- 作者帖子

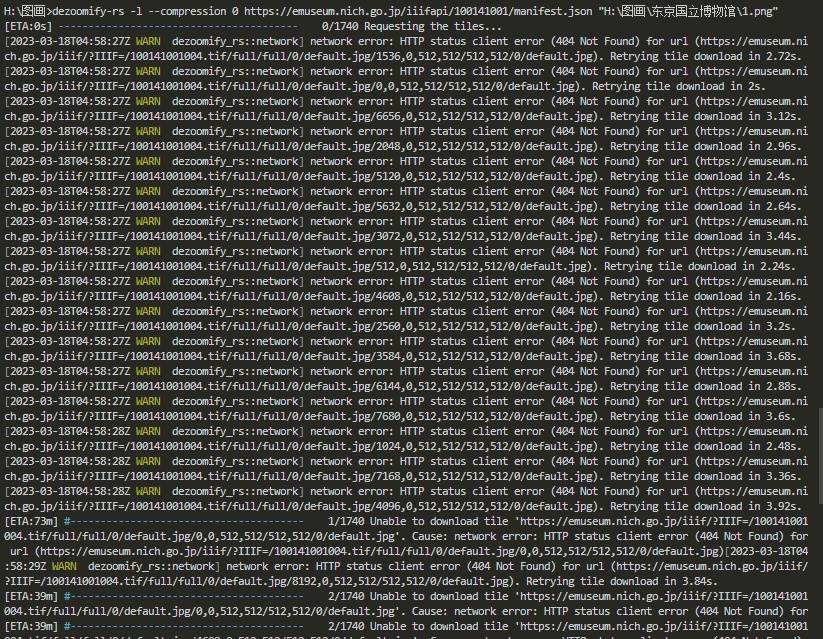
dxx游客找到图片iiif链接xxxxx/manifest.json,在浏览器用dezoomify.html下载,因为太大,等了2小时才拼好,但另存为时又要等待,等待时,可能因为内存不够了,浏览器崩溃,白忙。用IIIF下载器,没有任何提示进度,也不知道是否在下载。
如何解决?拼图好了,在另存为之前,如何在电脑里找到?或者cmd如何调用dezoomify.exe下载xxxxx/manifest.json?
谢谢!
未曾管理员为什么一直不用dezoomify-rs
dxx游客一直用cmd调用dezoomify-rs 2.9.2.exe下载,一楼省略了“-rs”。但cmd调用dezoomify-rs.exe下载manifest.json,是一大堆英文提示,反正下载不了。json改为dzi也不行。

