- 作者帖子

谢耳朵游客我最近在搜索红楼梦不同版本的数字资源。这个过程中碰到了很多问题。第一是高清的图片资源很难找,尤其是一些比较冷僻的版本。文字资源就更少,而且都有些错误。第二是即使找到了一些影印本,也很难确定它到底是从哪一个版本而影印来的。网站上的介绍都很模糊而且往往不准确。
我总是要搜索很多个网站才能够找到高质量的影印本或者文字。有的时候它又会藏在谷歌搜索的后几页,或者论坛的某个回复里。
所以我萌生了一个想法:是不是可以做一个开源的古籍资源的索引网站。给每一本古籍发一个ID,然后通过自动化的信息收集+社区维护的方式,不断更新和校对它的基本信息、收藏历史、文字图片资源、和其他版本的联系等等。
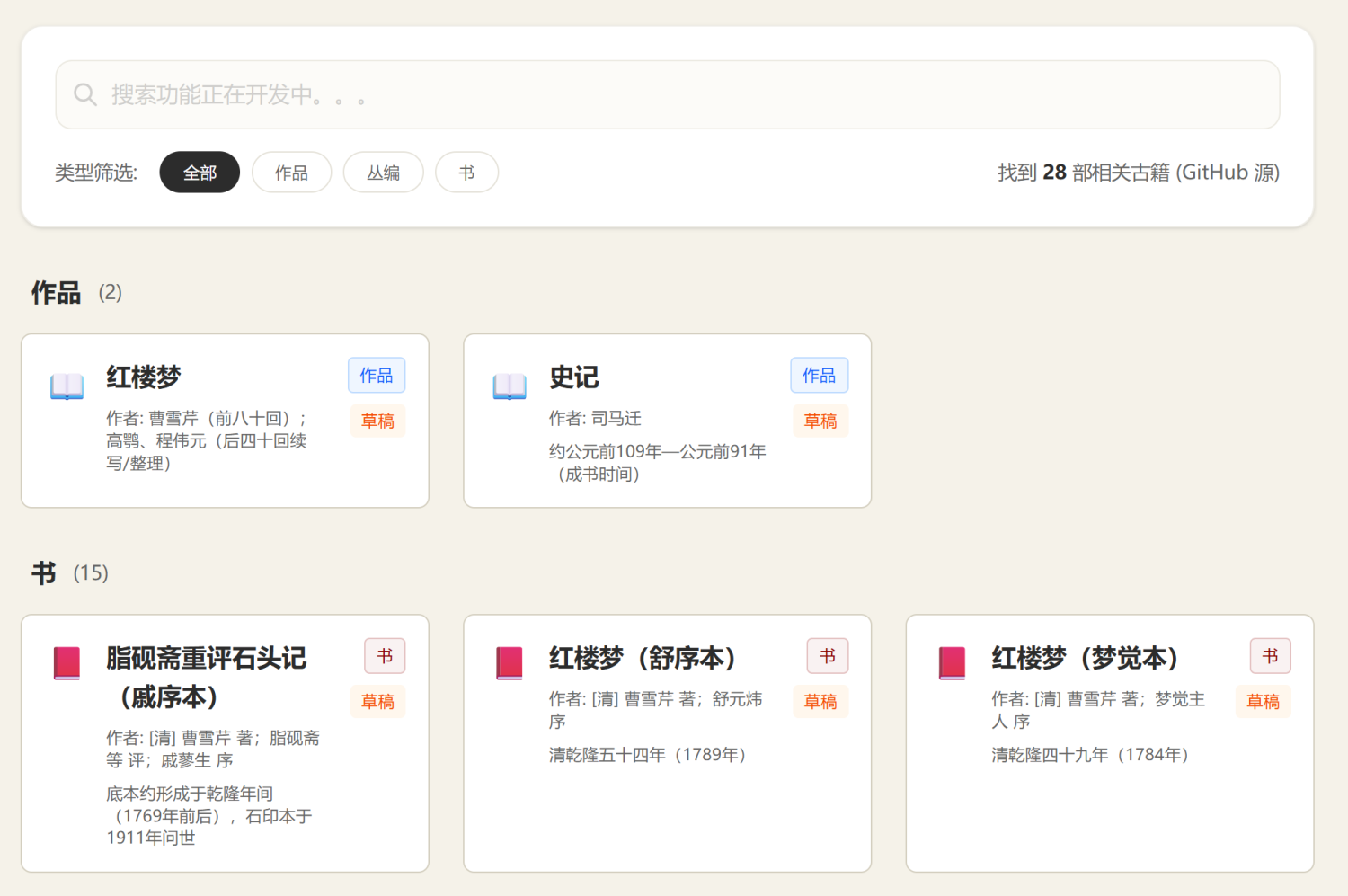
我很快做了一个网站验证我的想法,只添加了红楼梦和史记的部分版本:
1. 网站首页,可以搜索作品、书(具体某一个版本)

2. 对于某一本书,记录它的基本信息、简短介绍
3. 在网络上收集文字、图片资源。
4. 介绍收藏历史、链接到其他版本
欢迎试用,但是目前信息很少:https://www.kaiyuanguji.com/book-index
做出这样的一个网站是容易的,最难的是信息的收集和校对。我计划首先通过爬虫及 AI 的辅助,将几个大型资源网站上的信息都取下来。但是更重要的是后续还需要一个开源社区的不停地像维基百科一样,不停地进行资源补充、核实、信息校对。
想问问大家:这样的网站,
- 有没有用?
