- 作者帖子

唐象游客在遇到古本当中有某个生僻字的时候,如果一时难以解决。不妨先搁置,先往下看。因为往往,在后面,如果同样出现这个生僻字,但因为在后文当中,是在一个特定术语里面,所以一猜就能猜到这个字是什么字。然后再反推到前面那个生僻字。
这样做的好处,是同样的一个本子,用自己本子上的字去解自己本子上的字,最精准。
如果刚开始就直接采用多种其他方式去查这个字,有时可能要花很多精力才能查到。即便查到,可能有些细节还不一样,不敢一时确定下来。
爱读书游客感谢分享阅读古籍的技巧,确实经验之谈。
三河冯威游客@唐象 #15930
如果 只出现一次呢?
唐象游客@三河冯威 #15941
个人常用方法:
一、https://www.zdic.net/,汉典网,字库比较齐全。
查询的方法上,对于生僻字,比较常用的有:
1、右上角「汉字拆分查询」。选择字型结构,然后依顺序输入各个部件,看是否能够查到。如果不行,还有一个技巧。比如左右结构的字,左边不好输入,但右边是确定的。这个时候,输入的时候,不要选字型结构,直接输入右半部分。就会跳出来所有包含这个部件的字,然后再细查。
2、字典部首索引。这个和以前查新华字典差不多,先确定一个部首,然后看剩下是多少画,再直接到多少画里面去找。要一个一个仔细找。看有没有。
3、总笔画索引。这个藏得深,要先点到汉语字典,字典检索里,总笔画索引。这个字有多少划,就选到那里。这种情况,适用于特别难查的字。只有通过花更多时间精力,一个一个去找过去。
二、猜字法。
根据上下文意,自己尝试去猜一下,字看多了一般会有一种直觉,就是字型比较相近,会天然跳出几种可能的字。然后到汉典输入这个字的简体。
然后选择“字源字型”,去比对一下,是不是出现了一模一样的生僻字,如果出现了,那说明猜对了。如果没有出现,可能猜错了,或者字库不全。有些字可能字库里都没有。
三、替换部首法
有些字的部首,熟悉以后,某个字以前这个部首这样写,换到另一个字,还是这个部首,就可以尝试去替换,看看是不是会有灵感。
个人不常用方法,但思路上应该是可行的。
一、手写法。用鼠标写出这个字,然后系统可以直接去辨别。信息技术应该是可行的,但只是要找到非常优秀的生僻字查询系统,有这个功能就可以。现在主要不是信息技术问题,而是字库的问题。手机上比如百度输入法等等运用了人工智能技术的输入法,普通字的手写的识别率已经非常高了。
二、笔划输入法。中华书局古联输入法http://www.ancientbooks.cn/helpcore?input
其中有直接输入横竖撇捺折,然后找字。但不知字库是否充足。如果字库充足的话,这样去找会方便很多,前提是要掌握正确的书写笔划,可以多试试。
三、AI识别。AI识别,一定是生僻字识别的未来。http://codh.rois.ac.jp/,这个日本网站,有这样的技术框架。并运用在了古日文的识别上。将来随着AI古汉字识别技术发展,生僻字识别,应该不会是门槛。有待技术人员开发成熟,那会大大降低阅读古籍的文字门槛。
唐象游客AI图像识别。已经找到了。https://mojizo.nabunken.go.jp/
上传图像后选择解析,就可以了。
测试过,效果并不理想。几个较难的字,目前识别不出,简单的字能够识别出来。
说明技术本身慢慢在成熟,只是字库扩充的问题,这只有靠时间,数据库大了以后,自然准确率就提高了。
