标签: 优质分享
- 作者帖子

摩诃游客使用 bookget.exe -i url.txt 的时候,用单线程,可以看到下载是按 url.txt 顺序下载。不过下载创建的目录名称,似乎是时间+随机数。目录名字的排序,和 url.txt 里面的顺序不完全一样。如果顺序一样的话,目录改名字就方便很多。
www.digital.archives.go.jp_468e32a4610c6118c000063094010c60000318c4
www.digital.archives.go.jp_468e32a4610c6718c000063094010c60000318c4
www.digital.archives.go.jp_468e32ac210e7318c000063094010c60000318c4
zhudw游客@摩诃 #176919
如果只是一個網站(2022年第一版)時,是按網站的圖書編號存目錄的。
隨着網站越加越多,這個工作量就會很大。
加上有些人不自覺,會把某些網站當羊毛擼,全站下載搬到自己網盤或服務器,再提供給其他人。
這導致,很多網站失效,我就再更新軟件修復。如此反復,浪費大量精力。
後來就是一刀切,省時、省力。不管目錄了,並且有意讓目錄名稱是編碼後的,非人工可識別。
工欲善其事,必先利其器。要想批量下人家網站,就讓他們學編程去吧。
六祖坛经游客最新的源码,如果直接go build编译的话,好像有问题会报错。
湛蓝游客@六祖坛经 #176936
改了编译方式,不过cmake好像一样会报错
摩诃游客@zhudw #176920
理解、赞同。谢谢一直的无私分享。
道统游客
无限游客美国国会 现在不灵,用另外的方法,ok.daoing 获得url后,下载后顺序也是乱的
小石头游客请教下,刚用最新版(25.0507)下载抗战平台的报纸图像,为啥下载的不是图档啊,如图,谢谢。

镜像之美游客@zhudw #176920
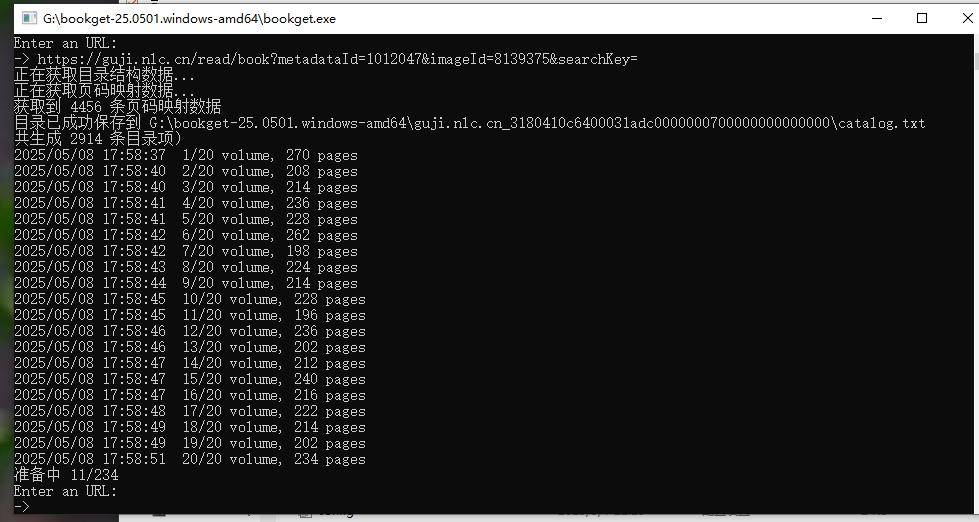
大侠好!今天25.0501已不能下载https://guji.nlc.cn/read/book?metadataId=1012047&imageId=8139375&searchKey=
用更新的25.0507下载也失败
朱元璋游客@zhudw #176920
首都图书馆也有很多重要资料放出,您是否会添加他们的下载呢?
