- 作者帖子

键史精神病游客
键史精神病游客图例

方午游客看你是自用还是对外开放的,费用除去开发,后续根据流量大小决定服务器的开支。
可加我的微信abit2310
键史精神病游客@方午 #135496
不公開的話,那就如錦衣夜還鄉了。
yang游客我也有这个想法,但是放弃了,服务器1-3万或更好,这个看数据量,没有上限。网站建设费用,从几千到几十上百万,都有,这个看自己需求,上面是一次性投入,然后就是网费投入,专线每个月几千打底带固定IP,大头投入就这些,还有域名,这个便宜,以上能承担就可以, 不行租服务器也可以,只需要投入网站建设费+服务器租赁费,
键史精神病游客@yang #135661
谢谢。看来这费用对我是个天文数字了。
嘉良游客这里有两类费用,一个是网站,一个是写一个古文OCR识别的代码;其实如果用Github这种开源的网站的话,第一笔费用也就省下了,剩下就是OCR的费用了,这个就要看希望达到什么样的效果了,您展示的这个版式和文字内容都是相对清晰和工整的,但还有很多更加复杂的样式。
古籍犹如大白兔游客俺正好是族谱宗谱相关工作者,一个临淄臭老九。他这个GITHUB页面,是个静态的,程序员开发的,这个叫族谱宗谱数字化。
俺说说流程:
