标签: 优质分享
- 作者帖子

学惭淹贯游客@zhudw #170192
原来终极问题终于找到了,是后缀大小写的问题,不是网站对图片网址做了处理。感谢大侠。
佐助小樱游客请教一下大神 现在下载韩国国立图书馆老是失败
显示的代码是
2025/03/22 17:11:18 Disconnected from server
2025/03/22 17:11:18 Disconnected from server
2025/03/22 17:11:25 Expected status code 200 but got 404
这是哪里的问题呢
河北 无用游客只能等待 大师zhudw有时间再施展绝技了
zhudw游客@佐助小樱 #170324
你用 2 年前的软件,当然不能下载了。是什么理由,让你坚持用旧版,我想不通啊。软件是纯免费的。如果你看到有新版,请尽快升级。
mlliu游客怎么发帖子回复贴文?
佐助小樱游客@zhudw #170419
我也用最新版的试过 ,链接贴进去回车以后,弹出的浏览器能正常浏览,但是不能下载,又提示让输入网址。之前旧版的还能用,最近也不行了。
zhudw游客@佐助小樱 #170630
看看这儿,需反复操作 www.shuge.org/meet/...ost-169883
mbss游客国图49年以后得资料怎么下载呢?复制到bookget后生成了一个0 kb的pdf文件,等了许久都没有反应
zhudw游客@mbss #170669
49年以后应该不算是“古籍”。你先确认是否能在线阅读, 大概就是仅馆内阅读的书,不能看也不能下载。
lsp游客zhudw老师您好!江苏高校珍贵古籍前几天还能下载,这几天只能下载几页,然后就不能了,网址也打不开了;变成403,重新拔了电源插头,再打开电脑,又能下载几页,又不能了,请问这是什么原因?谢谢!
zhudw游客@lsp #170681
如果要挂机下一本书,大概要用“比较慢”的下载方式。江苏古籍和南图的服务器性能极差、速度稍快一点就会出现403。
修改 config.ini 文件中默认参数,或许可以解决。
threads = 1 #必备设置,1或2 speed = 5 #间隔时间,可选值5至12秒
lsp游客好的,老师!我试试看
轩辕十四游客@zhudw #170683
老师您好,麻烦请教下,印象中记得book某一版,是可以下载这种锁住资料的,但现在给忘了,请教一下是哪个版本来着?谢谢!
catalog.hathitrust.org/Recor...iewability
zhudw游客
轩辕十四游客@zhudw #171217
谢谢老师回复,请问是哪个常青藤机构?百度了下好几个常青藤机构。。还是密歇根大学会员账号?还望指点下,谢谢!
未曾管理员@轩辕十四 #171177
换个代理节点试试,我这里看是没有锁的
zhudw游客@轩辕十四 #171242
这个我也不清楚是哪个常青藤。楼上 @未曾 先生发现的有些IP还能直接下载。可能是针对某些地区开放的,我用日本IP看不到的。
轩辕十四游客@zhudw #171262
好的,谢谢老师!
无限游客@zhudw,用最新版,下载京都大学,第一张就卡住了。参数已经设置,
# 自动检测下载URL。可选值[0|1|2],
# 0=默认 ,只下载支持的图书馆
# 1=通用批量下载(类似IDM、迅雷)
# 2=IIIF 标准类型网站自动检测
app_mode = 2[dzi]
# 使用dezoomify-rs下载,仅对支持iiif的网站生效。
# 0 = 禁用,1=启用
dzi = 1
zhudw游客@无限 #171382
dezmooify_rs 提示的 warn 警告,不是致命错误,一般只要网络正常可以继续下载。
若是因为连接数过多,导致的网络异常,请参考:www.shuge.org/meet/...ost-170683
zhudw游客@无限 #171382
抱歉,和上述设置无关,京东大学已经用 IIIF 模式(原内置支持的功能失效),只有单任务多线程(由 dezoomify-rs 控制的)。
你遇到网络卡住,可能需要换个时间段(01:00-12:00 海底光纤会比较不拥堵),或者换日本的代理IP试试。
或者尝试修改以下参数,用2个线程下载:
rs = "-l --compression=20 --timeout=300s --retries=5 --parallelism=2 "
无限游客@zhudw #171534
感谢
xiongyanan游客@未曾 #80239
先生好!日本静嘉堂有《周益公全集》,是抄本,《日藏中国古籍书志 静嘉堂秘籍志》中有记载。恳请先生帮忙找下这本书的电子版。衷心感谢!
