正在查看 15 个帖子:1-15 (共 15 个帖子)
- 作者帖子

pizinet游客例如:commons.wikimedia.org/wiki/...0%E9%83%A8
我都是需要单独打开页面,然后获取每一个pdf的地址,不知是否能够有批量获取下载地址的方法。
哪位兄台知道的还望赐教,感谢!
吃饺子不沾醋游客这个网站批量下载时间长了会被封ip的
pizinet游客
zhaogq1989游客楼主,请问您找到方法了吗?
青林游客@pizinet #51643
这个站我刚刚下了一本书,你搜索所需的书点开后往下拉,点开书籍复制地址用bookget可以下了
游客游客维基文库这个网站咋打不开,请问是不是要梯子才能打开???
炁游客有的版本谷歌瀏覽器無需任何技術可順利打開維基文庫在線頁面
也可用kiwix同步數據庫離線閱讀

………………………………
炁游客
青林游客点开可以直接用IDM下载,也可以用下载器下载
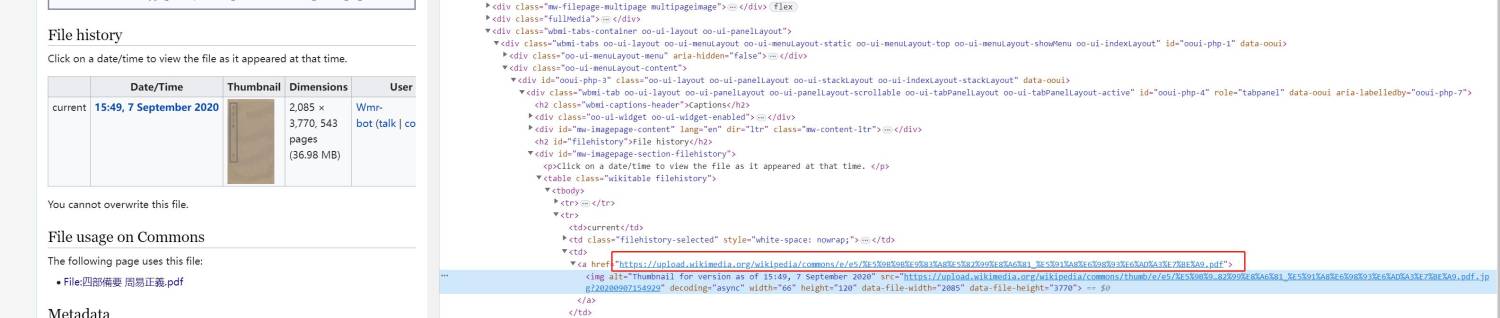
张飞白游客通过观察,可以发现每一本书的可下载的pdf的链接长这样子
由于链接中间有不同的字符及文件名也不一样,所以不能用规律生成
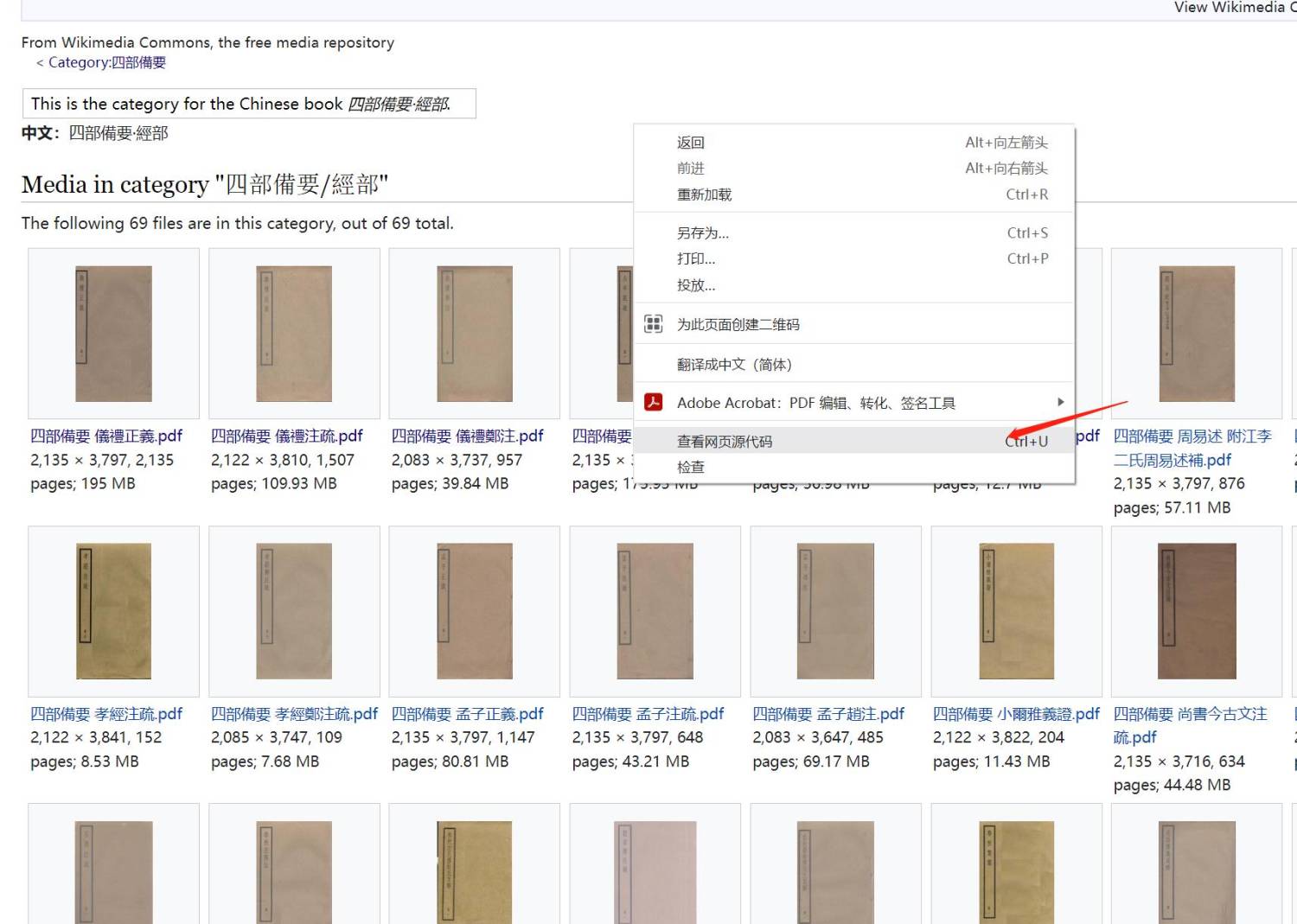
