正在查看 7 个帖子:1-7 (共 7 个帖子)
- 作者帖子

崇鹂游客例如:
jsg.aks.ac.kr/viewe...dataId=001

我之前都是F12,然后一页页由头点击到尾,由此获取到每一页的.xml文件,然后用dezoomify-rs批量拼接下载的。
但这样搞一两册还行,搞几十册就浪费生命了,故咨询各位大佬
xiaopengyou游客簡單填一下資料,就有自動發送圖書館自生成的全冊PDF
搜一下交流區。
崇鹂游客
未曾管理员@崇鹂 #137657
那个xml前的名字和缩略图的名字是一样的。提取缩略图地址,批量替换一下就行~
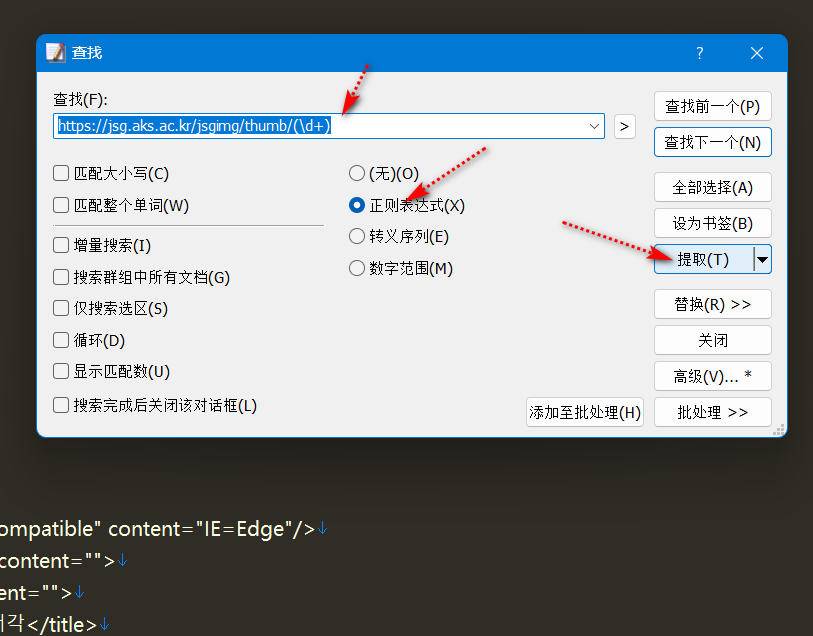
可以使用EmEditor提取对于url,复制源代码到EmEditor
提取规则https://jsg.aks.ac.kr/jsgimg/thumb/(\d+)
如图