第1步:先把族谱抄本OCR识别了
里面有文字校对,是个非常仔细的活,不能有错字。顺序也要对了,要不辈分都乱了。因为这些古籍页面不是单纯的从右到左,它妹的还分层,有点小麻烦。
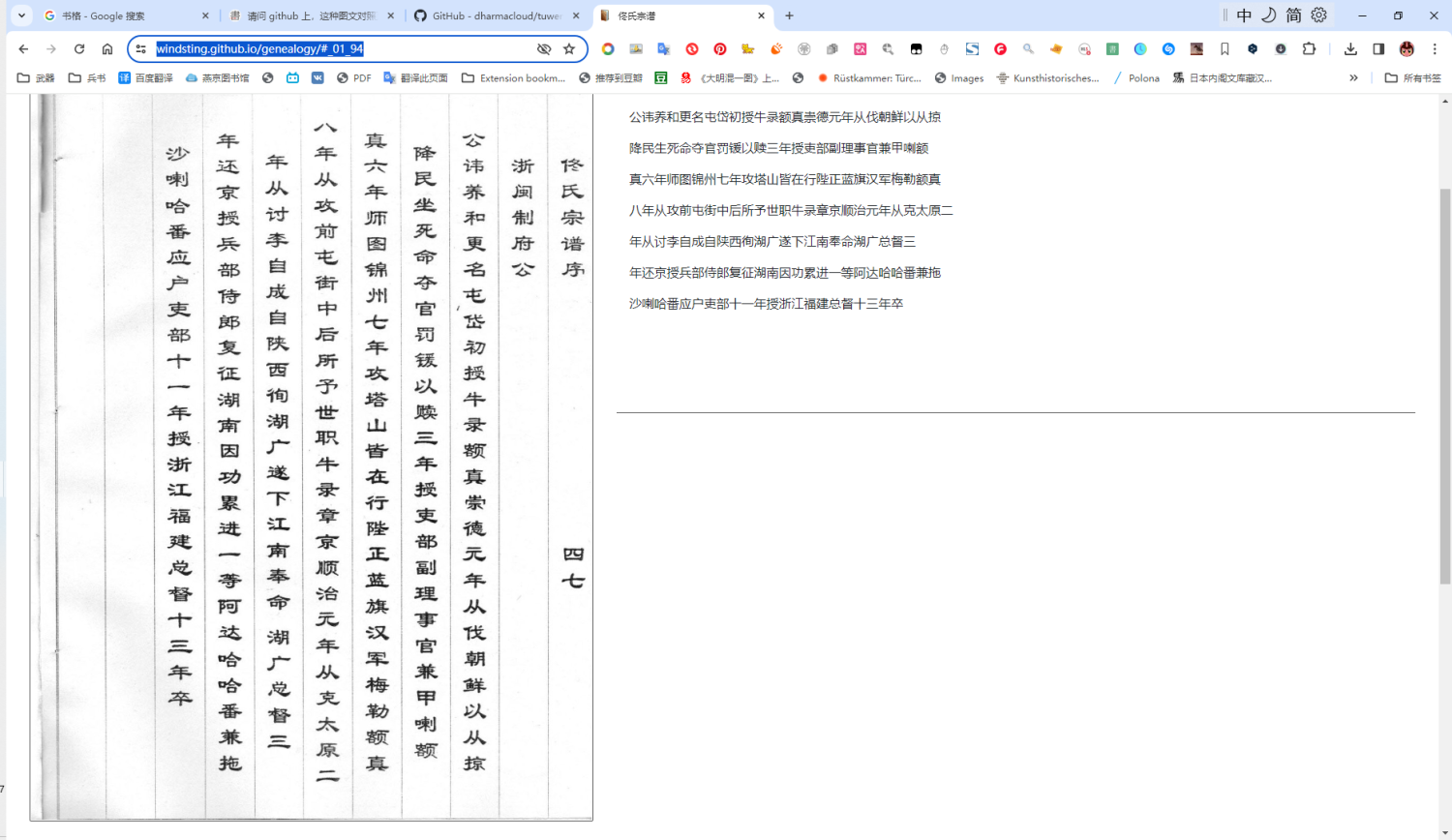
而且都是手写体,很多族谱宗谱都是从老房子里扒拉出来的,通常情况是下面这种水平。
所以 @嘉良 #136137
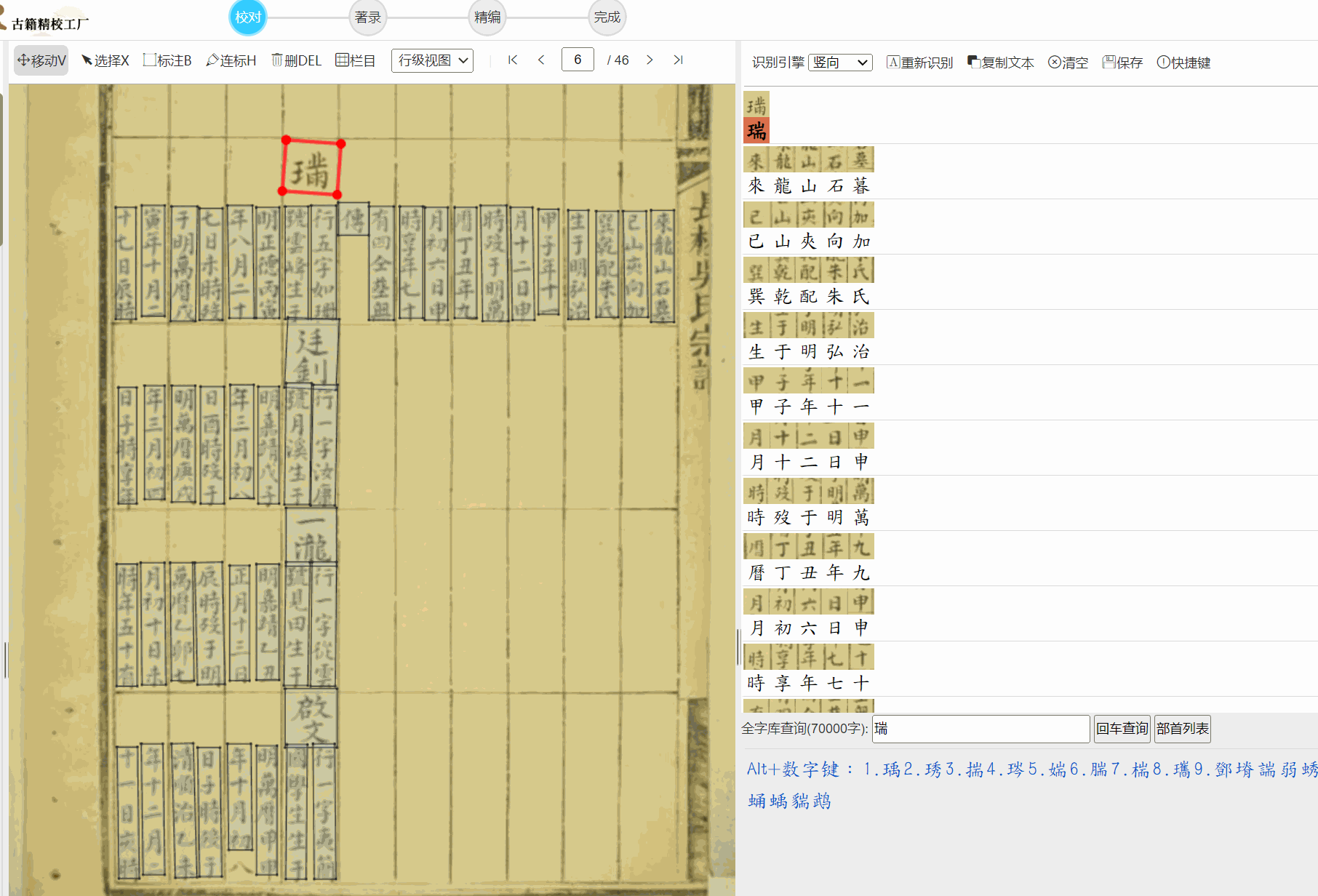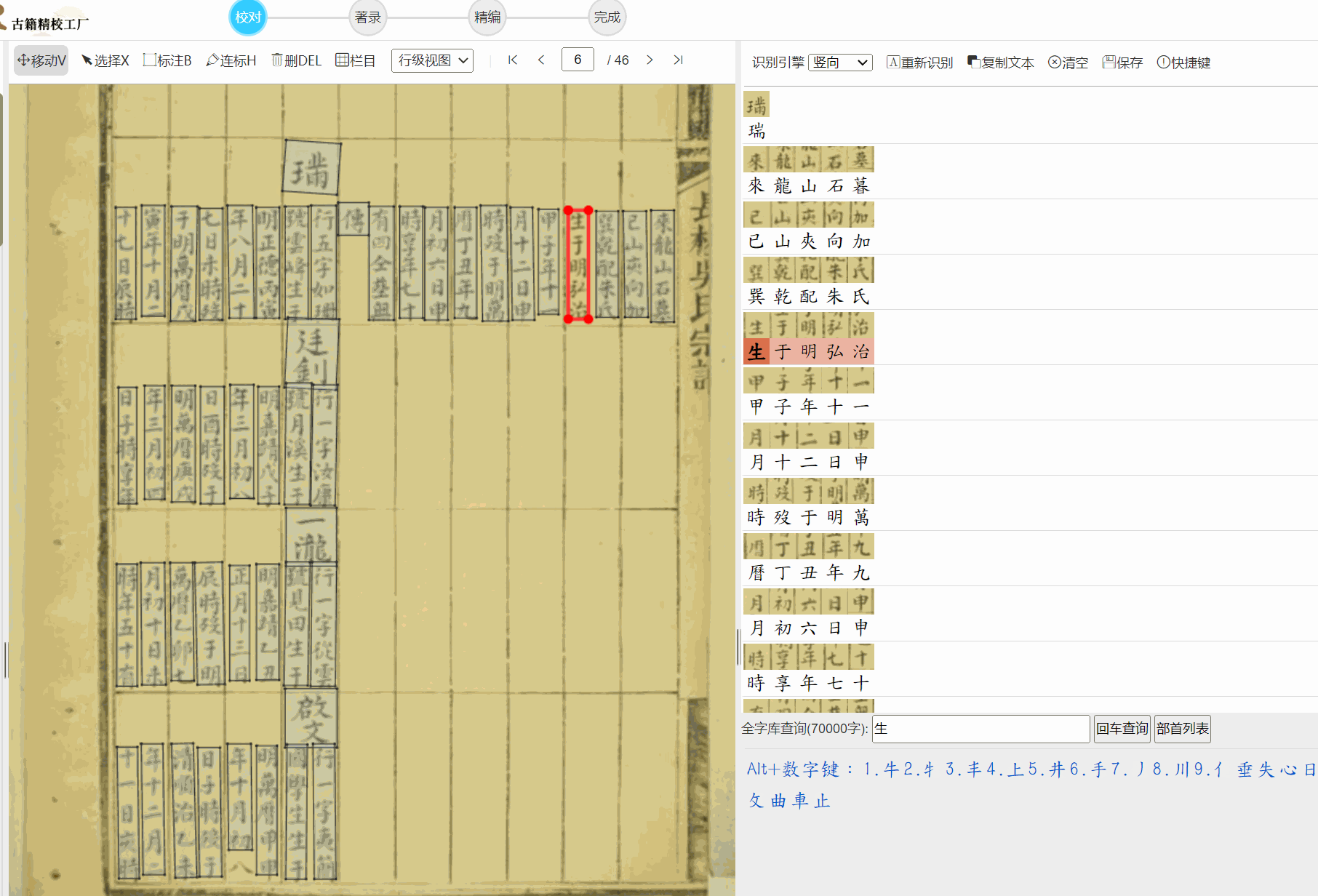