- 有没有已经有类似的解决方案?
- 怎样做才能更好用?
- 是否有人愿意和我一起来做后续的内容维护?
欢迎评论和反馈,或者联系我深入探讨:sheldonli.dev [At] gmail.com
注:目前我所了解到的最接近的就是汉籍影像集成系统(https://guji.wenxianxue.cn/)。它集成了国内外大型图书馆。但仍缺少其他功能和其他网络资源。
公子旷游客有点古籍版百科全书的意思,感觉挺好,需要资料的时候,比在网络检索信息要更直观,加油
未曾管理员
赤霄游客想法非常好,也肯定有用,只是找人一起的可能性很小,相信你可以的。
赤霄游客为了减少工作量,建议配台电脑,部署deepseek。
谢耳朵游客肯定要以AI+爬虫为主,人工为辅。目前的这20多本书的基本信息+介绍+收藏历史都是AI生成。但是资源还要手动找,目前AI返回的网址总是错的。
zyz游客想法很好,先搞个目录大纲,然后再依大纲条目补充具体内容
ZZL游客创意很好,古籍版本网
未曾管理员
公子旷游客@未曾 #203755
支持,如果内容上面使用了AI,就我个人来说肯定会放弃这个网站的
谢耳朵游客@未曾 #203755
确实。我仔细看了我截图的红楼梦甲戌本的AI总结,收藏历史至少有两处错误
> 从上海地摊购得
是收藏者后人送来的
> 上海博物馆斥资400万美元
应该是80多万只是AI即使只有八九成的准确率,也比没有好。人工录入的工作量太大了。但仅靠AI又容易传播错误信息。还需要好好权衡一下。
xiaopengyou游客就小說類而言,
LZ的創舉是把《中國通俗小說書目》+《增補中國通俗小說書目》+《中國通俗小說總目提要》給整合電腦化+具象實物化了,
感謝
未曾管理员如果不考虑版权的话。
可以把沈津老师主编的哈佛燕京图书馆藏中文善本书志整合进去,书籍量够大文本质量也不错
谢耳朵游客综合大家的反馈,比较合适的办法可能是:
- 以已出版的类书为第一信源,以维基为第二信源,尽量不采用其它网站的信息。
- 给出的信息一定要标明出处。
- 结构化的信息尽量采用脚本处理的方式提取。其次使用AI 总结。AI总结时强制要求从信源总结而不是用自己的大模型数据。当然这个过程中肯定还有很多错误,需要人工订正。我会尽量少地显示其他信息,把主要精力放在文字、图片资源的搜集上,以及版本和作品之间连接。我也不想重做一个维基百科。
夢夢游客如果收录范围是所有已经数字化的书目的话,那这个工作量相当大了。
黍离游客仅论书目的话,籍合网的书目数据库(收录最多,几百种书目),中华典籍总目(丛书综录),上海图书馆循证平台(善本书目),古籍保护网(珍贵名录,古籍普查),光这些数字化的书目,工作量很大,而且有版权问题。
黍离游客至于找图片资源,工作量也很大。除了全球汉籍系统,较为方便。其他网站、全库,比如上海、南图(无水印)、天一阁、浙江(维基共享)等等,要么在对应官网(检索方法不完全一样,比如内阁文库),要么是在全库,想要一一对应并且核实,工作量也非常大。
崇鹂游客我曾经有过这种设想,但估计成本下来,应该是国家性工程。
如果再往大了说,全国各地有很多孤本根本就没登录到网上,甚至是近年才在民间拍卖、公馆尘封的书库发现的,乃至日本欧美大量市县小镇级别的图书馆,都有中国的稀善古籍,基于这种考量后续的维护可能是无休止。除非一开始就有手眼通天的人,破除所有学阀壁垒,集全国之力主持这项工作。
限于个人能力,一个比较简便的方案是,写程序先把《中国古籍总目》《四库总目》转录进去(网上有Excel等版本),足够支撑一个小型的古籍检索数据库。虽然《总目》最大的问题是不够总,一旦到了我熟悉的门类就会发现他不全,但也比较满足日用了
黍离游客@崇鹂 #203772
目前这两个都有了。四库总目不用说,日本“全国汉籍”,甚至微信读书都可以全文检索。中国古籍总目,在国家典籍智慧化平台,也可以全文检索。
