正在查看 3 个帖子:1-3 (共 3 个帖子)
- 作者帖子

崇鹂游客因为想翻译一本和古书,发现的一个项目。
据网络报道,日本在1900年左右废除了“古草体”教学,现代日本人阅读古文时面临较大困难,所以制作了这个“古草体OCR”项目。
一、项目论文:
二、项目数据:
由于不懂日文也不懂技术,没搞清楚是不是
1、www.kaggle.com/c/kuz...urces=true
三、项目网站:
主页:
这个网站是跟国文研究所合作的,由于不懂日文,具体可自行试验。
例如:
1、古草体字符板块:
涉及电脑字体编码、大模型学习的数据库。输入单字会出现日本文字正、异各体的古籍实例,数量颇为可观

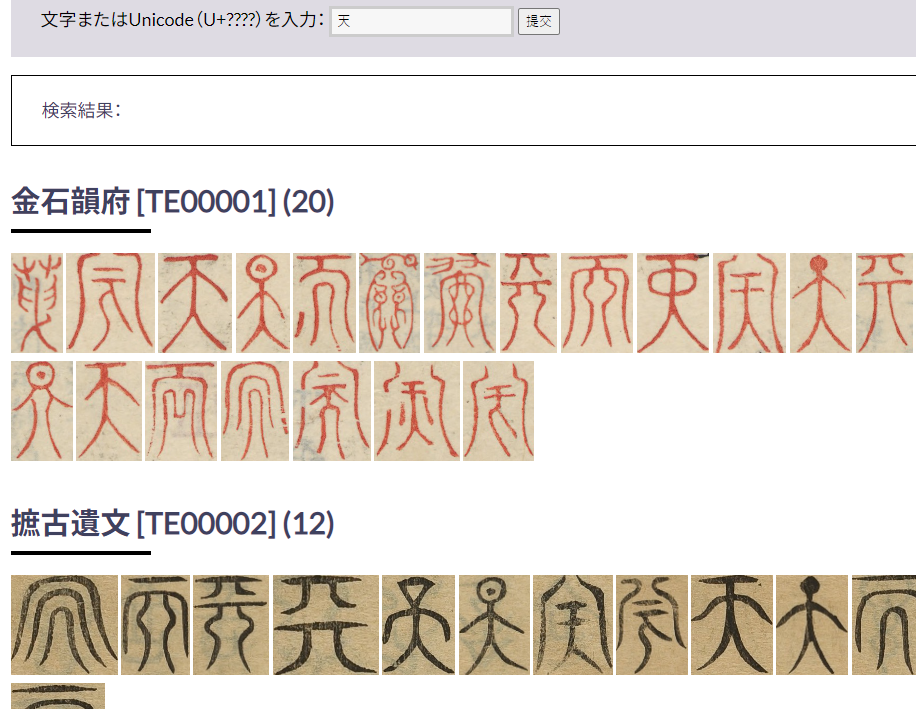
2、篆书实例版块:
可以输入单字,会从中日字典中提取出关文字的篆体,但收书不算多
3、日本古籍人物图像板块
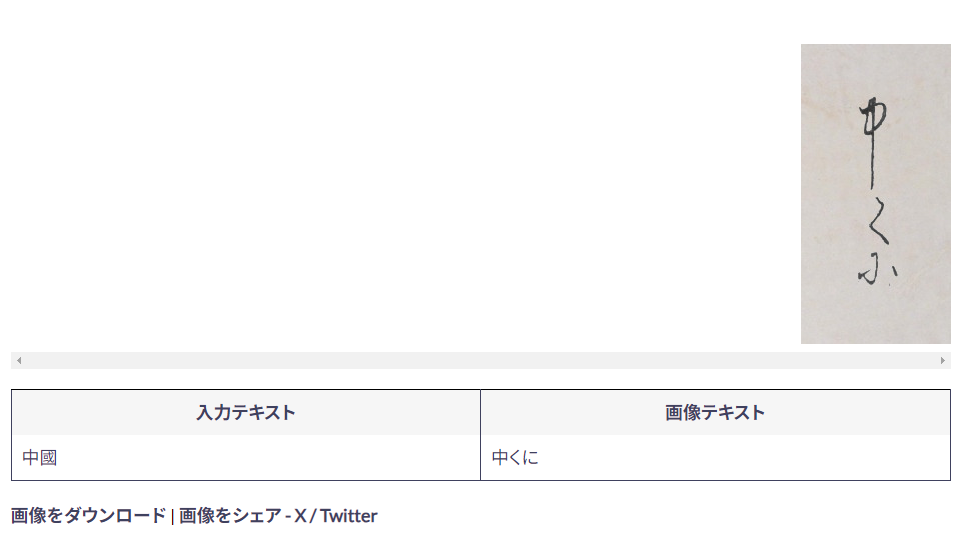