三河冯威游客@唐象 #15942
谢谢
唐象游客
gsyrzjy游客查字的话,异体字字典比汉典多,国学大师网字典有草书功能
墓鬼游客我来问一个字
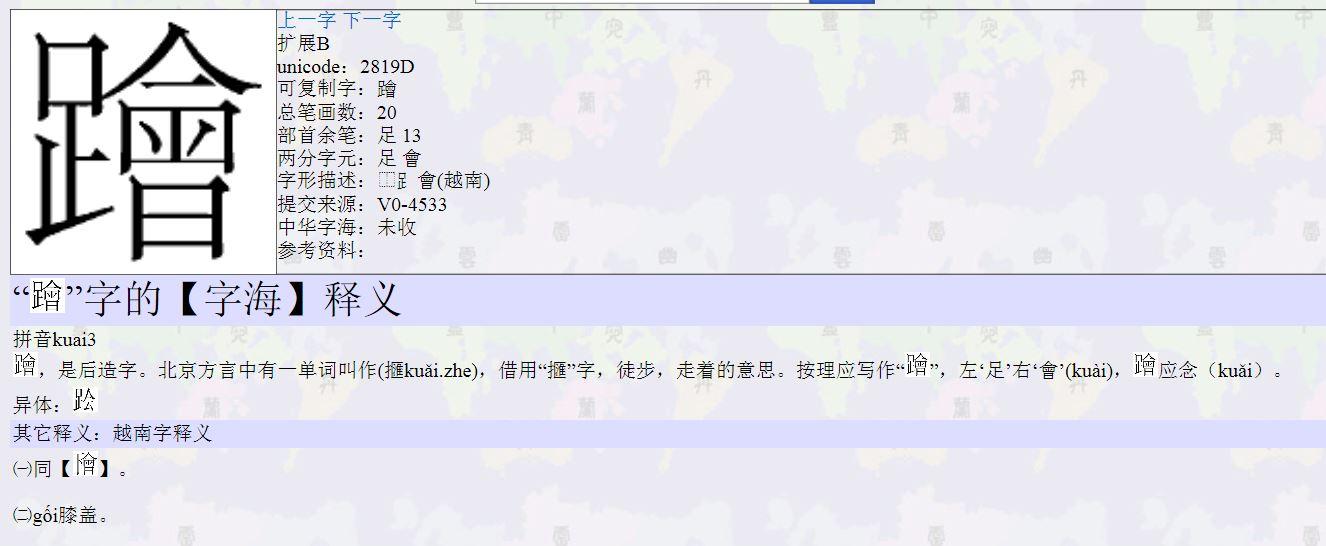
 ,上㑹下足。
,上㑹下足。
gsyrzjy游客@墓鬼 #15994
叶典
拼音kuai3𨆝,是后造字。北京方言中有一单词叫作(擓kuǎi.zhe),借用“擓”字,徒步,走着的意思。按理应写作“𨆝”,左‘足’右‘會’(kuài),𨆝应念(kuǎi)。
异体:(缺字)
喃字
㈠同“𠁚”
㈡gối 膝盖。
gsyrzjy游客厉害,第一次知道叶典!异体字典没有该字,汉典有三分之一,国学大师字典有三分之二
墓鬼游客从文义看,不是动词、名词,用𨆝来解释不通。
唐象游客叶典网:http://yedict.com/
我测试了一下。上㑹下足。在汉典当中,不论是上下结构,还是左右结构,都找不到。
但在叶典网,却能够找到。
果然,最后拼的是大数据。数据库的庞大最重要。信息技术这方面,几乎是差不多的。
唐象游客
唐象游客用AI图像识别也测试了一下。解析时间比较长,并且最终没有出现任何一个有效结果。
看来,AI图像识别,虽然特别方便。但是算力不足导致查询时间长,这是一个问题。当然这个问题还尚且可以克服。
但最要命的,仍然是数据量的问题。数量量太小的话,什么查询方法都没有用。
如果有AI图像识别+叶典网的大数据。这样将来出现的查生僻字的,一定非常强大。
墓鬼游客可能是生造字,“會”添“足”,还是“會”字。
gsyrzjy游客@墓鬼 #16011
你这好象是宋本,查查同名书的其它版本,比如元本、明本,特别是四库本,还有现代本,说不一定有人把生僻字改成通俗字了
gsyrzjy游客元明时有一个收俗字最多的书,我忘了
convoi游客我用IDS找字:https://www.babelstone.co.uk/CJK/IDS.TXT,它覆蓋了標準-擴展G的所有已編碼漢字。
如果你發現有找不到的字,可以到維基文庫留言給我:
zh.wikisource.org/wiki/...lk:Jlhwung
對於古籍中未編碼漢字,我可以聯繫IRG專家進行整理,例如
wikisource.org/wiki/...BabelStone
這些字以後都有可能會納入到Unicode編碼中。
未曾管理员@convoi #16171
感谢维基大咖~
唐象游客微软日文输入法,自带手写识别。
Windows操作系统,安装微软自带的日文输入法后,其中带有一个手写板功能。
这个手写板,不仅可以用来输入日文,有些复杂的汉字,也可以输入出来。
比如“叅”字。同“参”字。但是通过其他方式,我没有能够成功找到这个字。最后是通过这个微软自带的日文输入法,手写板功能,成功输入出来了。
猫猫虫游客请问这个字是什么?木字旁加一个邉,木邉
歪桃游客普通的生僻字可以学一下四角号码,打起来还是挺方便的。书局的输入法也可以部件组合输入,一般的生僻字都能解决。
xiaoyuz游客感谢分享
- 作者帖子
正在查看 24 个帖子:1-24 (共 24 个帖子)
 ,上㑹下足。
,上㑹下足。
正在查看 24 个帖子:1-24 (共 24 个帖子)
正在查看 24 个帖子:1-24 (共 24 个帖子)