我们想办法看看网页源代码中有没有线索
可以发现还是有线索的,虽然不太一样,但后续可以处理的。将这些全部代码复制,放到emeditor软件中
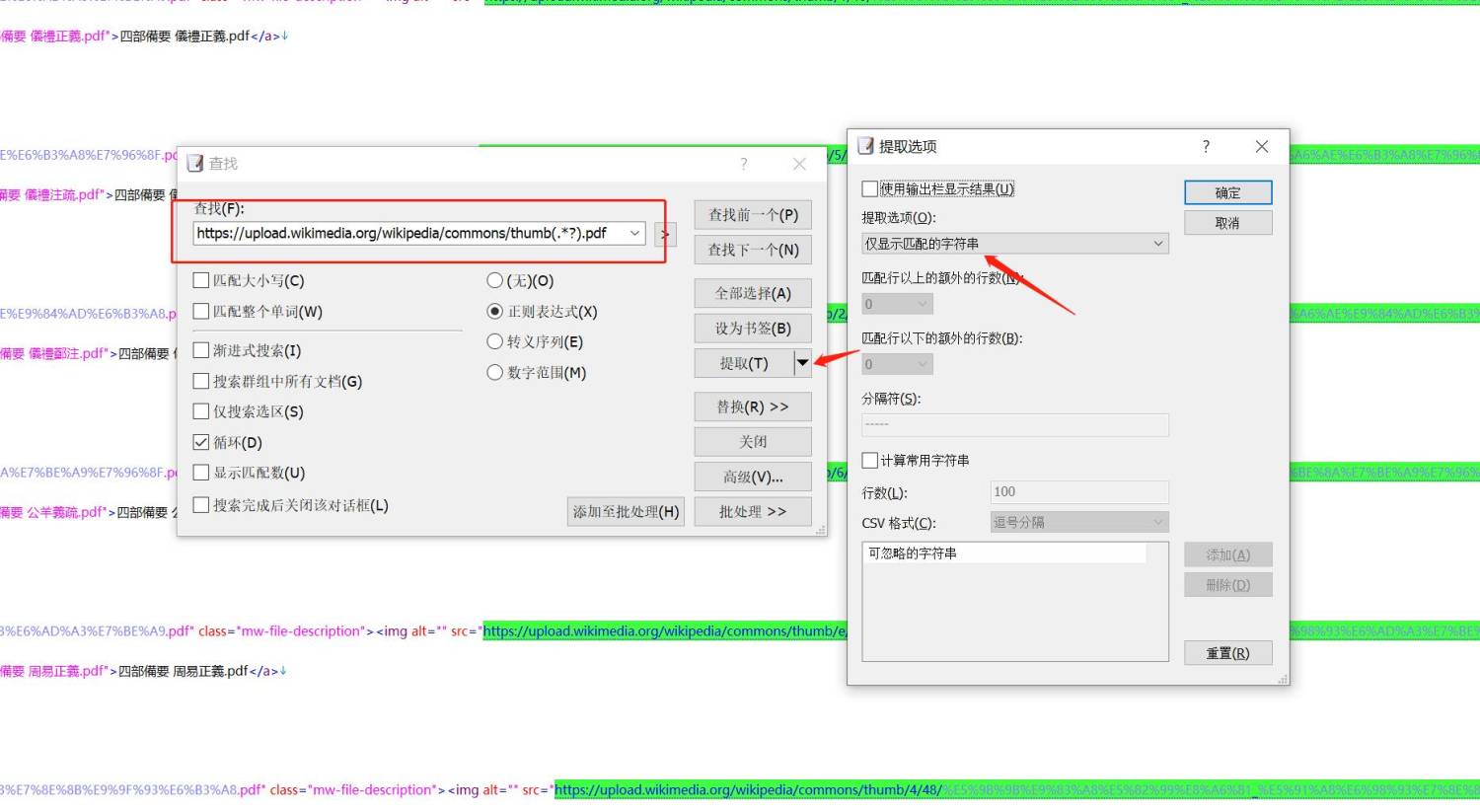
本人的正则表达式不太灵光,不过好歹能用
使用这个正则表达式匹配,然后点提取。(注意提取选项中要选择“仅显示匹配的字符串”)
张飞白游客设置好后,点提取,提取的内容在新窗口如下
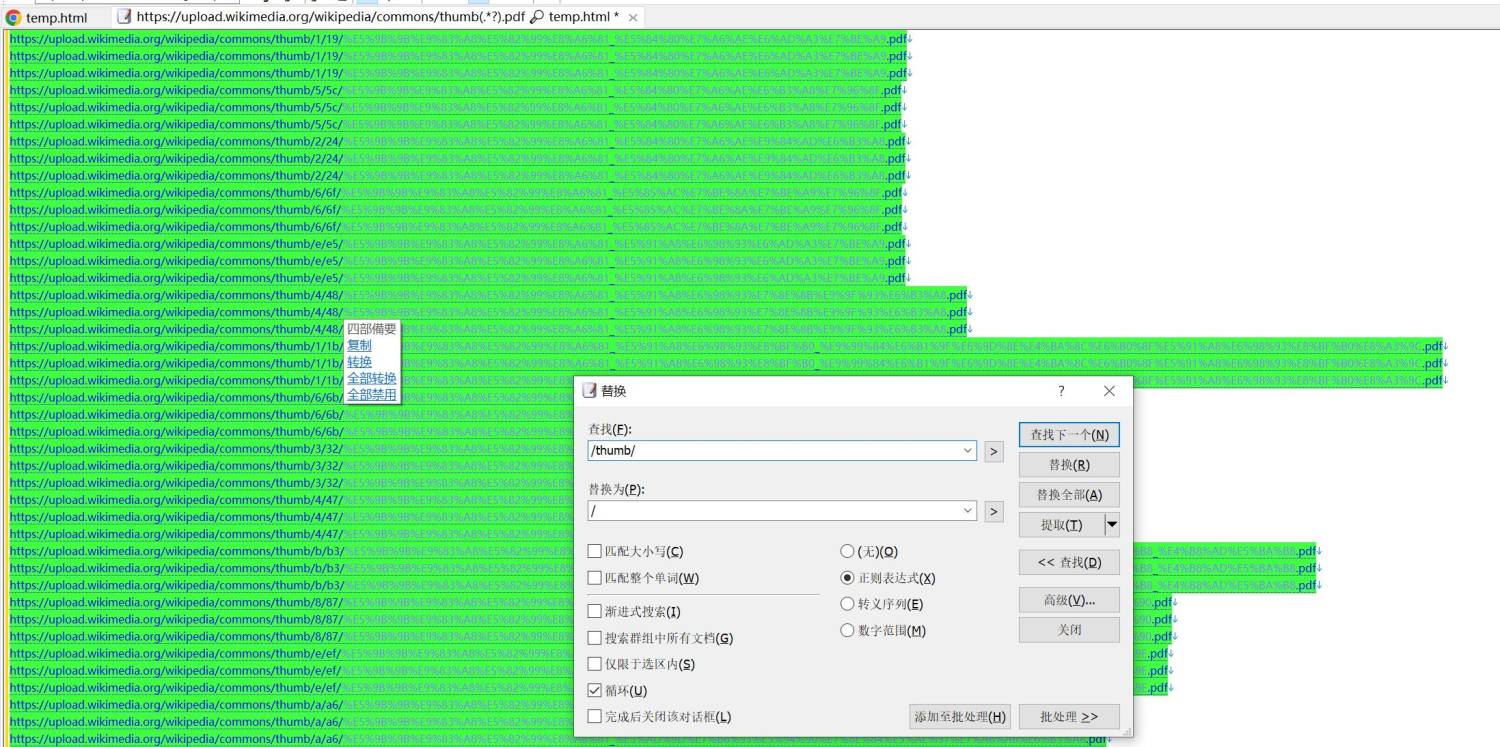
再按ctrl+h,弹出替换窗口,准备替换