未曾管理员@dxx #86050
他(dezoomify-rs.)那个识别manifest.json包含的单图的json信息可能有误,建议代入使用单独的图片json,格式如
https://emuseum.nich.go.jp/iiif/?IIIF=/100141001004.tif/info.json
它的自动识别的多包含了full/full/0/default.jpg/
dxx游客@未曾 #86051
膜拜大神!问下,是在100141001字符串后一律加004变成100141001004吗?
未曾管理员
Ru_Evan游客你要下载哪个嘛?我给你搞一搞。。
dxx游客@Ru_Evan #86076
谢谢你好人。这个东京的我能连上网,群主指点了,就不麻烦他人了。你能连接台北故宫博物院吗,说不定劳驾帮忙下一点
Ru_Evan游客@dxx #86091
台北故宫、北京故宫、大都会、克利夫兰等等200多家博物馆,我都下载全部图像了。。
崇鹂游客@Ru_Evan #86108
空间多大,要不要10T?
Ru_Evan游客@崇鹂 #86109
我下载的基本都是JPG图像,所有资料一个18TB硬盘装不下,,若是中国文物资料的话,大约4TB多一点,,另外还有图书馆(国会图书馆等几家)也有几个TB,,不过我这资料是收费的(微博同名),都是博物馆藏文物资料,,你们喜欢下载书籍的话,我这儿不多。。
崇鹂游客@Ru_Evan #86113
如果是书籍之外,真是浩瀚如海啊。能够把海外博物馆的器物图搜集整理回来,本身就功劳很大
Ru_Evan游客@崇鹂 #86115
其实图书馆书籍远比博物馆文物资料容易下载,,大多数图书馆大概1-2小时,最多半天就可以把所有书籍资料图像链接做成bat文件批量下载(若是IIIF平台就更容易),而博物馆就没这么容易了,有些要两三天才能搞定,文本、图像下载整合后还要分门别类,这个最花时间。。
崇鹂游客@Ru_Evan #86117
图书也只是盯着一些善本,等他放出来......但器物类的真是工程,都没人做过,哈哈,想想都要吐血。
我上次看哈佛艺术博物,有的图片就是当年从敦煌那扒下来的原壁,现在敦煌莫高窟那些位置都是空白的,我以前还以为是年久风化自己剥落去了。像这些重要器物图,都少有人提及,而且外国博物馆对中国器物类的标注展示并不是很完美,乱得很。我当时搞了一下午,主要也是脑力活动的识别判断分类,管中窥豹,深有同感。
小白游客@Ru_Evan #86117
您好!大神,請教如何把圖書舘所有書籍資料圖像鏈接做成bat文件批量下載,比如下載哈佛圖像,應該怎麼操作成bat呀?謝謝!
fanyan1026游客批量获取info.json文件 然后使用dezoomify-rs.exe批量下载
大致过程如下(以某北故宫为列):
对应类别的网址:https://digitalarchive.npm.gov.tw/List/Index?mode1=%E5%93%81%E5%90%8D%E6%AA%A2%E7%B4%A2&Page=0&PageSize=10&CurrentPage=0&IsQueryTotal=False&IsQueryBronze=False&IsQueryCeramics=False&IsQueryJade=False&IsQueryEnamel=False&IsQuerySculpture=False&IsQueryLacquerware=False&IsQueryCoin=False&IsQueryStationery=False&IsQueryMiscellaneous=False&IsQueryFabric=False&IsQuerySilkEmbroidery=True&IsQueryPainting=False&IsQueryBook=False&IsQueryPost=False&IsQueryRubbing=False&IsQueryFan=False&IsQueryRareBook=False&IsQueryDocument=False&IsQueryOther=False&Image100=False&Image600=False&flag=0&UDESC=False&UASC=True&DDESC=False&DASC=False&TDESC=False&TASC=False&ADESC=False&AASC=False
其中的Page=0&PageSize=10可以改成Page=0&PageSize=最大的数字(一次性显示所有这个类别的作品)不然网站采集器需要设置翻页
然后使用采集器就可以采集如下的地址:https://digitalarchive.npm.gov.tw/Painting/Content?pid=13668&Dept=P
然后批量改成 iiiff地址是:https://digitalarchive.npm.gov.tw/Painting/IIIFViewer?pid=13667&Dept=P
然后在采集器用iiiff地址批量采集info.json地址,采集到的是如:https://iiifod.npm.gov.tw/iiif/2/K2C/K2C000001N000000000PAD最后批量+后缀:/info.json
有些采集器采集不了的可以把Content?改成setJson?,然后用采集器采集,"service":{"@id":"https://iiifod.npm.gov.tw/iiif/2/K2C%2FK2C000001N000000000PAC","字段里的内容
最后也能得到地址
我使用的采集器是爬山虎 但是数据导出每天只能1000,操作比较简单有单独的json分析 可以直接得到地址
还有一个是是八爪鱼,就需要通过自己自定义字段采集,而且自定义之后还需要分析才能解析,多测试几次把,刚开始 我死活获取不了,预览中都获取了,任务的时候就是获取不了!
还有其他的采集器 预览的时候可以采集,到任务开始采集的时候就不行,一般都是要代理(需要专业版或者vip才可以使用)
八爪鱼我采集到1400+ 爬山虎我采集到1600+ 中间都看见有错误的 估计都有没采集到的
然后几个注意点
dezoomify-rs.exe批量代码
@echo off
set http_proxy=代理地址
set https_proxy=代理地址
setlocal enabledelayedexpansion
set /a a=1
set downdir="download"
if not exist %downdir% md %downdir%
for /f "delims=" %%i in (urls.txt) do (
dezoomify-rs -l -r 30 --accept-invalid-certs -H "User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36" %%i %downdir%/!a!.jpg
set /a a+=1
)
pause用管理员的代码修改了一下 可以正常下载
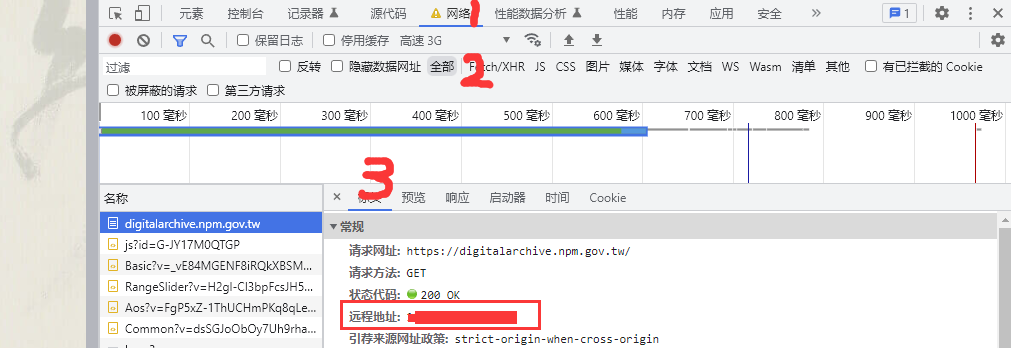
代理软件中没有地址的可以在打开网站之后f12看网站的远程地址 就是代理地址
urls.txt的编码utf8 utf32是不行的
fanyan1026游客@未曾
dxx游客@fanyan1026 #87476
请教,cmd用dezoomify-rs.exe批量下载时,如何用浏览器的代理?不是全局连接国际互联网,我只能浏览器本身连接国际互联网。
fanyan1026游客- 作者帖子
正在查看 19 个帖子:1-19 (共 19 个帖子)

正在查看 19 个帖子:1-19 (共 19 个帖子)
正在查看 19 个帖子:1-19 (共 19 个帖子)
