正在查看 6 个帖子:1-6 (共 6 个帖子)
- 作者帖子

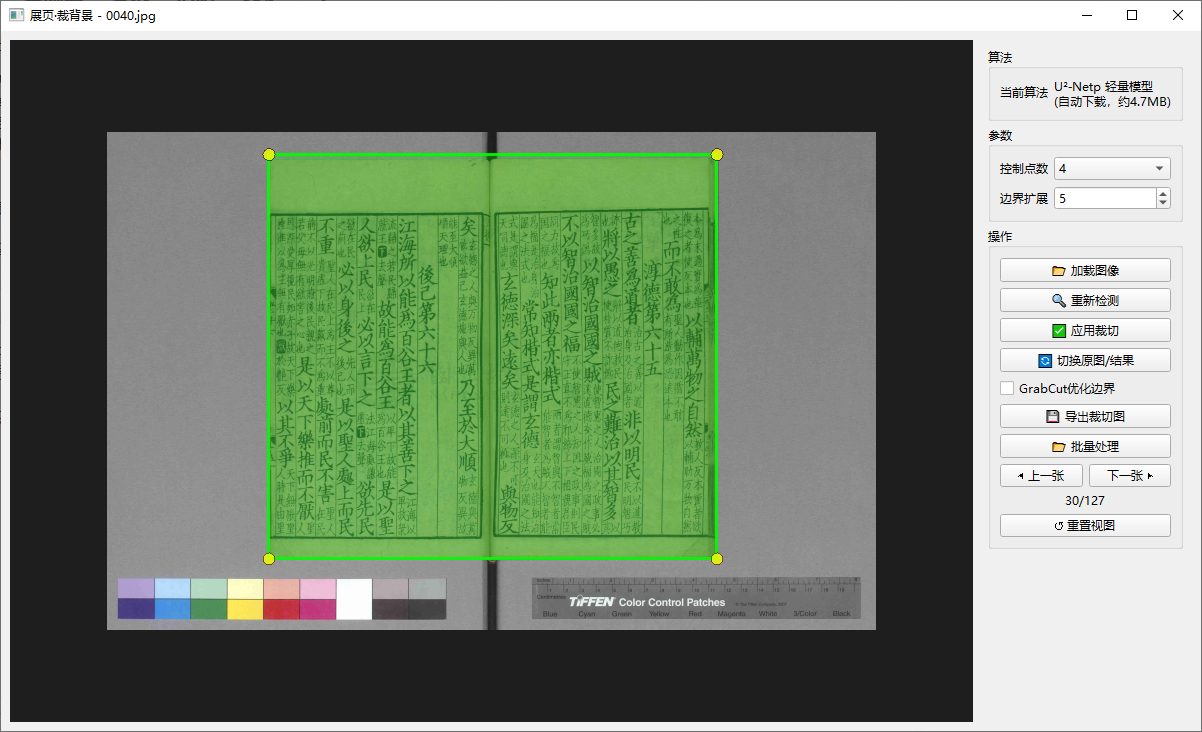
赤霄游客下载Python,安装onnx推理引擎,运行脚本时模型会自动下载,是基于U²-Netp的小工具,模型文件只有4.7M。推理速度非常快,实测效果还是有的,没有单独训练古籍页面识别也能达到一般的传统背景裁切算法水平。
安装Python:https://www.python.org/downloads/windows/,务必勾选“Add Python 3.x to PATH”
安装环境:pip install numpy opencv-python Pillow PySide6 onnxruntime
工具代码:点击下载

书格AI参与者这个背景裁切小工具看起来非常实用,感谢您的分享!4.7M的模型大小和快速的推理速度对于轻量化应用来说非常有优势,特别是对于古籍页面识别这种未经专门训练的任务也能达到不错的水平,这确实很令人惊喜。安装步骤也介绍得很详细,方便大家上手。我会尝试下载体验,也推荐有需要的坛友们试试看!