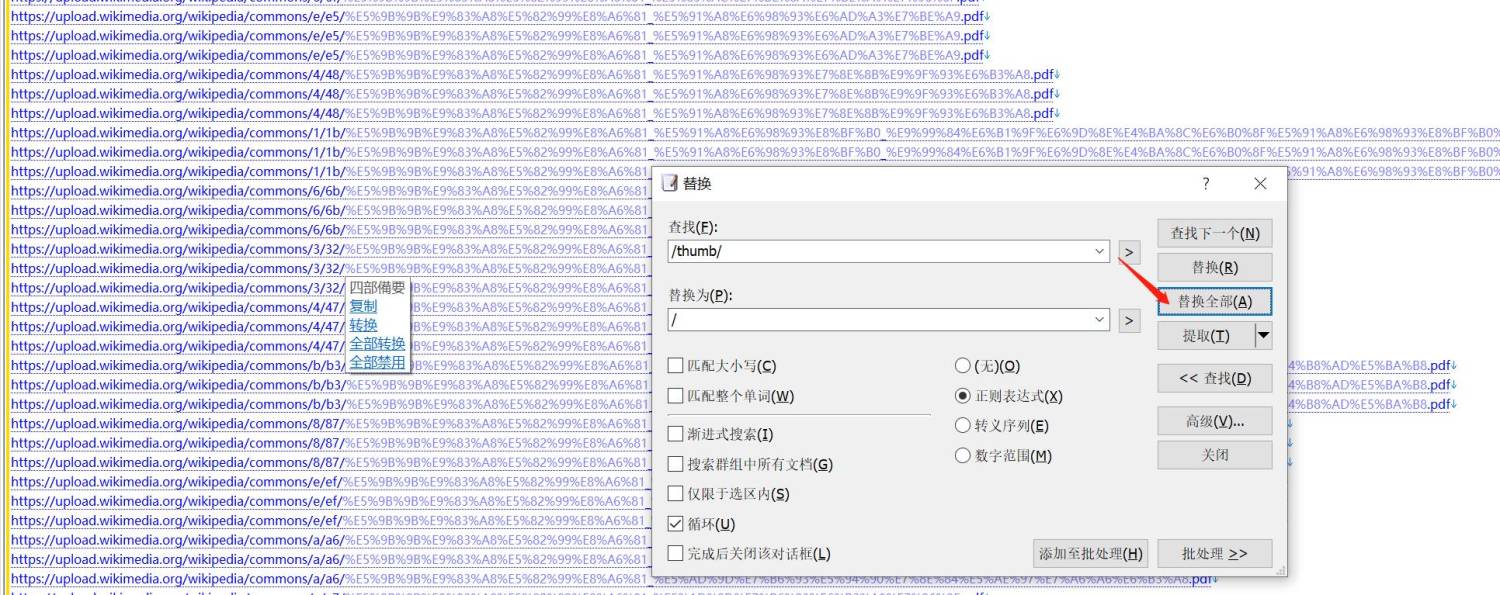
通过观察上面,发现现在提供的内容,比目标链接多了“/thumb/”,按下图中设置,然后点“全部替换”把它替换掉即可
替换后如下
张飞白游客最后,拿出任意一个链接来,测试下,是可以返回pdf的。说明操作正确,没有问题
最最后,把这些链接拿到其他软件上,就可以批量下载了。
炁游客頁面有介紹批量下載方法
切莫不限制線程、不限制速度,將服務器下載崩了
>>>>>
简明游客感谢
- 作者帖子



正在查看 15 个帖子:1-15 (共 15 个帖子)
正在查看 15 个帖子:1-15 (共 15 个帖子)