镜像之美游客@zhudw #176920
大侠好!报告一下,更新的软件25.0507,较原25.0501增加了大量坏页,有的甚至不能下载https://guji.nlc.cn/read/book?metadataId=1012047&imageId=8139375&searchKey=
原25.0501可惜失效,界面更简洁
zhudw游客@六祖坛经 #176936
编译的makefile是给机器人用的。人工执行 make release,需要在linux下。
@无限 #176973
美国国会需要海外IP,大陆目前没有办法下载。
@道统 #176968
图片类的不在我研究范围,这类不是IIIF标准的,都是要动手能力强的人才能下。
@朱元璋 #177014
未知的事情,无法回答你。自2024年1月16日以来,好像没有新加网站了。现在是做减法,遇到失效的网站,如果不是质量特别高的,一般会考虑删除。减轻维护的负担。
@镜像之美 #177020
503 明显是对方服务器不允许下载。有些图只显示半页,是国图服务器超负载了。
@小石头 #176990
抗日战争平台本来是隐藏的,不在wiki公布名单中,刚放出来。试试今天的版本吧。
试试 25.0508 版,代码推送后,机器人已经发布了。
剔藓扫尘游客
zhudw游客@剔藓扫尘 #177035
暂时先别下 guji.nlc.cn 该站服务器超负荷。
未曾管理员@zhudw #177036
先生辛苦。
我有一个小建议,就是可以先生成一个包含分页图片URL的文件,然后下载根据这个文件下载。避免任务失败后,重新开始,每次都再去逐页获取API请求匹配链接。
当然生成的URL文件也可以方便使用其他工具下载(我一般根据url列表使用wget单任务下载)。
zhudw游客@未曾 #177138
中华古籍智慧平台,现在出现503就是下载图片的URL,它其实也是java api,从参数看是通过java读取远程ftp的文件,再返回给客户端。压力的瓶颈还是图片URL接口。查询imageID的API 还没挂。
目前在8号的版本,采用分卷下载,压力比1号的版本小一些。存 cache-urls.txt 之前也有想过,这样修改的版本还是要回到1号,一次查询完所有图片URL。
其实只要使用者避开高峰期(下午和晚上),避免同一时间大量用户同时下载,就能解决问题。如果问题严重,我再考虑写cache urls,不过还是无法解决图片服务器的压力。最终压力还在这儿。
未曾管理员
明月清风游客
雲湖的雲游客强烈建议自发出来几个热心者,协调分工下载某某图书馆的某些书,不要大伙一窝蜂各个图书馆的都去下,造成拥堵。比如张三自发下载A馆的某些书,李四下载B馆的某些书,然后上传网盘,再在交流区贴出下载链接......这样会不会好很多?至少能减少或分流一些盲目的扒书流量吧......
芥诚游客好奇试了一下 已被限制访问
trywpl游客请问:新版本双击打开,闪一下就关了,是怎么一回事?谢谢
六祖坛经游客@芥诚 #177405
什么限制访问??中华古籍智慧平台吗??
聿青游客
六祖坛经游客@聿青 #177530
那看来是下载得太狠了。
芥诚游客@六祖坛经 #177546
不是 我还没下载 今天只是试了一下 就直接封了 应该是只要用bookget就封
Creen游客电脑上一按enter键就闪退是怎么回事啊?两台电脑都这样
fwsh游客有卧底?
zhudw游客请使用 2025-05-12 以后的发布版,即从 bookget 和 bookget-gui 下载的最新版,以此项目主页发布版为准。
有防御的网站名单:
[美国]国会图书馆
[美国]哈佛大学图书馆
[中国]香港中文大学图书馆
[美国]familysearch.org 家譜圖像
[中国]中华古籍智慧服务平台全文见:github.com/dewei...ookget-gui
zhudw游客有闪退的用户,注意删除旧版所有文件。使用新版只有一个文件 bookget.exe (如果你电脑操作系统是中文用户名,或带有空格的用户名,也可能是这个原因)
Creen游客@zhudw #177671
十分感谢
天忌游客好久没用bookget,“请输入图片URL模板”是啥意思啊?国图都下载不了
还有网站的页面也有问题。其它网站都正常,就书格出现这情况。请问是什么原因
zhudw游客@天忌 #177729
用 12 日的版本,1 号的版本问题很多。
如果输入的URL不可识别,会进入图片批量模式,如需回到原来的模式,关闭软件重新打开即可。
————
书格,我这边看是正常的。可能是你访问的时候, 某些CSS文件没有加载。
大道至简游客@zhudw #177829
大佬打开bookget-gui 出现错误怎么解决
下载 的最新版
zhudw游客
书不在多少游客今天还能见到五百年前、一千年前的书,实在是我辈之幸,古籍今日仍拥有如此众多的读者,同样也是古籍之幸,非常感谢推动此次珍贵古籍高清发布的人。有点“古籍重光”的味道吧。
六祖坛经游客@zhudw #177829
05.12版本,在智慧平台上面即便下单册也不行,没下几页bookgui浏览器就不行了。
zhudw游客@六祖坛经 #177989
bookget-gui 解决的是CDN防御问题,但不能解决限IP。也不能解决
500 Internal Server Error,你们悠着点儿啊,不要逮着一只羊撸,其它站的资源不是也有么。
zhudw游客补充更新:
本文面向会一些 javascript 编程的用户,自己动手,一切皆有可能!