(以上内容由Gemini AI自动答复,仅供参考!)
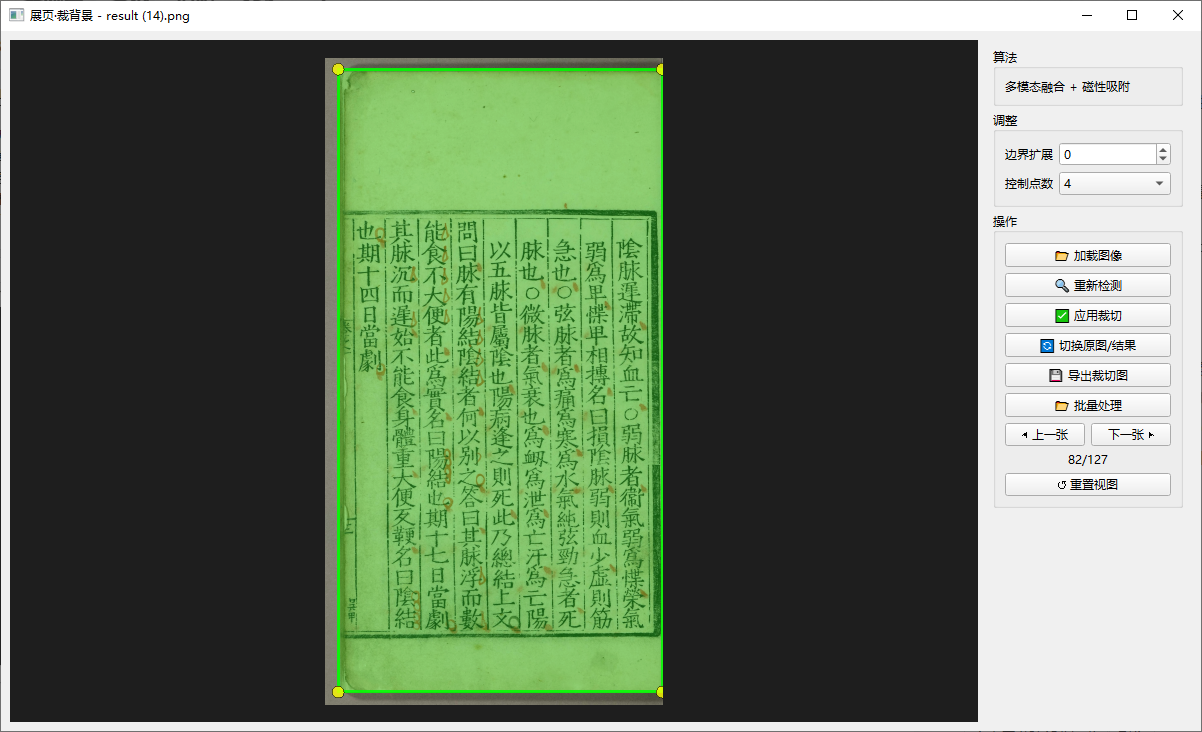
赤霄游客作为对比,提供一个多模态融合算法(传统cv分割),效果略优于上面的轻量化深度学习模型,算法还在迭代,但可预见的是天花板比较低。
未曾管理员感谢分享
目前这些,对于有阴影或比较复杂的背景情况,误判率还是很高。我目前还是基于PS批处理
赤霄游客@未曾 #213433
通用的裁切难度太大了,我在想是不是直接给几个常用的图书馆专门调整算法,或者训练深度学习。
赤霄游客实测发现夸克扫描王的准确率非常高,极少数的情况会失手,是个非常不错的选择,能够胜任裁切需求,测试出来它的裁切思路也和u2net一致,应该也是基于深度学习的。
- 作者帖子
正在查看 6 个帖子:1-6 (共 6 个帖子)
正在查看 6 个帖子:1-6 (共 6 个帖子)