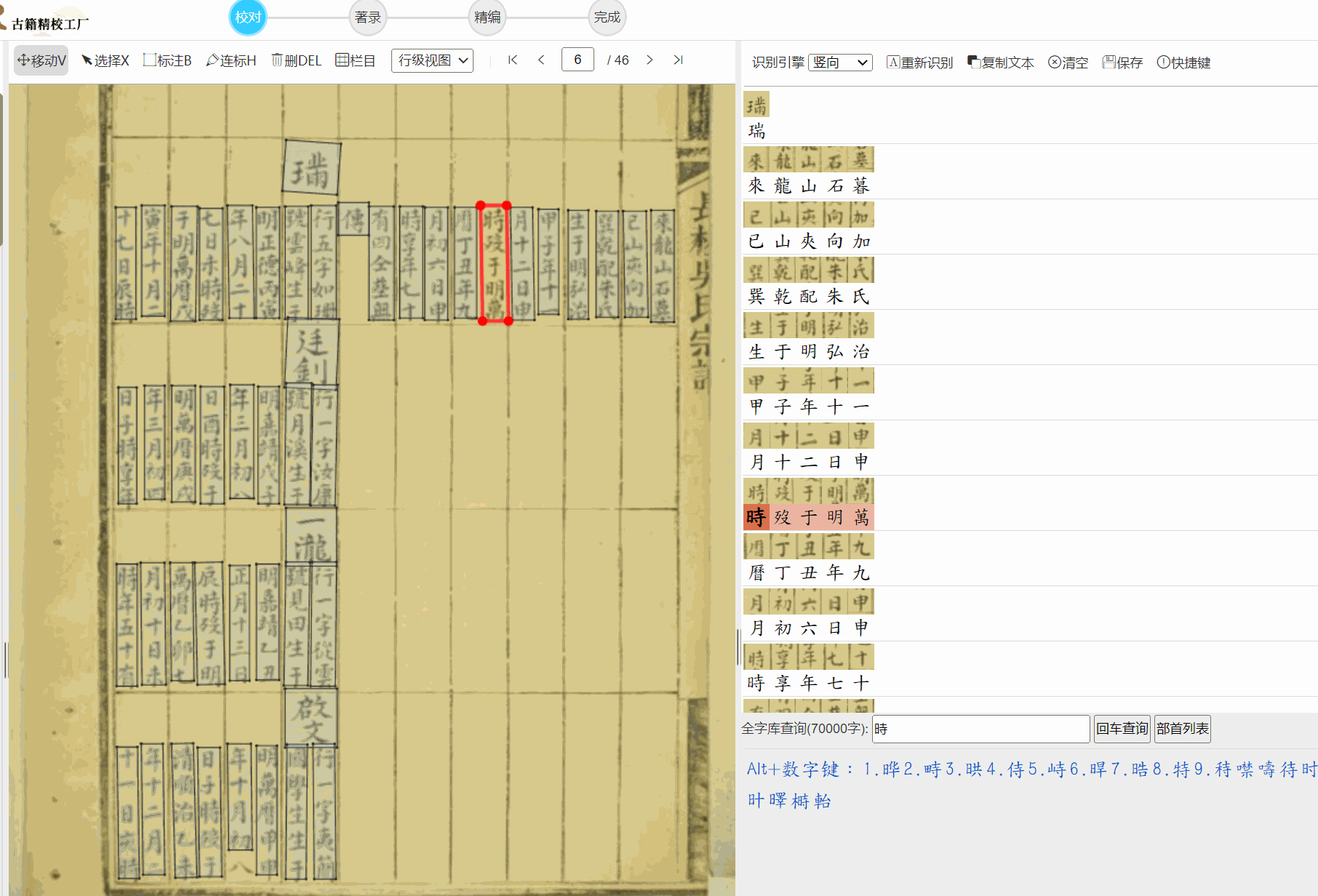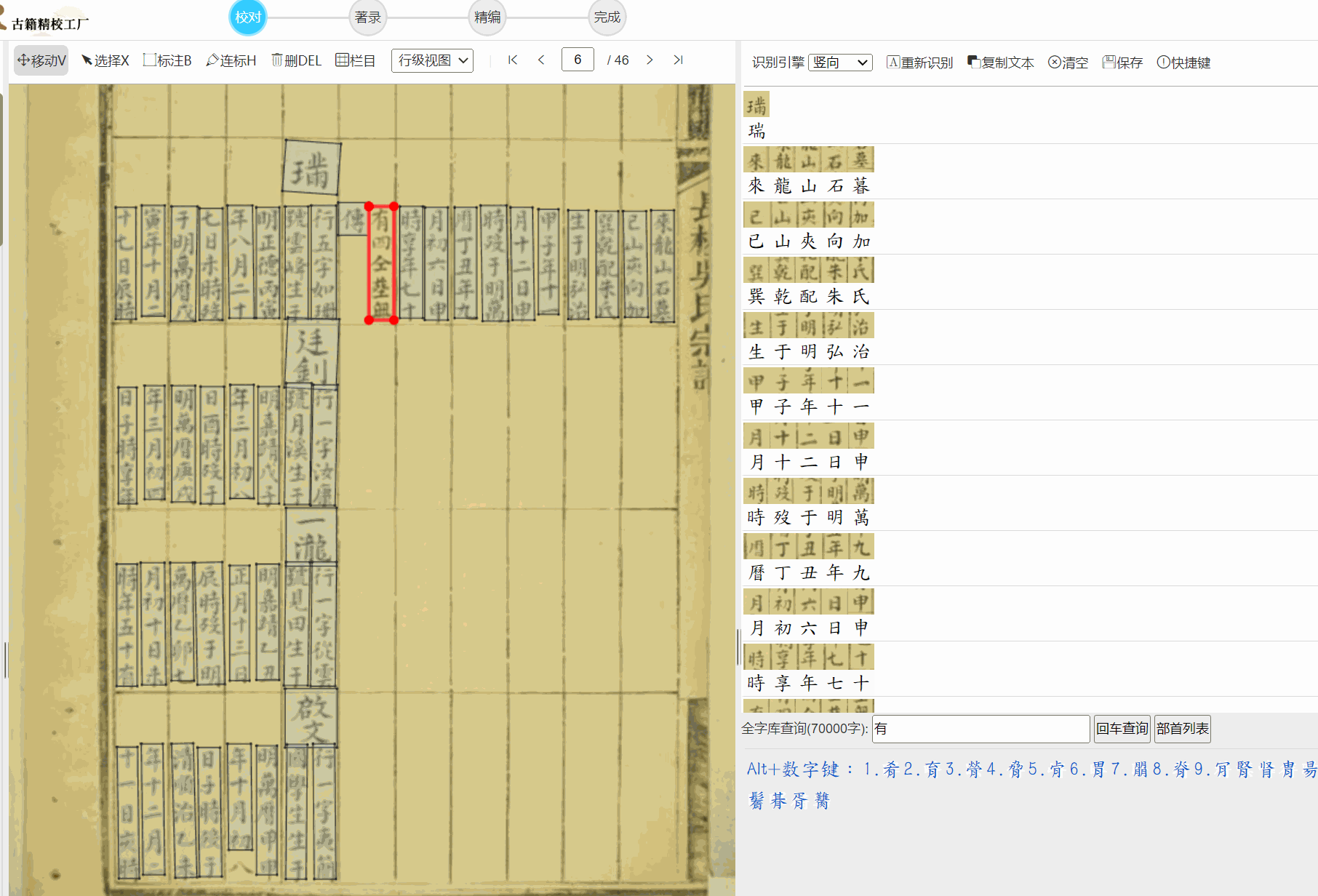
提出的写个OCR识别代码,说的非常实际,印刷本的OCR相对好识别,识别族谱的我找了很多OCR商家都是垃圾中的战斗机。所以搞个OCR服务器是很猛的想法,看典古籍我刚看了下,做的也挺好,应该是个猛人开发。
不过俺习惯了用云聪的古籍平台(凑合着用,很多连笔也要自己撅着腚一个个的校)。
第2步 把识别的结果转成HTML
这是程序猿的活了,咱也不懂,反正人家说把识别结果打印出来也行,这块没有啥子技术含量。