4、古今日文转换版块:
可以输入某些名词语句,会自动生成可复制的文本,并提供古草体图片分享,比较有趣味
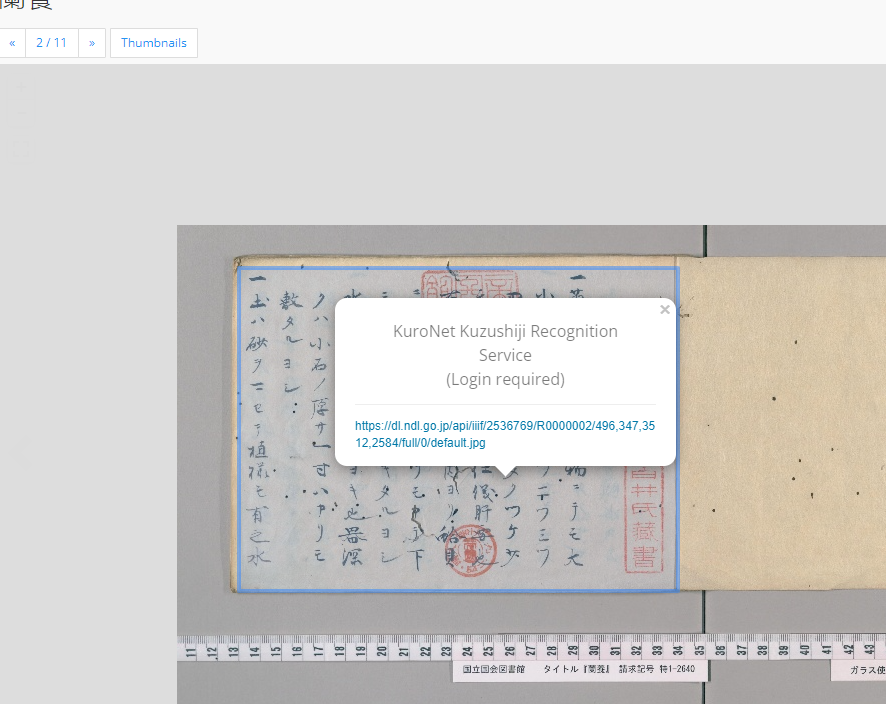
5、日本古籍自动OCR
codh.rois.ac.jp/kuzushiji-ocr/
提供手机软件服务,和在线翻译(粘贴IIIF链接),但因为要登录谷歌推特等账号才能用,我暂时没有进行下一步,后面还要试验一下收不收费、翻译能力
麻黄游客感觉不错,希望有能力者能验证一下!
崇鹂游客刚刚用了一下,正确率,感觉是70%左右。
例如“二”这个结构,可以表示日语假名,可以表示汉字,可以表示重字符号,且日本人的写字很放荡丑恶,机器已经懵了。
日文的先天缺陷,加上喂养的数据量太少,远不如中文OCR。好处是免去了逐一码日本假名的痛苦,能够直接粘贴到翻译软件、在错漏百出中知其大意。
- 作者帖子


正在查看 3 个帖子:1-3 (共 3 个帖子)
正在查看 3 个帖子:1-3 (共 3 个帖子)