黍离游客@黍离 #203788
打错了,是国家古籍数字化资源总平台
崇鹂游客@黍离 #203789
楼主的主要设想是古籍信息,包括版本对比说明,我关注的部分是基础录入,就是说最基础的古籍书名都成问题,只要一设想到这个地步,就知道对个人来说边界是无尽。
不管怎么说,网站至少能将《总目》《四库》的书名都录入,才有了对比完善的基础(总目似乎是17万种,word文档大概5MB,虽然沧海一粟但主体够用)。这些都有公开免费可抓取的数据,可以快速把框架搭建起来,后续就是漫长的众人建设了。现在网上涉及古籍的信息,基本都是海量重复的垃圾信息,这就是楼主的痛点,但也是最漫长困难的地方,有时候一部书就是一篇博士论文
题外话,如果有人能搞到国家图书馆的古籍总目,能碾压当前国内外一切数据库,请有关朋友能提供有关消息。我现在用国学迷的古籍检索,虽然海量错误信息,但因为书足够多,也已经不是国内外任何书目检索系统可比的了。至于精确的基础信息,恐怕是网络世界最宝贵的东西。有时也不禁想,恐怕图书馆自己都搞不清有什么书,“摸清家底”的号召出来那么多年,太多贫穷的地方根本无力统计清楚,目前只是限于各地自发统计、有限报告、新建文件夹的程度而已,国外限于政策项目,别人也遮遮掩掩,互联网之狭窄信息之有限常常让我深感无力
黍离游客@崇鹂 #203795
光书名问题,就很难了。先不说有没有著录条例,是否规范著录。古籍普查之前,各图书馆出版的书目不多,且大多是善本书目,普通古籍书目很少。大量普通古籍没有清点、统计、著录。哪怕是国家图书馆,普通古籍总目,也只出了五卷(原计划十五卷),上海图书馆的普通古籍,长期以来,仅抄就一套卡片让读者检索。古籍普查后,情况有改变,但仍有很多书目没有上网。
这么浩大的工程,也只能国家来牵头。之前的中国古籍善本书目,是周总理的指示,尚且差点烂尾。如今技术条件虽然好了,但重视程度,不如善本书目那时。至于个人,只能先搭起框架,先用着再说。
谢耳朵游客根据大家的反馈,我的计划调整为
- 先试着录入汉书艺文志、四库全书目录、以及一些近代的目录,有一个基本的框架。
- 试着扫描维基文库,以及一些大的图书馆,链接文字、图片资源。
根据效果再决定下一步的计划。有所进展之后我会在技术交流区分享。
世真游客做目录说简单也简单,说难也难,感觉全國古籍普查登記基本數據庫的目录可以先做进去,毕竟是现成的,如果有需要我也可以提供一些,但是目前来看,你这个网站响应不是很好(至少在我这打开极慢)
h游客各位,请问 全球汉籍影像开放集成系统 是不是打不开了?
谢耳朵游客@世真 #204547
我现在正在整理四库全书目录,汉书艺文志等,先搭一个框架。然后准备通过这些书目搜索维基文库、internet archive、国内外图书馆等资源做链接。
目前还没有备案,所以服务器在海外,访问会不太稳定。有些眉目后我会申请备案,部署一些国内的节点。
菩提游客
谢耳朵游客@菩提 #205182
这个网站确实做的已经很好了,但是只收录了图书馆的资源。缺少维基文库、维基共享、Internet Archive等境外网站。也不包括识典古籍、书格这些网站的内容。毕竟是官方学术机构做的,大概不好收录这些。
另外搜索一本书经常弹出几十个结果,多数是价值不大的版本,难以挑选。
我也希望问问大家有没有这个网站满足不了的需求。
庚明雨游客索引网站,看到过类似的创意:guji.cckb.cn/category-browse
史上首个AI编订古籍版本目录,基于全球汉籍版本循证AI智能体自动生成,任务持续运行中,目前进度:8.2%
- 作者帖子
正在查看 29 个帖子:1-29 (共 29 个帖子)



正在查看 29 个帖子:1-29 (共 29 个帖子)
正在查看 29 个帖子:1-29 (共 29 个帖子)
