正在查看 10 个帖子:1-10 (共 10 个帖子)
- 作者帖子

书游客我感觉我第一步就弄错了,正常的话输入网址你确定它会建一个文件夹,还会显示时间,路径什么的,这个没反应,所有我想请教一下你,我计算机水平不行

未曾管理员@书 #54187
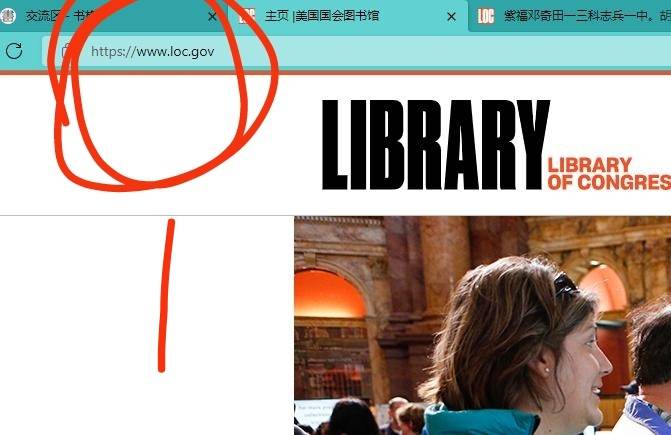
首先可能是网址格式的问题,由此进入
www.loc.gov/colle...are-books/
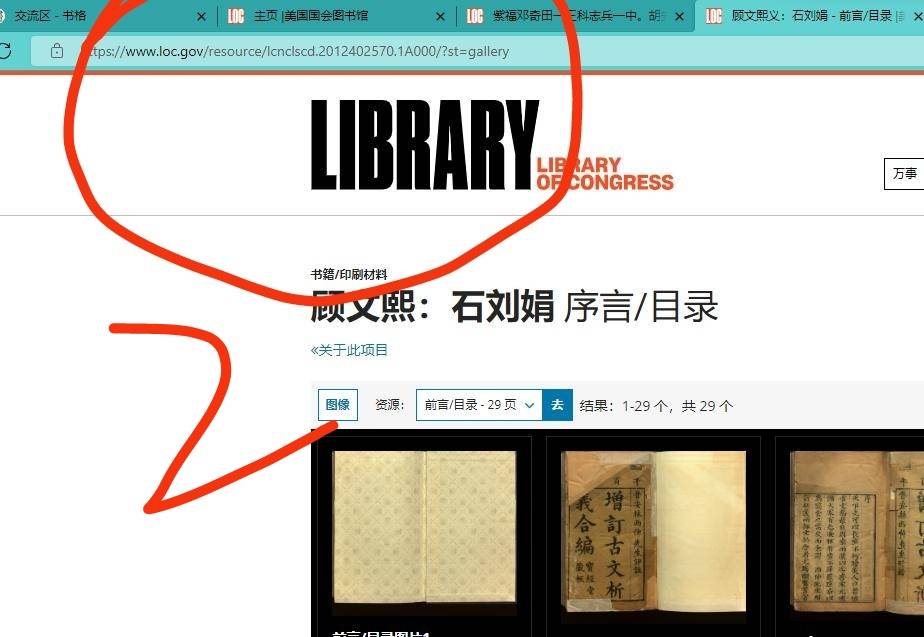
找到这个书:古文析義网址格式应该是类似这样的
https://www.loc.gov/item/2012402570/
其次,美国国会图书馆使用了防御连续访问的CDN,不走代理的情况极容易失败
书游客@未曾 #54189
好的,我去试一下
书游客@未曾 #54189
好像还是不行,未曾老师,你们一般用什么下这个图书馆的书?
xiaopengyou游客您可以搜索交流區,試試用另外一種手動批量方式,即批量取得URL,再用lDM或Motrix下載。
或供參考
未曾管理员@书 #54197
我的下载方法仅供参考
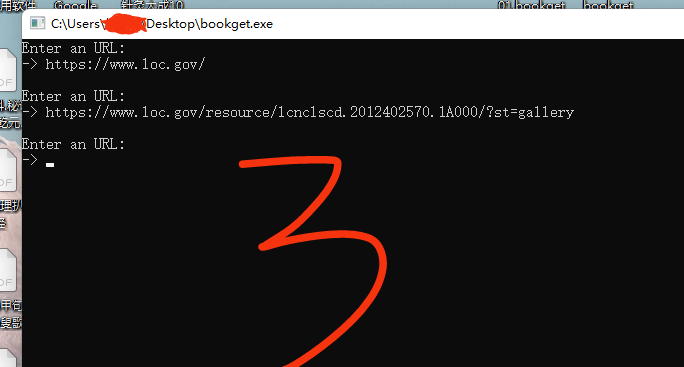
首先获取URL列表
ok.daoing.com/mggh/然后,在一台美国服务器上用脚本逐行下载这个列表的文件并转为JPG,完毕后打包
最后我从服务器上下载打包后的文件、处理。
所以重点是需要一个好的梯子
书游客@未曾 #54199
这个说好像可以处理,但我不会用,他说把URL列表粘贴过去,改成我们需要的格式,就行了,我试了一下,粘贴不了,上面哪些代码也删不了,或者是我不会用,所以很恼火,未曾老师知道这个怎么用吗?
未曾管理员@书 #54203
这个我没用过~好像不是处理这个的吧
xiaopengyou游客美國國會圖書館的古籍下載,可以參考這個帖
吃饺子不沾醋游客美国国会的我用电脑开vpn也不好使只能是手机结合时候的那个人工具获取URL然后用DMI下载
- 作者帖子
正在查看 10 个帖子:1-10 (共 10 个帖子)
正在查看 10 个帖子:1-10 (共 10 个帖子)