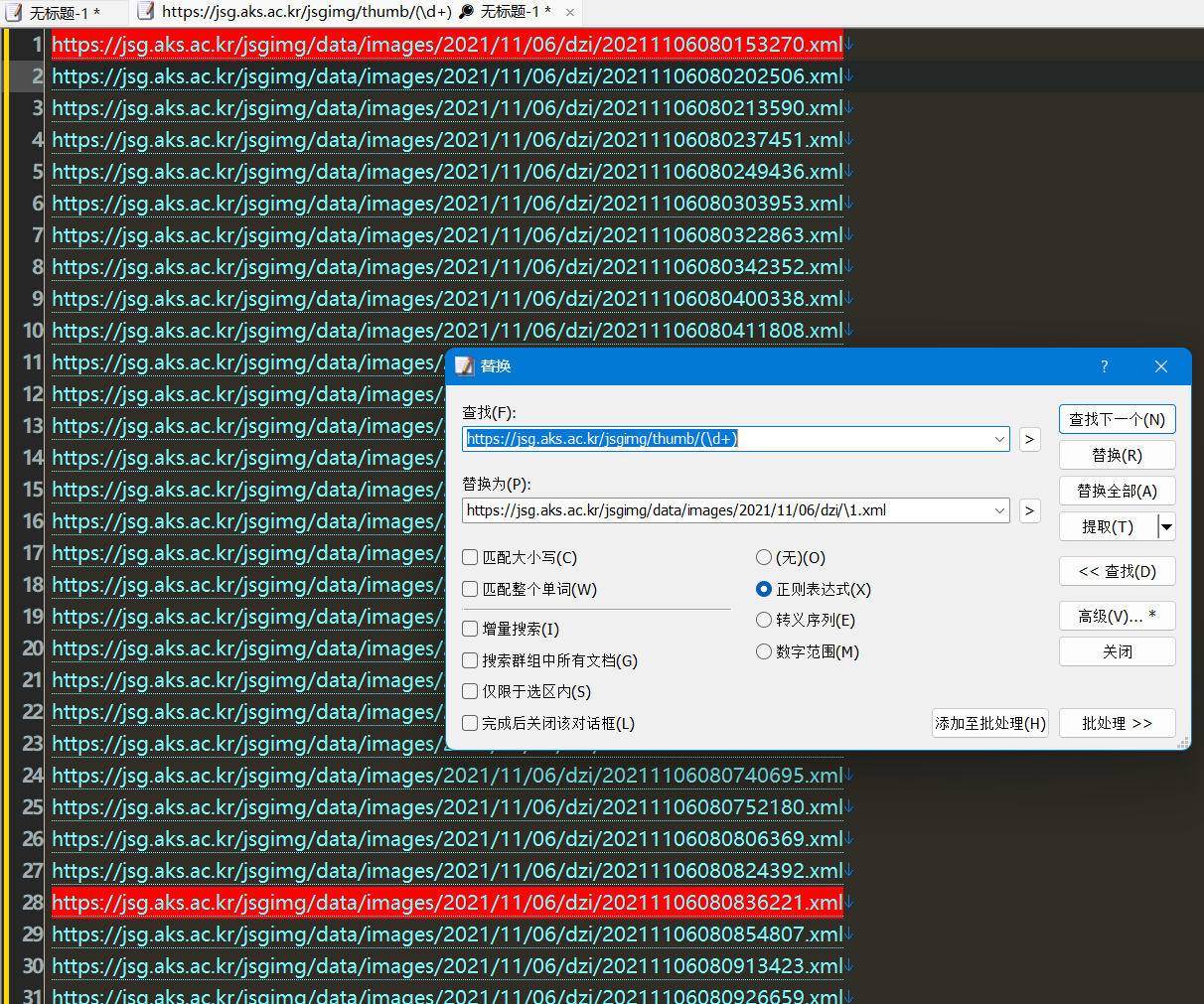
然后将提取的结果:替换》批量替换,规则为
查找
https://jsg.aks.ac.kr/jsgimg/thumb/(\d+)
替换为\1表示上面地址中正则的结果
https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/\1.xml
如图
得到结果
https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106080153270.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106080202506.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106080213590.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106080237451.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106080249436.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106080303953.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106080322863.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106080342352.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106080400338.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106080411808.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106080425841.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106080443253.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106080504275.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106080516839.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106080531262.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106080543892.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106080555628.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106080611649.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106080625134.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106080642682.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106080700972.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106080713005.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106080726710.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106080740695.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106080752180.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106080806369.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106080824392.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106080836221.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106080854807.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106080913423.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106080926659.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106080944273.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106080955805.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106081009198.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106081020245.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106081044718.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106081057687.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106081112631.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106081128727.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106081141040.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106081154182.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106081207199.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106081218732.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106081231141.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106081243410.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106081257427.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106081355378.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106081410710.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106081432529.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106081451264.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106081506331.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106081518129.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106081529789.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106081543305.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106081600284.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106081616160.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106081703273.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106081716227.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106081735854.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106081747652.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106081805502.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106081820034.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106081831785.xml https://jsg.aks.ac.kr/jsgimg/data/images/2021/11/06/dzi/20211106081849526.xml
然后可以使用批量下载的脚本获取
xiaopengyou游客
小透明游客用python 获取 xml 列表比较简单,但我不理解怎么用 xml文件这个下载图片
代码如下,替换相应的书籍地址,运行成功会在代码所在文件夹,生成系统时间命名的txt文件。
from bs4 import BeautifulSoup import re import requests import json import datetime #替换相应的 书籍地址即可 url ="https://jsg.aks.ac.kr/viewer/viewIMok?dataId=K3-325%7C001#node?depth=2&upPath=001&dataId=001" response = requests.get(url) soup = BeautifulSoup(response.content, 'html.parser') # find all <script>标签 script_tags = soup.find_all('script') img_id = [] # 遍历<script>标签 for script in script_tags: # 提取<script>标签中的文本内容 script_content = script.text # 用正则表达 做判断 match = re.search(r'var dataJSon =', script_content) if match: m = re.search(r'imgItems: (\[.*?\])', script_content, re.MULTILINE) if not m: continue data_json_str = m.group(1) # 制作json格式 data_json_str = '{"imgItems": ' + data_json_str + '}' data_json_str = json.loads(data_json_str) img_items = data_json_str['imgItems'] dict_img = [] for item in img_items: imgid = item['imgID'] dzi = imgid[0:4] + '/' + imgid[4:6] + '/' + imgid[6:8] +'/dzi/'+imgid+'.xml' url_file = 'https://jsg.aks.ac.kr/jsgimg/data/images/'+ dzi #print(url_file) dict_img.append(url_file) # 获取当前系统时间 current_time = datetime.datetime.now() # 格式化时间 file_name = current_time.strftime("%Y%m%d-%H%M") + ".txt" with open(file_name, 'w', encoding='utf-8') as file: file.writelines(dict_img) print("文件已写入:", file_name)- 作者帖子
正在查看 7 个帖子:1-7 (共 7 个帖子)
正在查看 7 个帖子:1-7 (共 7 个帖子)