这个实现只需要 bookget-gui 即可完成所有功能,不需要 bookget。
全文教程看:08.bookget gui高级应用
使用示例
打开 bookget-gui 输入URL,访问你想浏览的网站,例如: https://rbook.ncl.edu.tw
此时,就像平常使用其它浏览器一样,丝毫没有差别。点击想看的图书,完成【验证码】真人验证。
当你可以看到书影的时候,软件已经开始自动下载,查看 downloads 文件夹,就可以看到图片了。
你不用操作,软件会自动翻下一页。如下图所示:
黍离游客@zhudw #178057
请问,我按照bookget-gui,下载Microsoft Visual C++运行库,安装之后,提示要修复安装,然后重启。重启后,依旧提示要修复安装。反复循环,卡在这一步了(我是win11)。我也正在小红书和B站上学习安装,但感觉遇到的问题都不一样。请问有解决办法吗?
黍离游客抱歉,不用了。我陷入了误区,以为要能打开c++运行库才行。刚刚发现bookget-gui可以正常下载(之前没用过,第一次用)。请忽略我上面一条帖子。
以前那些阻碍的人,应当判刑游客@zhudw #178057
先生好,为何我按照指点,把https://guji.nlc.cn/read/book?metadataId=1011136&imageId=7158481&searchKey= 放到gui的上面,也的确一页一页的翻,也的确在download中有,但是只有第一页显示,而其余缩略图的不显示,也打不开。
敢问,是何原因
zhudw游客@以前那些阻碍的人,应当判刑 #178073
你把不能显示的图片,改成.txt,用记事本看看里面是什么。有可能是服务器500错误。等服务器稳定再试。
古籍热爱学习者游客@zhudw #178077
文件比较大,都好几兆一个。我改成txt,是各种三角之类的乱码。
zhudw游客
古籍热爱学习者游客@zhudw #178092
多謝,看了您的圖片,一下子明白了,原來按照您的網址才是正確的。
大道至简游客
zhudw游客@大道至简 #178260
假如,一本书有1000页,你下到 500 页中断了。可以把已下载的文件,移到单独的文件夹下。
剩下的 500 页,重新翻页的时候,你可以在网页上跳转到第 500 页开始翻页。
bookget-gui 的视角:来了一张图,按顺序存下它。再来一张图,再存下它。就这样简单反复工作。它不是一个下载工具,就只是edge浏览器的马甲。
白身游客如果可以制定起始页就好了
大道至简游客@zhudw #178266
好的 谢谢大佬
zhudw游客@白身 #178269
如果你会 javascript ,我可以让 bookget-gui 支持页面加载完,执行你的脚本。
在你的脚本里面,你可以实现想要的功能,例如页面加载完,你就让它跳转到上次关闭时的页码。
至于,我为什么不写好,因为不想再造一个类似 bookget 的工具也来,那样没有意义。我一个人维护的网站有限,无法面对整个网络的图书馆,并且他们会升级的。一升级就失效,是个死循环。
- 作者帖子








 下载 的最新版
下载 的最新版




