立联系,这样以后能更及时地接收到您的意见与反馈,更快地处理。欢迎您点击网页底部的意见反馈或直接添加网页上工作人员的联系方式,期待您的来信~
cngz游客有没有能把原来的纸面线条及字样抠出来,按原样排版,细微调整修正,而不是变成电脑字,有这样的工具吗?
cngz游客排版成可以L+R直接方便打印的
式盘研究游客@小古 #115560
能不能给书友们多送点
阿雅阿雅游客古联OCR识别后,下载,但出现的是乱码。不解
书友游客用金鸣识别呀,有竖排文字识别,点击“文字识别”,下拉选择“竖排文字”即可,有在线版,也有软件版。https://www.jm189.cn
学惭淹贯游客@书友 #170179
收费的还是算了吧。
蝈蝈游客还有别的吗?欢迎推荐古籍ocr平台
砯斋游客@蝈蝈 #170188
识典古籍
红景天游客刚刚试过,不好用,费用好贵,OCR识别后,繁体转简体,又要收费,太贵了。
效果还没有豆包大模型快,也没有豆包识别效果好。我用的豆包大模型免费版,直接转换成简体还是横版输出,准确率高,还是免费啊。
2025-8-15日测试。
其它转换工具也试了下,也要收费,也是好贵的。
红景天游客- 作者帖子
正在查看 20 个帖子:1-20 (共 20 个帖子)





正在查看 20 个帖子:1-20 (共 20 个帖子)
正在查看 20 个帖子:1-20 (共 20 个帖子)
