- 作者帖子

atest游客最近用它下载哈佛的古籍,遇到一个问题就是偶尔某张图片大小偏小(比类似的图片小,比如正常是1~2M,这张只有3、400k),仔细看的话在100%下是有问题的,丢失了不少细节,重新下载就正常了。但是如果只是缩放到全屏的话基本看不出问题。
cmd里也不太可能仔细翻看下载时显示的信息,不确定当时是否产生warning或者error。因为下载后过了一段时间才去整理,当时的屏幕内容早就刷新了。
大家有没有遇到过这个问题?有没有什么好办法
atest游客刚才怀疑某本有问题,重新下了一遍,一比对647个文件有163个有缺损,有些甚至只缺了几十k,肉眼根本看不出区别来。难道必须重新下载一遍double check么
zhudw游客你可以試試拼圖模式,修改 config.ini中 dzi=1 保存。再重新下載即可。(PS,這個設置如果沒問題,就不用改回來了,對IIIF網站全部生效。)
atest游客
xiaopengyou游客
atest游客dzi=1开启拼图模式之后就是要下最高分辨率的了,速度很慢,我只有少量书籍才会开启这个模式,一般的2400分辨率也就够了
atest游客@xiaopengyou #137452
啊,那是服务器的缘故吗?看来还是多下载一遍double check吧
xiaopengyou游客
atest游客@xiaopengyou #137456
这个应该是和服务器保存jpg格式有关,我猜测哈佛选择的是progressive jpeg方式,文件损失了后面的信息只会丢失部分细节内容。
和Baseline一遍扫描不同,Progressive JPEG文件包含多次扫描,这些扫描顺寻的存储在JPEG文件中。 打开文件过程中,会先显示整个图片的模糊轮廓,随着扫描次数的增加,图片变得越来越清晰。 这种格式的主要优点是在网络较慢的情况下,可以看到图片的轮廓知道正在加载的图片大概是什么。
atest游客没想到beyond compare还能对比图像,以前只用来校对小说
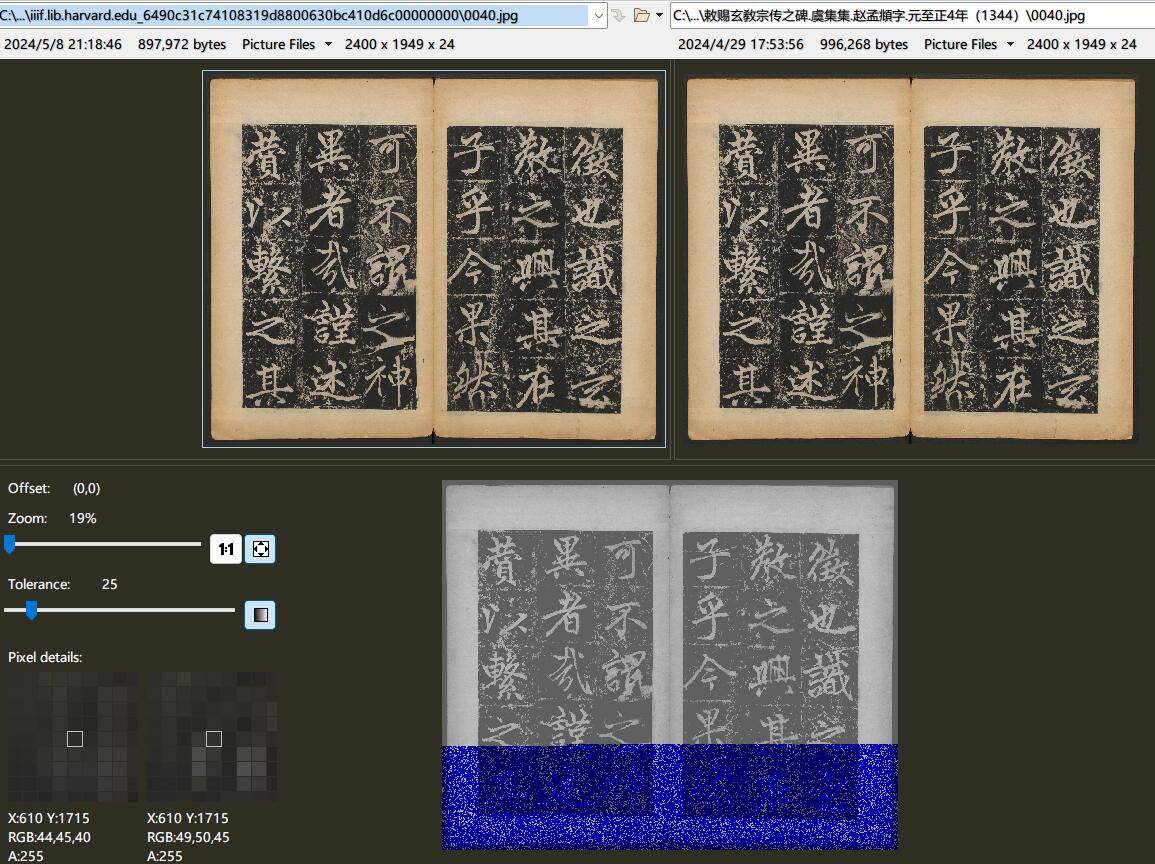
贴一张截图能够直观感受一下,两张图片大小分别是897972和996268,就只有下方四分之一左右的区域略有区别了

atest游客重新下了一批进行double check,发现一个有意思的现象:
凡是不完整的文件,它的修改时间和上一张图片基本间隔了30s,而正常的文件和上一张图片一般都没有到30s,所以我猜测是超时原因导致文件下载不完整。
看了下bookget的源码,果然在request.go里有一处写着:
//default timeout 30s
if r.opts.Timeout == 0 {
r.opts.Timeout = 30
}等以后有能力时争取修改一下代码,至少下载一个目录结束之后需要提示一下哪些文件下载遭遇超时,可能不完整。更进一步是针对这种超时的任务retry1~2次。
没学过go,所以嘛这是个长期任务……
- 作者帖子
正在查看 11 个帖子:1-11 (共 11 个帖子)
正在查看 11 个帖子:1-11 (共 11 个帖子)
正在查看 11 个帖子:1-11 (共 11 个帖子)