学惭淹贯游客@zhudw #170683
设置间隔秒数,对江苏高校古籍似乎没有。不论是间隔1s、5s、10s还是20s,都是下到十三张或十四张图片就不能下,极有意思。然后插拔一下光猫,又可以继续下十三四张,就又不行了。看来是服务器专门进行了设置。
zhudw游客@学惭淹贯 #171688
有没有可能,是他们网站太烂了。前面提到的参数也可以试试。
rs = "-l --compression=20 --timeout=300s --retries=5 --parallelism=2 "
学惭淹贯游客@zhudw #171735
采取
threads = 1
speed = 5
另外加上上面提到的
“rs = "-l --compression=20 --timeout=300s --retries=5 --parallelism=2 "”这条设置之后,结局依旧没有改变。还是下载十四张图片之后,就不能下了,网站也打不开,必须重启光猫,才能重新访问网站。
zhudw游客
学惭淹贯游客@zhudw #172067
所以之前说看来是服务器专门进行了设置。
zhudw游客@学惭淹贯 #172071
别纠结了,能下就下,不能下就换一家网站。
多说几句:国内的政企软件外包一般是多层外包,最后干活的一般都是小公司。预算减少后,硬件配置就会低。为了防止用户量大,都会做一些限制,即使不做限制,访问量稍大一些,也很容易宕机。就南图那个垃圾配置,频繁刷新几次都能弄挂他们网站。
无限游客
无限游客@无限 #172159
下六张就会停下。
zhudw游客@无限 #172159
能通过反复操作,半小时内完成一本书的下载,其实很可以了。
至于,下载过程中突然无法下载,都是服务端或网络问题,这此是不可控因素,没有一劳永逸的解决方法。
通过设置参数,加大间隔时间,减少连接数等操作,你可以在不同时间段(避开高峰期)尝试一下,直至试到满意为止。
如下例配置:
[download] threads = 2 speed = 5 [dzi] dzi = 1 rs = "-l --compression=20 --timeout=300s --retries=2"
zhudw游客
LXT游客zhudw老师晚上好!打扰您了!您开发的wiki,其中有三个网址打不开,分别是“台北故宫博物院善本古籍”,“云南中医药大学古籍数字图书馆”,“高丽大学海外资料中心”,不知道是网址变了,还是网站设置的不让打开了,望您解惑,先谢谢您了!
zhudw游客
LXT游客哦,明白了,谢谢老师!
无限游客东洋 国立国会図書館デジタルコレクション dl.ndl.go.jp/,好像失效了,下来只有空白文件夹
无限游客按 @172225 ,修改参数 可以了
无限游客@无限 #172615
修改参数可以了
mbss游客想问一下出现这种是什么意思呀?
WARN dezoomify_rs::network]network error HTTP status client error (404 Not Found) for url(www.*****.com). Retrying tile download in 3.6s.
zhudw游客@mbss #172717
具体问题,具体分析。或是某网站使用了 dezoomify-rs 不支持的格式(非标准IIIF)。
可以到dezoomify-rs 官方github主页查看它支持的格式(提示:dezoomify-rs --dezoomer 是这个参数)。
LXT游客zhudw老师!您好!苏州博物馆——古籍用bookget下载不了,用您重新设置的京都大学图书馆的参数也下载不了,是不是网站限制了?还是我不会调整参数?请您指教!谢谢您!
囧游客多个链接下载新建了urls.txt,怎么才能不混合下载?想让它每次只下载一个链接,不要多连接同时下载。
chatgpt告诉我这样修改代码
// executeBatchURLs 处理批量URLs模式
func executeBatchURLs() {
urls, err := loadAndFilterURLs(config.Conf.UrlsFile)
if err != nil {
log.Println(err)
return
}// 顺序下载,每次下载完一个再下载下一个
for _, rawURL := range urls {
if err := processURL(context.Background(), 1, rawURL); err != nil {
log.Println(err)
}
}wg.Wait() // 等待所有任务完成
}但是我不懂如何打包成exe执行程序,老师可以指点一下吗?我是小白。或者有什么简单的方法只让每次下载一行的链接,等待此链接下载完毕后再按照顺序下载其他的链接呢?
zhudw游客
LXT游客谢谢老师!京都大学可以下载了
囧游客老师:
218.26.168.243:8300/tyrbp...howbc=true 这个地址原版阅读的图片怎么下载,有方法吗?
无限游客bookget-gui 浏览器,打开后一片空白,而且无法右上角手动关闭,不知为何
无限游客@无限 #173437
换了原包里的gui,可以打开了,但是天一阁网站已经没有登陆入口了
zhudw游客
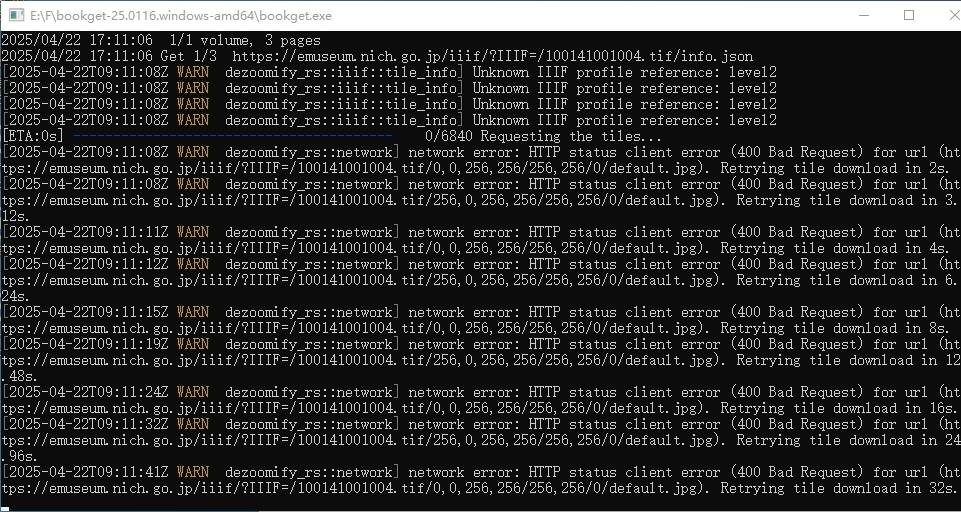
tigershuai游客zhudw老大,在下载e国宝的图时,比如https://emuseum.nich.go.jp/detail?langId=ja&webView=0&content_base_id=100141&content_part_id=0&content_pict_id=0这张图,config.ini中的dzi=0时只能下载到高最大10000像素点图,原大图不能下载到,如果dzi=1时,下载失败,界面如下:
- 作者帖子