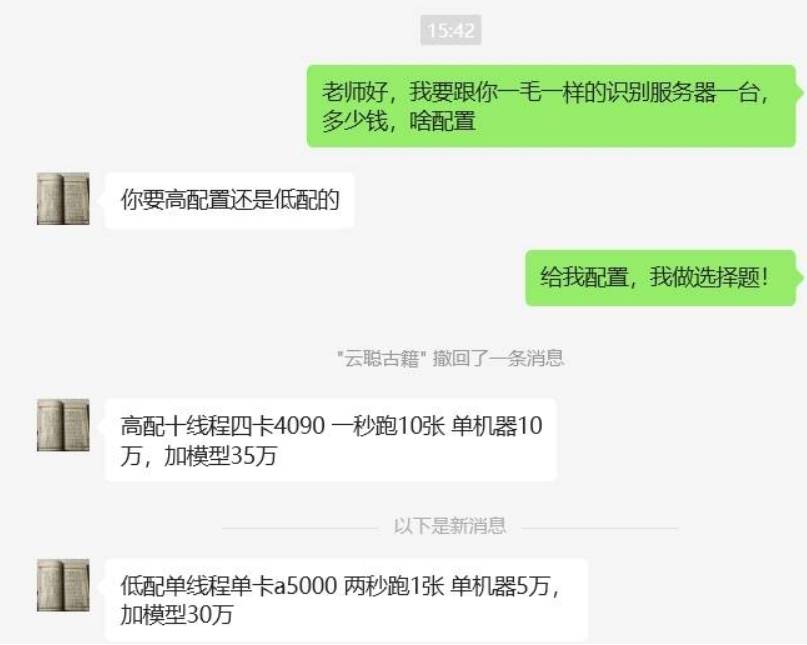
服务器费用,问了一下

服务器是小小头,模型才是人家的核心科技。
如果给我30W,面对这些奸商,我做选择题!???
我立马就搞个196T的大NAS,拿出5T存上书格的所有古籍,剩下的存姐姐们,人生就完美了。
键史精神病游客@古籍犹如大白兔 #136170
谢谢回答,虽然我看不懂别的,看到这个价钱吗,我就知道没戏了。
嘉良游客@古籍犹如大白兔 #136170
完全同意,特别是手写识别,几乎不可能完美。其实我自己就是做OCR的,如果有兴趣可以考虑一下合作。
古籍犹如大白兔游客@嘉良 #136273
你产品叫啥,能否观摩下,发个产品名
蠹鱼游客@古籍犹如大白兔 #136170
精彩呀,可以留个联系方式不,老哥
古籍犹如大白兔游客
蠹鱼游客@古籍犹如大白兔 #136417
老哥误会了,想请教家谱数字化
看典古籍游客OCR也可以看看我们的,效果还不错,有多端支持
- 作者帖子
正在查看 15 个帖子:1-15 (共 15 个帖子)



正在查看 15 个帖子:1-15 (共 15 个帖子)
正在查看 15 个帖子:1-15 (共 15 个帖子)
